Neste post do blog, você aprenderá como configurar o particionamento do MySQL usando os recursos existentes da comunidade. Se você deseja aprender mais sobre o particionamento de banco de dados MySQL do Zabbix, confira esta postagem do blog para um guia abrangente, abaixo.
Este guia tem a intenção de funcionar para todos os recursos MySQL mais importantes, incluindo MySQL 8, MariaDB ou outros forks MySQL. Portanto, independentemente da versão ou tipo que você estiver executando, este guia deve ser capaz de colocá-lo em funcionamento.
Sumário
- Introdução
- Como utilizar
- Particionamento do banco de dados
- Configurando o script Perl
- Uso de procedimentos armazenados
- Desativação do housekeeper Zabbix
- Conclusão
Para um guia em vídeo, confira o Zabbix no YouTube aqui: https://youtu.be/KbwIoPasMYI
Introdução
O housekeeper Zabbix não consegue limpar seus dados antigos com eficiência suficiente quando o servidor atinge um determinado tamanho, o que faz sentido. O housekeeper Zabbix é desenvolvido para percorrer seu banco de dados e procurar uma linha mais antiga que o tempo definido em seu frontend Zabbix e, em seguida, excluir essa linha. Ele precisa fazer isso para cada entrada de dados de histórico ou tendência, o que resulta em um processo com desempenho lento quando você tem um banco de dados MySQL bastante grande. Podemos ver um indicador disso acontecendo na captura de tela a seguir:
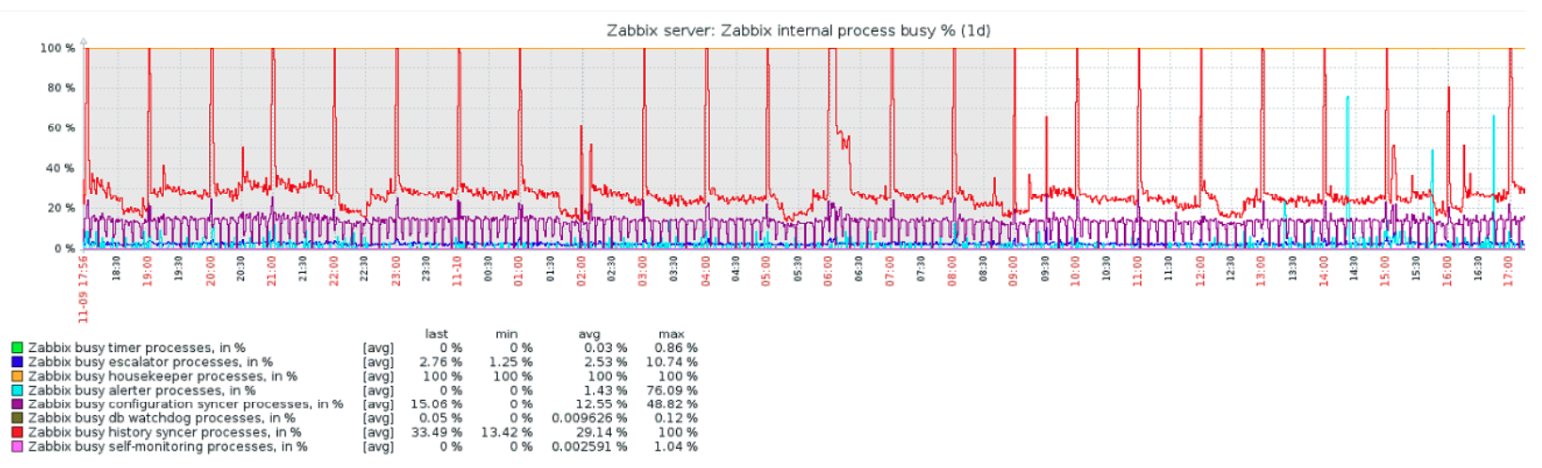
Você pode ver que seu processo de housekeeper do Zabbix estará ocupado o tempo todo e que seu banco de dados está sendo preenchido constantemente. Uma solução desenvolvida nativamente no Zabbix para PostgreSQL é o TimescaleDB, mas infelizmente não existe tal recurso nativo para o MySQL. No entanto, existe a incrível solução de particionamento do MySQL, que veremos nesta postagem.
