




本文讲述如何使用现有开源社区资源完成MySQL数据库分区。如果你想深入了解关于Zabbix MySQL数据库分区的更多知识,欢迎阅读下文。
本文内容适用于所有主要的MySQL版本,包括MySQL 8、MariaDB以及其他MySQL分支版本。因此不管你使用何种版本,本文都可以帮到你。
目录
- 概述
- 如何实现
- 数据库分区
- 设置Perl脚本
- 使用存储过程
- 禁用Zabbix housekeeper
- 总结
如需本文的视频版本,可以访问 Zabbix YouTube English:https://youtube/KbwloPasMYI
概述
一旦你的Zabbix服务达到一定规模,Zabbix自身的housekeeper功能就无法有效地清理过期数据。这是因为Zabbix的housekeeper功能需要从数据库中查找每一行过期的数据记录并删除它,过期时间的判断规则遵从Zabbix前端页面的设置。housekeeper需要逐个搜索每一条历史数据记录和趋势数据记录,这在MySQL数据库规模很大的情况无疑会导致性能差、速度慢。当此种情况发生时,housekeeper的性能表现有可能如下图所示(持续100%繁忙)。

你会发现Zabbix housekeeper进程持续地100%繁忙,并且数据库的数据量不断地增长。对于PostgreSQL数据库,Zabbix提供了内置的解决方案——即TimescaleDB,但是对于MySQL数据库Zabbix并没有提供类似的解决方案。不过幸好有一种非常有效的解决方案可以通过MySQL数据库分区实现,本文下面就对此进行讲解。
MySQL分区是以时间为单位将数据拆分为一系列的块(chunk)。这样一来,一旦某个块中的数据过期(超出设定的保留时长),就可以非常方便地直接将整个块删掉。相较于逐个查找数据记录,这种删除块的操作要快速得多。
现在我们开始动手试一下吧!
如果你想获取与本文有关或者类似的更多Zabbix实践,欢迎阅读我们的Zabbix书籍:
https://www.thezabbixbook.com/ch01-zabbix-components/partitioning-database/
如果你想获取与本文类似的更多资源,请访问我们的GitHub:
https://github.com/OpensourceICTSolutions/
如何实现
要实现上述方案,我们需要登录Zabbix数据库并进行分区。在此之前,请确保已经停止Zabbix服务进程,或者将数据库复制到另一台服务器上进行分区。如果你不清楚如何复制数据库,可以查阅以下关于MySQL dump和MySQL导入的文档:
https://mariadb.com/kb/en/mysqldump/
https://mariadb.com/kb/en/mariadb-import/
不管使用哪种方法,请一定备份你的数据库。虽然不常见,但是在数据库上执行大规模修改时发生数据损坏并不是不可能。
为了避免在分区过程中出现MySQL存储空间不足的情况,请确保有充足的剩余空间。如果分区过程中出现空间已满的情况,可能会导致数据损坏。使用以下命令查看剩余空间:
df -h
数据库分区
一旦停止了Zabbix服务进程或者已经将数据库复制到了另一台服务器上,我们就可以开始分区了。在开始分区之前我们要注意,创建分区可能是非常耗时的一个过程,在大型数据库上甚至需要几天时间。所以,一定要使用tmux来运行分区命令。安装tmux:
dnf install tmux
或者在Debian系统中
apt-get install tmux
现在,我们可以运行tmux命令来打开一个tmux会话:
tmux
该命令会打开一个终端,即使在ssh会话超时的情况下,这个终端也不会关闭。现在我们开始分区。
我们将对以下表进行分区:
| 表名 | 作用 | 数据类型 |
| history | 存储原始的历史数据 | 数字(浮点数) |
| history_uint | 存储原始的历史数据 | 数字(无符号) |
| history_str | 存储原始的短字符串数据 | 字符型 |
| history_text | 存储原始的长字符串数据 | 文本 |
| history_log | 存储原始的日志字符串数据 | 日志 |
| history_bin | 在此表中存储二进制数据 | 二进制 |
|---|---|---|
| trends | 存储每小时统计数据(趋势) | 数字(浮点数) |
| trends_uint | 保持每小时统计数据(趋势) | 数字(无符号) |
使用以下命令登录MySQL以开始进行分区:
mysql -u root -p
因为分区是基于时间的,所以我们需要知道每个表中时间戳最小的数据记录。我们需要为每个表执行一个SQL语句,首先是:
SELECT FROM_UNIXTIME(MIN(clock)) FROM history_uint;