O particionamento do MySQL é o processo de dividir seu banco de dados em pedaços baseados em tempo. Isso tornará possível descartar facilmente uma partição inteira assim que ela se tornar muito antiga, de acordo com o período de retenção da partição que especificamos. Isso é muito mais rápido do que passar pelos dados linha por linha, como o housekeeper integrado do Zabbix faz.
Então, não vamos perder mais tempo e vamos começar!
Se você está procurando um guia abrangente sobre esta e muitas outras implementações do Zabbix como esta, confira nosso livro do Zabbix aqui:
https://www.thezabbixbook.com/ch01-zabbix-components/partitioning-database/
Se você estiver interessado em mais recursos como este, confira nosso GitHub aqui:
https://github.com/OpensourceICTSolutions/
Como utilizar
Agora, para tornar tudo isso possível, precisaremos fazer login no nosso servidor de banco de dados Zabbix e particionar o banco de dados. Antes de fazer isso, tenha certeza de parar o processo do servidor Zabbix ou fazer uma cópia do seu banco de dados e particioná-lo em um servidor diferente. Se você não sabe como fazer isso, leia a documentação sobre como fazer um dump do MySQL e importar o MySQL:
https://mariadb.com/kb/en/mysqldump/
https://mariadb.com/kb/en/mariadb-import/
Qualquer que seja o método que você utilizará, SEMPRE certifique-se de fazer um backup do seu banco de dados. Embora rara, a corrupção de dados sempre é uma possibilidade ao realizar alterações em grande escala em seu banco de dados.
Para evitar que o MySQL fique sem espaço, certifique-se também de ter uma quantidade generosa de espaço livre em seu sistema. Executar o particionamento quando você tem um espaço de armazenamento lotado pode levar a dados corrompidos no banco de dados. Verifique seu espaço livre com:
df -h
Particionamento do banco de dados
Uma vez que você interrompeu seu servidor Zabbix ou uma vez que você importou seu backup de banco de dados para um servidor diferente, podemos iniciar o processo de particionamento. Antes de fazer qualquer coisa, observe que criar partições pode ser um processo MUITO demorado, consistindo em vários dias em grandes bancos de dados. Certifique-se de executar os comandos para particionamento em uma sessão tmux . Instale o tmux com:
dnf install tmux
ou em sistemas baseados em Debian
apt-get install tmux
Agora podemos emitir o comando tmux para abrir uma nova sessão tmux:
tmux
Isso abrirá um terminal para nós, que permanecerá ativo mesmo que nossa sessão SSH expire. Agora estamos prontos para particionar.
Vamos particionar as seguintes tabelas:
| Nome da tabela | Propósito | Tipo de dado |
|---|---|---|
| history | Keeps raw history | Numeric (float) |
| history_uint | Keeps raw history | Numeric (unsigned) |
| history_str | Keeps raw short string data | Character |
| history_text | Keeps raw long string data | Text |
| history_log | Keeps raw log strings | Log |
| history_bin | Keeps binary data in this table | Binary |
| trends | Keeps reduced dataset (trends) | Numeric (float) |
| trends_uint | Keeps reduced dataset (trends) | Numeric (unsigned) |
Para iniciar o particionamento, vamos fazer login no MySQL com:
mysql -u root -p
Como o particionamento é um processo baseado em tempo, precisaremos conhecer a entrada de dados mais antiga para cada uma das tabelas acima. Precisaremos emitir um comando para todos eles, então vamos fazer isso primeiro com:
SELECT FROM_UNIXTIME(MIN(clock)) FROM history_uint;
Emita o mesmo comando para todas as tabelas, alterando history_uint para o respectivo table name. Depois de emitir os comandos, anote a saída de cada uma das tabelas, pois precisaremos disso para definir nossas partições. A saída retornará um carimbo de data/hora, que será a partição mais antiga que precisamos criar. Neste exemplo, usarei o timestamp 19-12-2020, portanto exatamente 2 meses antes do momento em que escrevi este post, em 19-02-2021.
Agora, precisaremos preparar nosso comando de particionamento. Nossas tabelas history serão particionadas por dia e nossas tabelas trends serão particionadas por mês.
Então vamos começar com a nossa tabela history_uint :
ALTER TABLE history_uint PARTITION BY RANGE ( clock) (PARTITION p2020_12_19 VALUES LESS THAN (UNIX_TIMESTAMP("2020-12-20 00:00:00")) ENGINE = InnoDB, PARTITION p2020_12_20 VALUES LESS THAN (UNIX_TIMESTAMP("2020-12-21 00:00:00")) ENGINE = InnoDB, PARTITION p2020_12_21 VALUES LESS THAN (UNIX_TIMESTAMP("2020-12-22 00:00:00")) ENGINE = InnoDB, PARTITION p2020_12_22 VALUES LESS THAN (UNIX_TIMESTAMP("2020-12-23 00:00:00")) ENGINE = InnoDB, … PARTITION p2021_02_18 VALUES LESS THAN (UNIX_TIMESTAMP("2021-02-19 00:00:00")) ENGINE = InnoDB, PARTITION p2021_02_19 VALUES LESS THAN (UNIX_TIMESTAMP("2021-02-20 00:00:00")) ENGINE = InnoDB, PARTITION p2021_02_20 VALUES LESS THAN (UNIX_TIMESTAMP("2021-02-21 00:00:00")) ENGINE = InnoDB, PARTITION p2021_02_21 VALUES LESS THAN (UNIX_TIMESTAMP("2021-02-22 00:00:00")) ENGINE = InnoDB, PARTITION p2021_02_22 VALUES LESS THAN (UNIX_TIMESTAMP("2021-02-23 00:00:00")) ENGINE = InnoDB);
Certifique-se de adicionar uma partição para cada dia – é isso que as reticências significam aqui (…)
Você pode ver que usamos nosso carimbo de data/hora mais antigo de 19-12-2020 para definir nossa primeira partição. Nossa última partição está um pouco no futuro, terminando em 22-12-2020. É assim que definimos nosso intervalo de partições. Certifique-se de fazer a mesma coisa usando seu próprio timestamp que você coletou na primeira etapa após fazer login no MySQL. Tenha isso em mente! Isso pode ser diferente para cada tabela.
Aplique o mesmo processo a cada uma das suas tabelas history antes de prosseguir para as tabelas trends . Dica: Faça uma nota de texto para preparar todos os comandos usando o guia antes de executar qualquer coisa. Isso facilita muito esse procedimento.
Para nossas tabelas trends, ainda trabalharemos com o timestamp coletado de 19-12-2020. Basicamente, o que queremos são todos os dados do mês de dezembro de 2020 para cima. As instruções de partição ficarão assim para a tabela trends_uint :
ALTER TABLE trends_uint PARTITION BY RANGE ( clock)
(PARTITION p2020_10 VALUES LESS THAN (UNIX_TIMESTAMP("2020-11-01 00:00:00")) ENGINE = InnoDB,
PARTITION p2020_11 VALUES LESS THAN (UNIX_TIMESTAMP("2020-12-01 00:00:00")) ENGINE = InnoDB,
PARTITION p2020_12 VALUES LESS THAN (UNIX_TIMESTAMP("2021-01-01 00:00:00")) ENGINE = InnoDB,
PARTITION p2021_01 VALUES LESS THAN (UNIX_TIMESTAMP("2021-02-01 00:00:00")) ENGINE = InnoDB,
PARTITION p2021_02 VALUES LESS THAN (UNIX_TIMESTAMP("2021-03-01 00:00:00")) ENGINE = InnoDB,
PARTITION p2021_03 VALUES LESS THAN (UNIX_TIMESTAMP("2021-04-01 00:00:00")) ENGINE = InnoDB);
Como você pode ver, aqui estamos particionando por mês em vez de por dia, o que faz sentido no caso das nossas tabelas trends . Não se esqueça de fazer isso para todas as nossas tabelas trends , que são as tabelas trends e trends_uint usando seu respectivo timestamp coletado.
Depois de preparar este comando de consulta MySQL para cada tabela, agora você pode colocá-los em seu terminal MySQL tabela por tabela. Por favor, não se esqueça de usar o comando tmux como mencionado anteriormente e de ter um pouco de paciência, pois isso pode levar alguns dias por tabela para bancos de dados maiores, e é por isso que eu sempre recomendo configurar o particionamento ANTES de ativar uma nova configuração do Zabbix.