为每个表执行以上语句,执行时将history_uint修改为对应的表名。执行语句后记下每个表的返回结果,在后面定义分区时需要用到。返回结果是一个时间戳,该时间戳是我们需要创建的最早的分区。在此示例中,我将使用2020-12-19,正好是作者撰写本文时间(2021-02-19)再往前两个月。
现在我们需要准备分区语句了。我们的历史(history)表按天进行分区,趋势(trends)表按月进行分区。
我们从history_uint表开始:
ALTER TABLE history_uint PARTITION BY RANGE ( clock)
(PARTITION p2020_12_19 VALUES LESS THAN (UNIX_TIMESTAMP("2020-12-20 00:00:00")) ENGINE = InnoDB,
PARTITION p2020_12_20 VALUES LESS THAN (UNIX_TIMESTAMP("2020-12-21 00:00:00")) ENGINE = InnoDB,
PARTITION p2020_12_21 VALUES LESS THAN (UNIX_TIMESTAMP("2020-12-22 00:00:00")) ENGINE = InnoDB,
PARTITION p2020_12_22 VALUES LESS THAN (UNIX_TIMESTAMP("2020-12-23 00:00:00")) ENGINE = InnoDB,
…
PARTITION p2021_02_18 VALUES LESS THAN (UNIX_TIMESTAMP("2021-02-19 00:00:00")) ENGINE = InnoDB,
PARTITION p2021_02_19 VALUES LESS THAN (UNIX_TIMESTAMP("2021-02-20 00:00:00")) ENGINE = InnoDB,
PARTITION p2021_02_20 VALUES LESS THAN (UNIX_TIMESTAMP("2021-02-21 00:00:00")) ENGINE = InnoDB,
PARTITION p2021_02_21 VALUES LESS THAN (UNIX_TIMESTAMP("2021-02-22 00:00:00")) ENGINE = InnoDB,
PARTITION p2021_02_22 VALUES LESS THAN (UNIX_TIMESTAMP("2021-02-23 00:00:00")) ENGINE = InnoDB);
请确保每天添加一个分区——上面的语句中省略了部分日期(省略号位置)。
你会看到我们使用了最早时间戳,也就是2020-12-19,来定义第一个分区。而最后一个分区的时间是2021-02-22,比当前时间(2021-02-19)往后3天。这就是我们定义分区范围的方式。请确保使用你自己的时间戳定义分区,也就是在第一步执行的SQL语句中获取的时间戳。请注意,有可能每个表的时间戳是不同的。
你需要为每个历史数据表准备相同的语句,然后再为趋势表准备语句。提示:在执行任何操作之前先写下本文中使用的所有命令,这将使操作过程更方便一些。
对于趋势表,我们仍然使用第一步获取的时间戳,即2020-12-19。所以,我们需要处理的是2020年12月及以后的所有数据。trends_uint表的分区语句如下所示:
ALTER TABLE trends_uint PARTITION BY RANGE ( clock)
(PARTITION p2020_10 VALUES LESS THAN (UNIX_TIMESTAMP("2020-11-01 00:00:00")) ENGINE = InnoDB,
PARTITION p2020_11 VALUES LESS THAN (UNIX_TIMESTAMP("2020-12-01 00:00:00")) ENGINE = InnoDB,
PARTITION p2020_12 VALUES LESS THAN (UNIX_TIMESTAMP("2021-01-01 00:00:00")) ENGINE = InnoDB,
PARTITION p2021_01 VALUES LESS THAN (UNIX_TIMESTAMP("2021-02-01 00:00:00")) ENGINE = InnoDB,
PARTITION p2021_02 VALUES LESS THAN (UNIX_TIMESTAMP("2021-03-01 00:00:00")) ENGINE = InnoDB,
PARTITION p2021_03 VALUES LESS THAN (UNIX_TIMESTAMP("2021-04-01 00:00:00")) ENGINE = InnoDB);
可见,这里我们按月而不是按天进行分区,这种分区方式更适合于趋势表。别忘了对所有趋势表,也就是trends表和trends_uint表,进行同样的操作,使用的时间戳同样是第一步时你获取的时间戳。
至此,我们已经为每个表准备好了MySQL语句,可以将其复制到MySQL终端去执行了(每次只执行一个表)。别忘了使用前面提到的tmux命令,还要有一些耐心,对于较大的数据库,每个表可能需要几天时间。这就是为什么我总是建议在一开始上线Zabbix的时候就进行分区,而不是等到数据量很大时。
设置Perl脚本
仅仅设置分区是不够的,我们还需要维护分区设置。MySQL不会自动为我们创建新分区,我们需要自己将这一过程自动化。最好的方法是使用已公开的Perl脚本。我们不确定其作者是谁,但是你可以在我们的GitHub库中找到它:
https://github.com/OpensourceICTSolutions/zabbix-mysql-partitioning-perl
从我们的GitHub下载该脚本,并将其保存到Zabbix数据库服务器的以下文件夹中:
/usr/lib/zabbix/
然后给脚本赋予执行权限:
chmod 750 /usr/lib/zabbix/mysql_zbx_part.pl
接下来,我们需要使用以下命令对其进行编辑(当然你也可以使用nano,而非vim):
vim /usr/lib/zabbix/mysql_zbx_part.pl
有几行语句需要修改。首先是MySQL登录信息:
my $dsn = 'DBI:mysql:'.$db_schema.':mysql_socket=/var/lib/mysql/mysql.sock'; my $db_user_name = 'zabbix'; my $db_password = 'password';
按照你的服务器情况对其进行修改。例如,用户名和密码可能要与Zabbix服务器配置文件中的设置保持一致。
其次,我们需要编辑数据的保存时长,可以在以下的行中修改:
my $tables = { 'history' => { 'period' => 'day', 'keep_history' => '60'},
'history_log' => { 'period' => 'day', 'keep_history' => '60'},
'history_str' => { 'period' => 'day', 'keep_history' => '60'},
'history_text' => { 'period' => 'day', 'keep_history' => '60'},
'history_uint' => { 'period' => 'day', 'keep_history' => '60'},
'history_bin' => { 'period' => 'day', 'keep_history' => '60'},
'trends' => { 'period' => 'month', 'keep_history' => '12'},
'trends_uint' => { 'period' => 'month', 'keep_history' => '12'},
第三,将时区修改为Zabbix数据库服务器系统所设置的时区。因为我们在荷兰,所以将时区设置为Europe/Amsterdam:
my $curr_tz = 'Europe/Amsterdam';
如果你使用的是比较旧的或者比较新的MySQL版本,脚本中的某些行可能需要注释掉或者取消注释。如果你使用的是MySQL 5.5及其以前的版本,或者MySQL 8.x及其以后的版本,你需要将下面的行注释掉,这些行在# MySQL 5.6 + MariaDB下面。
# my $sth = $dbh->prepare(qq{SELECT plugin_status FROM information_schema.plugins WHERE plugin_name = 'partition'});
#
# $sth->execute();
#
# my $row = $sth->fetchrow_array();
#
# $sth->finish();
# return 1 if $row eq 'ACTIVE';
#
如果你使用的是MySQL 5.5,你需要将下面的行取消注释,这些行在# MySQL 5.5下面。
# my $sth = $dbh->prepare(qq{SELECT variable_value FROM information_schema.global_variables WHERE variable_name = 'have_partitioning'});
#return 1 if $row eq 'YES';