Configuração do script Perl
Apesar disso, particionar não é tudo; ainda precisamos manter a configuração particionada. O MySQL não criará novas partições para nós automaticamente; precisamos automatizar isso. A melhor maneira de fazer isso é usando o script Perl disponível publicamente. Não temos certeza de quem escreveu este aqui, mas você pode encontrá-lo em nosso repositório GitHub:
https://github.com/OpensourceICTSolutions/zabbix-mysql-partitioning-perl
Baixe o script do nosso GitHub e salve-o em seu servidor de banco de dados Zabbix na seguinte pasta:
/usr/lib/zabbix/
Em seguida, torne o script executável com:
chmod 750 /usr/lib/zabbix/mysql_zbx_part.pl
Em seguida, precisamos editá-lo com o comando a seguir (sim, você também pode usar nano):
vim /usr/lib/zabbix/mysql_zbx_part.pl
Há algumas linhas aqui que queremos editar. Primeiro, nossos detalhes do MySQL/login:
my $dsn = 'DBI:mysql:'.$db_schema.':mysql_socket=/var/lib/mysql/mysql.sock'; my $db_user_name = 'zabbix'; my $db_password = 'password';
Altere-os para seu respectivo uso no seu servidor. O nome de usuário e a senha podem (por exemplo) ser as mesmas credenciais que você especificou no arquivo de configuração do servidor Zabbix.
Em segundo lugar, precisamos editar a quantidade de tempo para a qual queremos salvar nossos dados. Ela é definida nas linhas a seguir:
my $tables = { 'history' => { 'period' => 'day', 'keep_history' => '60'},
'history_log' => { 'period' => 'day', 'keep_history' => '60'},
'history_str' => { 'period' => 'day', 'keep_history' => '60'},
'history_text' => { 'period' => 'day', 'keep_history' => '60'},
'history_uint' => { 'period' => 'day', 'keep_history' => '60'},
'history_bin' => { 'period' => 'day', 'keep_history' => '60'},
'trends' => { 'period' => 'month', 'keep_history' => '12'},
'trends_uint' => { 'period' => 'month', 'keep_history' => '12'},
Terceiro, altere o fuso horário para o fuso horário configurado em seu servidor do banco de dados Zabbix. Estamos localizados na Holanda, então usamos Europa/Amsterdã (Europe/Amsterdam).
my $curr_tz = 'Europe/Amsterdam';
No script também temos algumas linhas que podem ter que ser comentadas/descomentadas caso você esteja usando uma instalação MySQL mais antiga ou mais recente. Se você estiver usando MySQL 5.5 e anteriores ou MySQL 8.x e posteriores, certifique-se de comentar as seguintes linhas a partir de # MySQL 5.6 + MariaDB
# my $sth = $dbh->prepare(qq{SELECT plugin_status FROM information_schema.plugins WHERE plugin_name = 'partition'});
#
# $sth->execute();
#
# my $row = $sth->fetchrow_array();
#
# $sth->finish();
# return 1 if $row eq 'ACTIVE';
#
Descomente o seguinte para MySQL 5.5, começando em #MySQL 5.5
# my $sth = $dbh->prepare(qq{SELECT variable_value FROM information_schema.global_variables WHERE variable_name = 'have_partitioning'});
#return 1 if $row eq 'YES';
#
Se você quiser usar o script com o MySQL 8 ou posterior, descomente o seguinte a partir de # MySQL 8.x (NOT MariaDB!)
# MySQL 8.x (NOT MariaDB!)
# my $sth = $dbh->prepare(qq{select version();});
# $sth->execute();
# my $row = $sth->fetchrow_array();
# $sth->finish();
# return 1 if $row >= 8;
#
Tenha em mente: APENAS faça isso se você estiver usando MySQL 5.5 e anteriores ou MySQL 8.x e posteriores. Se você estiver com MySQL 5.6 ou MariaDB NÃO altere essas linhas.