#
如果你要在MySQL 8以及更高版本中使用该脚本,请从# MySQL 8.x (NOT MariaDB!)开始取消注释以下内容。
# MySQL 8.x (NOT MariaDB!)
# my $sth = $dbh->prepare(qq{select version();});
# $sth->execute();
# my $row = $sth->fetchrow_array();
# $sth->finish();
# return 1 if $row >= 8;
#
请注意,只有当你使用MySQL 5.5以及更低版本或者MySQL 8.x以及更高版本时才需要进行上面的所有这些修改。如果你使用的是MySQL 5.6或者MariaDB,就不需要进行任何修改。
对于Zabbix 5.4以及更低的版本,还需要取消注释下面的一行(对Zabbix 6.0以及更高版本不需要进行此操作):
# $dbh->do("DELETE FROM auditlog_details WHERE NOT EXISTS (SELECT NULL FROM auditlog WHERE auditlog.auditid = auditlog_details.auditid)");
对于 Zabbix 6.4 及更早版本,还请确保注释掉以下行。但不要对 Zabbix 7.0 及更高版本执行此操作:
'history_bin' => { 'period' => 'day', 'keep_history' => '60'},
该脚本默认将历史表数据保留时间设定为60天,将趋势表数据保留时间设定为12个月。你可以将其修改为自己喜欢的时间长度。不过请注意,保留历史数据和趋势数据的时间越长,数据库就会越大。
现在,我们添加一个定时任务:
crontab -e
然后在定时任务中添加下面的行
55 22 * * * /usr/lib/zabbix/mysql_zbx_part.pl >/dev/null 2>&1
我们还需要使用下面的命令安装一些Perl依赖项:
dnf install perl-DateTime perl-Sys-Syslog
如果是基于Debian的系统,则执行:
apt-get install libdatetime-perl liblogger-syslog-perl
好了!现在你已经完成了整个MySQL分区配置。我们可以手动执行一下Perl脚本:
perl /usr/lib/zabbix/mysql_zbx_part.pl
然后可以通过下面的命令查看其是否有效:
journalctl -t mysql_zbx_part
如果操作无误,该命令应该返回创建和删除的分区列表。
使用存储过程
请注意,如果你已经在使用上述的Perl脚本,那么你可以跳过这一部分。
自动创建和删除数据库分区的另一种方法是使用MySQL存储过程。不过作者不推荐使用此方法,这一方法应该只用于那些不允许使用外部脚本的企业。这是一种难以排查故障的方法,一旦出现故障会很头疼。
尽管如此,在Opensource ICT Solutions公司我们相信灵活性的价值并且提供多样性的解决方案。显然我们可以选择这样做。所以现在开始吧。
首先,我们需要使用以下命令登录MySQL:
mysql -u root -p
然后,我们需要创建一个表来管理分区,创建语句如下:
CREATE TABLE manage_partitions ( tablename VARCHAR(64) NOT NULL COMMENT ‘Table name’, period VARCHAR(64) NOT NULL COMMENT ‘Period - daily or monthly’, keep_history INT(3) UNSIGNED NOT NULL DEFAULT ‘1’ COMMENT ‘For how many days or months to keep the partitions’, last_updated DATETIME DEFAULT NULL COMMENT ‘When a partition was added last time’,comments VARCHAR(128) DEFAULT ‘1’ COMMENT ‘Comments’, PRIMARY KEY (tablename) ) ENGINE=INNODB;
然后,我们可以向表中插入所需的数据保留时间信息:
INSERT INTO manage_partitions (tablename, period, keep_history, last_updated, comments) VALUES (‘history’, ‘day’, 60, now(), ‘’); INSERT INTO manage_partitions (tablename, period, keep_history, last_updated, comments) VALUES (‘history_uint’, ‘day’, 60, now(), ‘’); INSERT INTO manage_partitions (tablename, period, keep_history, last_updated, comments) VALUES (‘history_str’, ‘day’, 60, now(), ‘’); INSERT INTO manage_partitions (tablename, period, keep_history, last_updated, comments) VALUES (‘history_text’, ‘day’, 