Para Zabbix 5.4 e versões MAIS ANTIGAS , também certifique-se de descomentar a linha a seguir. No entanto, não faça isso para o Zabbix 6.0 e posteriores:
# $dbh->do("DELETE FROM auditlog_details WHERE NOT EXISTS (SELECT NULL FROM auditlog WHERE auditlog.auditid = auditlog_details.auditid)");
Para Zabbix 6.4 e versões ANTERIORES, também certifique-se de comentar a seguinte linha. No entanto, não faça isso para o Zabbix 7.0 e versões superiores:
'history_bin' => { 'period' => 'day', 'keep_history' => '60'},
Por padrão, definimos um período de 60 dias para as tabelas history e 12 meses para as tabelas trends . Altere esses valores para seu período de tempo preferido. Tenha em mente que, quanto mais tempo armazenarmos History e Trends, maior será nosso banco de dados.
Agora vamos adicionar um cronjob com:
crontab -e
Em seguida, adicione a seguinte linha:
55 22 * * * /usr/lib/zabbix/mysql_zbx_part.pl >/dev/null 2>&1
Também precisamos instalar algumas dependências Perl com:
dnf install perl-DateTime perl-Sys-Syslog
ou em sistemas baseados em Debian
apt-get install libdatetime-perl liblogger-syslog-perl
E é isso! Agora você está pronto e configurou o particionamento do MySQL. Poderíamos executar o script manualmente com:
perl /usr/lib/zabbix/mysql_zbx_part.pl
Então podemos verificar e ver se funcionou com:
journalctl -t mysql_zbx_part
Isso lhe dará uma lista de partições criadas e excluídas, caso você tenha feito tudo certo.
Uso de Procedimentos Armazenados
Observe que: Você pode pular esta parte se tiver usado o script Perl na etapa anterior.
Usar procedimentos armazenados do MySQL é outra maneira de garantir que nossas partições de banco de dados sejam criadas e excluídas. Deixe-me começar dizendo que este método NÃO É RECOMENDADO e deve ser usado apenas por organizações que não permitem o uso de scripts externos. É um método de difícil manutenção e, quando quebra, pode causar uma verdadeira dor de cabeça.
No entanto, na Opensource ICT Solutions acreditamos na flexibilidade e no fornecimento de soluções diferentes, e existe a opção de fazê-lo. Então, veja como:
Primeiro, precisamos fazer login no MySQL com:
mysql -u root -p
Então, precisamos criar nossa tabela para gerenciar nossas partições, com:
CREATE TABLE manage_partitions ( tablename VARCHAR(64) NOT NULL COMMENT ‘Table name’, period VARCHAR(64) NOT NULL COMMENT ‘Period - daily or monthly’, keep_history INT(3) UNSIGNED NOT NULL DEFAULT ‘1’ COMMENT ‘For how many days or months to keep the partitions’, last_updated DATETIME DEFAULT NULL COMMENT ‘When a partition was added last time’,comments VARCHAR(128) DEFAULT ‘1’ COMMENT ‘Comments’, PRIMARY KEY (tablename) ) ENGINE=INNODB;
Com isso, podemos criar nossas informações de histórico com:
INSERT INTO manage_partitions (tablename, period, keep_history, last_updated, comments) VALUES (‘history’, ‘day’, 60, now(), ‘’); INSERT INTO manage_partitions (tablename, period, keep_history, last_updated, comments) VALUES (‘history_uint’, ‘day’, 60, now(), ‘’); INSERT INTO manage_partitions (tablename, period, keep_history, last_updated, comments) VALUES (‘history_str’, ‘day’, 60, now(), ‘’); INSERT INTO manage_partitions (tablename, period, keep_history, last_updated, comments) VALUES (‘history_text’, ‘day’, 60, now(), ‘’); INSERT INTO manage_partitions (tablename, period, keep_history, last_updated, comments) VALUES (‘history_log’, ‘day’, 60, now(), ‘’); INSERT INTO manage_partitions (tablename, period, keep_history, last_updated, comments) VALUES (‘trends’, ‘month’, 12, now(), ‘’); INSERT INTO manage_partitions (tablename, period, keep_history, last_updated, comments) VALUES (‘trends_uint’, ‘month’, 12, now(), ‘’);
Por padrão, definimos um período de 60 dias para as tabelas history e 12 meses para as tabelas trends . Altere isso de acordo com a sua preferência.
Agora, precisamos adicionar algumas tarefas do MySQL para gerenciar nossas partições. Primeiro, adicionaremos a tarefa para verificar a existência de uma partição necessária:
DELIMITER $$ USE zabbix$$ DROP PROCEDURE IF EXISTS create_next_partitions$$ CREATE PROCEDURE create_next_partitions(IN_SCHEMANAME VARCHAR(64))BEGINDECLARE TABLENAME_TMP VARCHAR(64);DECLARE PERIOD_TMP VARCHAR(12);DECLARE DONE INT DEFAULT 0; DECLARE get_prt_tables CURSOR FOR SELECT `tablename`, `period` FROM manage_partitions; DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = 1; OPEN get_prt_tables; loop_create_part: LOOP IF DONE THEN LEAVE loop_create_part; END IF; FETCH get_prt_tables INTO TABLENAME_TMP, PERIOD_TMP; CASE WHEN PERIOD_TMP = 'day' THEN CALL `create_partition_by_day`(IN_SCHEMANAME, TABLENAME_TMP); WHEN PERIOD_TMP = 'month' THEN CALL `create_partition_by_month`(IN_SCHEMANAME, TABLENAME_TMP); ELSE BEGIN ITERATE loop_create_part; END; END CASE; UPDATE manage_partitions set last_updated = NOW() WHERE tablename = TABLENAME_TMP; END LOOP loop_create_part; CLOSE get_prt_tables; END$$ DELIMITER ;
Agora, podemos adicionar a tarefa para criar partições por dia:
DELIMITER $$
USE zabbix$$
DROP PROCEDURE IF EXISTS create_partition_by_day$$
CREATE PROCEDURE create_partition_by_day(IN_SCHEMANAME VARCHAR(64), IN_TABLENAME VARCHAR(64))BEGINDECLARE ROWS_CNT INT UNSIGNED;DECLARE BEGINTIME TIMESTAMP;DECLARE ENDTIME INT UNSIGNED;DECLARE PARTITIONNAME VARCHAR(16);SET BEGINTIME = DATE(NOW()) + INTERVAL 1 DAY;SET PARTITIONNAME = DATE_FORMAT( BEGINTIME, ‘p%Y_%m_%d’ );
SET ENDTIME = UNIX_TIMESTAMP(BEGINTIME + INTERVAL 1 DAY);
SELECT COUNT(*) INTO ROWS_CNT
FROM information_schema.partitions
WHERE table_schema = IN_SCHEMANAME AND table_name = IN_TABLENAME AND partition_name = PARTITIONNAME;
IF ROWS_CNT = 0 THEN
SET @SQL = CONCAT( 'ALTER TABLE `', IN_SCHEMANAME, '`.`', IN_TABLENAME, '`',
' ADD PARTITION (PARTITION ', PARTITIONNAME, ' VALUES LESS THAN (', ENDTIME, '));' );
PREPARE STMT FROM @SQL;
EXECUTE STMT;
DEALLOCATE PREPARE STMT;
ELSE
SELECT CONCAT("partition `", PARTITIONNAME, "` for table `",IN_SCHEMANAME, ".", IN_TABLENAME, "` already exists") AS result;
END IF;
END$$
DELIMITER ;
Também precisaremos de uma tarefa para criar partições por mês:
DELIMITER $$
USE zabbix$$
DROP PROCEDURE IF EXISTS create_partition_by_month$$
CREATE PROCEDURE create_partition_by_month(IN_SCHEMANAME VARCHAR(64), IN_TABLENAME VARCHAR(64))BEGINDECLARE ROWS_CNT INT UNSIGNED;DECLARE BEGINTIME TIMESTAMP;DECLARE ENDTIME INT UNSIGNED;DECLARE PARTITIONNAME VARCHAR(16);SET BEGINTIME = DATE(NOW() - INTERVAL DAY(NOW()) DAY + INTERVAL 1 DAY + INTERVAL 1 MONTH);SET PARTITIONNAME = DATE_FORMAT( BEGINTIME, ‘p%Y_%m’ );
SET ENDTIME = UNIX_TIMESTAMP(BEGINTIME + INTERVAL 1 MONTH);
SELECT COUNT(*) INTO ROWS_CNT
FROM information_schema.partitions
WHERE table_schema = IN_SCHEMANAME AND table_name = IN_TABLENAME AND partition_name = PARTITIONNAME;
IF ROWS_CNT = 0 THEN