60, now(), ‘’); INSERT INTO manage_partitions (tablename, period, keep_history, last_updated, comments) VALUES (‘history_log’, ‘day’, 60, now(), ‘’); INSERT INTO manage_partitions (tablename, period, keep_history, last_updated, comments) VALUES (‘trends’, ‘month’, 12, now(), ‘’); INSERT INTO manage_partitions (tablename, period, keep_history, last_updated, comments) VALUES (‘trends_uint’, ‘month’, 12, now(), ‘’);
我们默认将历史表数据保留时间设定为60天,将趋势表数据保留时间设定为12个月。如有需要,请根据自己的情况修改。
现在我们需要添加一些MySQL存储过程来管理我们的分区。首先,我们添加一个按天创建分区的存储过程:
DELIMITER $$
USE zabbix$$
DROP PROCEDURE IF EXISTS create_partition_by_day$$
CREATE PROCEDURE create_partition_by_day(IN_SCHEMANAME VARCHAR(64), IN_TABLENAME VARCHAR(64))BEGINDECLARE ROWS_CNT INT UNSIGNED;DECLARE BEGINTIME TIMESTAMP;DECLARE ENDTIME INT UNSIGNED;DECLARE PARTITIONNAME VARCHAR(16);SET BEGINTIME = DATE(NOW()) + INTERVAL 1 DAY;SET PARTITIONNAME = DATE_FORMAT( BEGINTIME, ‘p%Y_%m_%d’ );
SET ENDTIME = UNIX_TIMESTAMP(BEGINTIME + INTERVAL 1 DAY);
SELECT COUNT(*) INTO ROWS_CNT
FROM information_schema.partitions
WHERE table_schema = IN_SCHEMANAME AND table_name = IN_TABLENAME AND partition_name = PARTITIONNAME;
IF ROWS_CNT = 0 THEN
SET @SQL = CONCAT( 'ALTER TABLE `', IN_SCHEMANAME, '`.`', IN_TABLENAME, '`',
' ADD PARTITION (PARTITION ', PARTITIONNAME, ' VALUES LESS THAN (', ENDTIME, '));' );
PREPARE STMT FROM @SQL;
EXECUTE STMT;
DEALLOCATE PREPARE STMT;
ELSE
SELECT CONCAT("partition `", PARTITIONNAME, "` for table `",IN_SCHEMANAME, ".", IN_TABLENAME, "` already exists") AS result;
END IF;
END$$
DELIMITER ;
然后再添加一个按月创建分区的存储过程,语句如下:
DELIMITER $$
USE zabbix$$
DROP PROCEDURE IF EXISTS create_partition_by_month$$
CREATE PROCEDURE create_partition_by_month(IN_SCHEMANAME VARCHAR(64), IN_TABLENAME VARCHAR(64))BEGINDECLARE ROWS_CNT INT UNSIGNED;DECLARE BEGINTIME TIMESTAMP;DECLARE ENDTIME INT UNSIGNED;DECLARE PARTITIONNAME VARCHAR(16);SET BEGINTIME = DATE(NOW() - INTERVAL DAY(NOW()) DAY + INTERVAL 1 DAY + INTERVAL 1 MONTH);SET PARTITIONNAME = DATE_FORMAT( BEGINTIME, ‘p%Y_%m’ );
SET ENDTIME = UNIX_TIMESTAMP(BEGINTIME + INTERVAL 1 MONTH);
SELECT COUNT(*) INTO ROWS_CNT
FROM information_schema.partitions
WHERE table_schema = IN_SCHEMANAME AND table_name = IN_TABLENAME AND partition_name = PARTITIONNAME;
IF ROWS_CNT = 0 THEN
SET @SQL = CONCAT( 'ALTER TABLE `', IN_SCHEMANAME, '`.`', IN_TABLENAME, '`',
' ADD PARTITION (PARTITION ', PARTITIONNAME, ' VALUES LESS THAN (', ENDTIME, '));' );