SET @SQL = CONCAT( 'ALTER TABLE `', IN_SCHEMANAME, '`.`', IN_TABLENAME, '`',
' ADD PARTITION (PARTITION ', PARTITIONNAME, ' VALUES LESS THAN (', ENDTIME, '));' );
PREPARE STMT FROM @SQL;
EXECUTE STMT;
DEALLOCATE PREPARE STMT;
ELSE
SELECT CONCAT("partition `", PARTITIONNAME, "` for table `",IN_SCHEMANAME, ".", IN_TABLENAME, "` already exists") AS result;
END IF;
END$$
DELIMITER ;
Em seguida, também uma tarefa para verificar e excluir partições antigas:
DELIMITER $$ USE zabbix$$ DROP PROCEDURE IF EXISTS drop_partitions$$ CREATE PROCEDURE drop_partitions(IN_SCHEMANAME VARCHAR(64))BEGINDECLARE TABLENAME_TMP VARCHAR(64);DECLARE PARTITIONNAME_TMP VARCHAR(64);DECLARE VALUES_LESS_TMP INT;DECLARE PERIOD_TMP VARCHAR(12);DECLARE KEEP_HISTORY_TMP INT;DECLARE KEEP_HISTORY_BEFORE INT;DECLARE DONE INT DEFAULT 0;DECLARE get_partitions CURSOR FORSELECT p.table_name, p.partition_name, LTRIM(RTRIM(p.partition_description)), mp.period, mp.keep_historyFROM information_schema.partitions pJOIN manage_partitions mp ON mp.tablename = p.table_nameWHERE p.table_schema = IN_SCHEMANAMEORDER BY p.table_name, p.subpartition_ordinal_position; DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = 1; OPEN get_partitions; loop_check_prt: LOOP IF DONE THEN LEAVE loop_check_prt; END IF; FETCH get_partitions INTO TABLENAME_TMP, PARTITIONNAME_TMP, VALUES_LESS_TMP, PERIOD_TMP, KEEP_HISTORY_TMP; CASE WHEN PERIOD_TMP = 'day' THEN SET KEEP_HISTORY_BEFORE = UNIX_TIMESTAMP(DATE(NOW() - INTERVAL KEEP_HISTORY_TMP DAY)); WHEN PERIOD_TMP = 'month' THEN SET KEEP_HISTORY_BEFORE = UNIX_TIMESTAMP(DATE(NOW() - INTERVAL KEEP_HISTORY_TMP MONTH - INTERVAL DAY(NOW())-1 DAY)); ELSE BEGIN ITERATE loop_check_prt; END; END CASE; IF KEEP_HISTORY_BEFORE >= VALUES_LESS_TMP THEN CALL drop_old_partition(IN_SCHEMANAME, TABLENAME_TMP, PARTITIONNAME_TMP); END IF; END LOOP loop_check_prt; CLOSE get_partitions; END$$ DELIMITER ;
Por último, mas não menos importante, uma tarefa para excluir partições designadas:
DELIMITER $$
USE zabbix$$
DROP PROCEDURE IF EXISTS drop_old_partition$$
CREATE PROCEDURE drop_old_partition(IN_SCHEMANAME VARCHAR(64), IN_TABLENAME VARCHAR(64), IN_PARTITIONNAME VARCHAR(64))BEGINDECLARE ROWS_CNT INT UNSIGNED;
SELECT COUNT(*) INTO ROWS_CNT
FROM information_schema.partitions
WHERE table_schema = IN_SCHEMANAME AND table_name = IN_TABLENAME AND partition_name = IN_PARTITIONNAME;
IF ROWS_CNT = 1 THEN
SET @SQL = CONCAT( 'ALTER TABLE `', IN_SCHEMANAME, '`.`', IN_TABLENAME, '`',
' DROP PARTITION ', IN_PARTITIONNAME, ';' );
PREPARE STMT FROM @SQL;
EXECUTE STMT;
DEALLOCATE PREPARE STMT;
ELSE
SELECT CONCAT("partition `", IN_PARTITIONNAME, "` for table `", IN_SCHEMANAME, ".", IN_TABLENAME, "` not exists") AS result;
END IF;
END$$
DELIMITER ;DELIMITER $$
USE zabbix$$
DROP PROCEDURE IF EXISTS drop_old_partition$$
CREATE PROCEDURE drop_old_partition(IN_SCHEMANAME VARCHAR(64), IN_TABLENAME VARCHAR(64), IN_PARTITIONNAME VARCHAR(64))BEGINDECLARE ROWS_CNT INT UNSIGNED;
SELECT COUNT(*) INTO ROWS_CNT
FROM information_schema.partitions
WHERE table_schema = IN_SCHEMANAME AND table_name = IN_TABLENAME AND partition_name = IN_PARTITIONNAME;
IF ROWS_CNT = 1 THEN
SET @SQL = CONCAT( 'ALTER TABLE `', IN_SCHEMANAME, '`.`', IN_TABLENAME, '`',
' DROP PARTITION ', IN_PARTITIONNAME, ';' );
PREPARE STMT FROM @SQL;
EXECUTE STMT;
DEALLOCATE PREPARE STMT;
ELSE
SELECT CONCAT("partition `", IN_PARTITIONNAME, "` for table `", IN_SCHEMANAME, ".", IN_TABLENAME, "` not exists") AS result;
END IF;
END$$
DELIMITER ;
Agora vamos adicionar um agendador de eventos para executar tudo isso:
DELIMITER $$ USE zabbix$$ CREATE EVENT IF NOT EXISTS e_part_manage ON SCHEDULE EVERY 1 DAYSTARTS ‘2021-02-19 04:00:00’ ON COMPLETION PRESERVE ENABLE COMMENT ‘Creating and dropping partitions’ DO BEGIN CALL zabbix.drop_partitions(‘zabbix’); CALL zabbix.create_next_partitions(‘zabbix’); END$$ DELIMITER ;
E isso é tudo para procedimentos armazenados. Muito fácil, uma vez que você conheça todos os comandos a executar.
Desativação do housekeeper Zabbix
Depois de particionar e configurar o script Perl ou os Procedimentos Armazenados, precisamos ter certeza de desabilitar o housekeeper do Zabbix para as tabelas History e Trends. Navegue até o frontend do Zabbix e vá para Administration | Housekeeping.
Certifique-se de que Enable internal housekeeping esteja desligado para History e Trends desta forma:
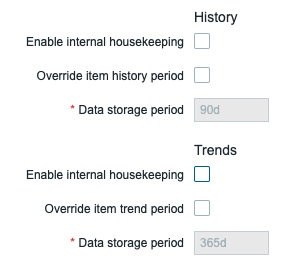
O script Perl ou os Procedimentos Armazenados assumirão o processo de exclusão de dados e qualquer configuração de housekeeping definida em itens para History e Trends não afetará mais a retenção de dados.
Conclusão
O particionamento do MySQL pode parecer uma tarefa ousada e, com certeza, pode ser. No passado, as primeiras postagens de membros da comunidade Zabbix possibilitaram que os usuários do Zabbix configurassem o particionamento. Ao longo do tempo, essas postagens foram perdidas, então sentimos que era nossa tarefa garantir que haja um guia público disponível para que você faça essa tarefa muito importante.
Depois de configurar tudo isso, fique de olho em suas partições por alguns dias, pois você pode ter esquecido alguma coisa e elas não estão sendo criadas.
Espero que você tenha gostado de ler esta postagem no blog e se tiver alguma dúvida ou precisar de ajuda para configurar qualquer coisa na configuração do Zabbix, sinta-se à vontade para entrar em contato comigo e com a equipe da Opensource ICT Solutions.
Nathan Liefting
![]()
Problemas comuns
- Pode ser que você veja o erro: Table has no partition for value <unixtime>
1.1: Se <unixtime> está no futuro, verifique se a sua partição mais nova corresponde ao valor mais recente presente em cada tabela com:
SELECT FROM_UNIXTIME(MAX(clock)) FROM history_uint;
1.2: Se <unixtime> está no passado, verifique se a sua partição mais antiga corresponde ao valor mais antigo presente em cada tabela com:
SELECT FROM_UNIXTIME(MIN(clock)) FROM history_uint;