PREPARE STMT FROM @SQL;
EXECUTE STMT;
DEALLOCATE PREPARE STMT;
ELSE
SELECT CONCAT("partition `", PARTITIONNAME, "` for table `",IN_SCHEMANAME, ".", IN_TABLENAME, "` already exists") AS result;
END IF;
END$$
DELIMITER ;
现在,通过调用上面的两个存储过程,我们可以添加一个为所有表(历史表和趋势表)创建分区的存储过程,具体语句如下:
DELIMITER $$ USE zabbix$$ DROP PROCEDURE IF EXISTS create_next_partitions$$ CREATE PROCEDURE create_next_partitions(IN_SCHEMANAME VARCHAR(64))BEGINDECLARE TABLENAME_TMP VARCHAR(64);DECLARE PERIOD_TMP VARCHAR(12);DECLARE DONE INT DEFAULT 0; DECLARE get_prt_tables CURSOR FOR SELECT `tablename`, `period` FROM manage_partitions; DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = 1; OPEN get_prt_tables; loop_create_part: LOOP IF DONE THEN LEAVE loop_create_part; END IF; FETCH get_prt_tables INTO TABLENAME_TMP, PERIOD_TMP; CASE WHEN PERIOD_TMP = 'day' THEN CALL `create_partition_by_day`(IN_SCHEMANAME, TABLENAME_TMP); WHEN PERIOD_TMP = 'month' THEN CALL `create_partition_by_month`(IN_SCHEMANAME, TABLENAME_TMP); ELSE BEGIN ITERATE loop_create_part; END; END CASE; UPDATE manage_partitions set last_updated = NOW() WHERE tablename = TABLENAME_TMP; END LOOP loop_create_part; CLOSE get_prt_tables; END$$ DELIMITER ;
除了分区的创建,我们还需要添加用于删除分区的存储过程。先添加一个删除指定分区的存储过程,如下:
DELIMITER $$
USE zabbix$$
DROP PROCEDURE IF EXISTS drop_old_partition$$
CREATE PROCEDURE drop_old_partition(IN_SCHEMANAME VARCHAR(64), IN_TABLENAME VARCHAR(64), IN_PARTITIONNAME VARCHAR(64))BEGINDECLARE ROWS_CNT INT UNSIGNED;
SELECT COUNT(*) INTO ROWS_CNT
FROM information_schema.partitions
WHERE table_schema = IN_SCHEMANAME AND table_name = IN_TABLENAME AND partition_name = IN_PARTITIONNAME;
IF ROWS_CNT = 1 THEN
SET @SQL = CONCAT( 'ALTER TABLE `', IN_SCHEMANAME, '`.`', IN_TABLENAME, '`',
' DROP PARTITION ', IN_PARTITIONNAME, ';' );
PREPARE STMT FROM @SQL;
EXECUTE STMT;
DEALLOCATE PREPARE STMT;
ELSE
SELECT CONCAT("partition `", IN_PARTITIONNAME, "` for table `", IN_SCHEMANAME, ".", IN_TABLENAME, "` not exists") AS result;
END IF;
END$$
DELIMITER ;
然后基于前一个存储过程,我们添加一个用于为所有表删除分区的存储过程:
DELIMITER $$ USE zabbix$$ DROP PROCEDURE IF EXISTS drop_partitions$$ CREATE PROCEDURE drop_partitions(IN_SCHEMANAME VARCHAR(64)) BEGIN DECLARE TABLENAME_TMP VARCHAR(64); DECLARE PARTITIONNAME_TMP VARCHAR(64); DECLARE VALUES_LESS_TMP INT; DECLARE PERIOD_TMP VARCHAR(12); DECLARE KEEP_HISTORY_TMP INT; DECLARE KEEP_HISTORY_BEFORE INT; DECLARE DONE INT DEFAULT 0; DECLARE get_partitions CURSOR FOR SELECT p.table_name, p.partition_name, LTRIM(RTRIM(p.partition_description)), mp.period, mp.keep_history FROM information_schema.partitions p JOIN manage_partitions mp ON mp.tablename = p.table_name WHERE p.table_schema = IN_SCHEMANAME ORDER BY p.table_name, p.subpartition_ordinal_position; DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = 1; OPEN get_partitions; loop_check_prt: LOOP IF DONE THEN LEAVE loop_check_prt; END IF; FETCH get_partitions INTO TABLENAME_TMP, PARTITIONNAME_TMP, VALUES_LESS_TMP, PERIOD_TMP, KEEP_HISTORY_TMP; CASE WHEN PERIOD_TMP = 'day' THEN SET KEEP_HISTORY_BEFORE = UNIX_TIMESTAMP(DATE(NOW() - INTERVAL KEEP_HISTORY_TMP DAY)); WHEN PERIOD_TMP = 'month' THEN SET KEEP_HISTORY_BEFORE = UNIX_TIMESTAMP(DATE(NOW() - INTERVAL KEEP_HISTORY_TMP MONTH - INTERVAL DAY(NOW())-1 DAY)); ELSE BEGIN ITERATE loop_check_prt; END; END CASE; IF KEEP_HISTORY_BEFORE >= VALUES_LESS_TMP THEN CALL drop_old_partition(IN_SCHEMANAME, TABLENAME_TMP, PARTITIONNAME_TMP); END IF; END LOOP loop_check_prt; CLOSE get_partitions; END$$ DELIMITER ;
最后,我们需要添加一个EVENT调度器来自动执行删除和创建分区的所有操作:
DELIMITER $$ USE zabbix$$ CREATE EVENT IF NOT EXISTS e_part_manage ON SCHEDULE EVERY 1 DAYSTARTS ‘2021-02-19 04:00:00’ ON COMPLETION PRESERVE ENABLE COMMENT ‘Creating and dropping partitions’ DO BEGIN CALL zabbix.drop_partitions(‘zabbix’); CALL zabbix.create_next_partitions(‘zabbix’); END$$ DELIMITER ;
这就是存储过程方法,简单易懂。
禁用Zabbix housekeeper
在进行了分区并部署了Perl脚本或者存储过程之后,我们需要禁用历史表和趋势表的housekeeper功能。在Zabbix Web前端打开Administartion | Housekeeping页面,确保将历史表和趋势表下的Enable internal housekeeping选项关闭,如下图所示:
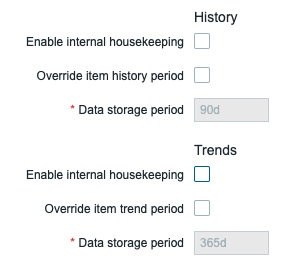
Perl脚本或者存储过程将接管删除数据的工作,并且,在各监控项中设置的历史数据和趋势数据保留时间将不再起作用。
结论
MySQL分区看上去是一项大胆的行动,但是绝对可以做。在Zabbix社区成员发布的早期贴子中已经有帮助用户设置分区的内容。随着时间推移,这些帖子已经消失不见,所以我们认为自己有责任建立一个公开的手册,以随时可以帮助大家完成这项非常重要的任务。
完成所有设置以后,请务必在前几天留意观察你的分区情况,因为有可能你忽略了一些东西导致没有创建成功。
希望您喜欢阅读本文,如果您在Zabbix设置管理方面有任何问题或者需要任何帮助,请随时联系我和Opensource ICT Soluctions团队。
Nathan Liefting
![]()
翻译:鲍光亚,《深入理解Zabbix监控系统》作者,更多图书信息请访问以下链接
纸书:https://item.jd.com/13204768.html
Kindle版: https://www.amazon.cn/dp/B092VT9949/ref=cm_sw_em_r_mt_dp_NNVTE0EZ31AXNNH67NZA
常见问题:
- 你可能遇到这样的错误:Table has no partition for value <unixtime>
- 如果<unixtime>是一个未来时间,请使用下面的语句检查最新分区与表中的最大时间戳是否匹配:
SELECT FROM_UNIXTIME(MAX(clock)) FROM history_uint;
-
- 如果<unixtime>是一个过去的时间,请使用下面的语句检查最老分区与表中的最小时间戳是否匹配:
SELECT FROM_UNIXTIME(MIN(clock)) FROM history_uint;
