El Low-Level Discovery (LLD) es una de las características más importantes de Zabbix para crear sistemas de monitorización escalables y de fácil mantenimiento. Si bien Zabbix permite la creación manual de elementos para equipos de red, servidores Windows y Linux o servicios específicos, este enfoque se vuelve rápidamente poco práctico en entornos de mayor tamaño.
La creación manual de elementos funciona perfectamente para escenarios específicos. Por ejemplo, es posible definir métricas fijas para una interfaz concreta o un servicio específico del sistema operativo. El problema surge al considerar la escalabilidad y la replicación.
Pero imagina un dispositivo de red con 48 interfaces. Si cada interfaz requiere:
- Con 9 itens, será necesario crear 432 itens manualmente;
- Con 18 itens, la cantidad aumenta a 864 itens.
¿Es este modelo sostenible a largo plazo? ¿Y cómo se gestionaría el mantenimiento de todos estos elementos?
El mismo escenario se repite en los servidores. Los servicios, discos, interfaces y particiones tendrían que crearse y mantenerse manualmente. El resultado son altos costos operativos, más trabajo repetitivo y una arquitectura de monitoreo menos eficiente.
Precisamente para eliminar este trabajo repetitivo existe LLD. Gracias a él, Zabbix puede descubrir automáticamente los recursos del entorno y crear dinámicamente los elementos, disparadores y gráficos necesarios, lo que hace que la monitorización sea más automatizada, estandarizada y fácil de gestionar.
A continuación, analizaremos con más detalle cómo funciona la monitorización jerárquica con LLD y cómo implementarla correctamente en Zabbix.
¿Qué es el Low-Level Discovery?
El Low-Level Discovery (LLD, por sus siglas en inglés) es un tipo de configuración en Zabbix que permite la creación automática de elementos, triggers, gráficos e incluso hosts, basándose en una configuración de descubrimiento a través de SNMP, HTTP, scripts externos, entre otras opciones.
Con LLD, Zabbix puede iniciar automáticamente la monitorización de interfaces o servicios de red, creando disparadores y gráficos sin necesidad de crear manualmente elementos para cada sistema de archivos o interfaz. LLD también permite crear hosts de hipervisor, como VMware o Proxmox, desde vCenter, y monitorizar máquinas virtuales e hipervisores.
LLD utiliza el protocolo JSON como formato de datos.
SNMP
[
{
"{#SNMPINDEX}": "1",
"{#IFNAME}": "vmnic0",
"{#IFDESCR}": "Device vmnic0 at 43:00.0 bnxtnet",
"{#IFTYPE}": "6",
"{#IFOPERSTATUS}": "1",
"{#IFADMINSTATUS}": "1",
"{#IFDEVDES}": "CPU Pkg/ID/Node: 0/0/0 Intel(R) Xeon(R) Silver 4314 CPU @ 2.40G"
},
{
"{#SNMPINDEX}": "2",
"{#IFNAME}": "vmnic1",
"{#IFDESCR}": "Device vmnic1 at 43:00.1 bnxtnet",
"{#IFTYPE}": "6",
"{#IFOPERSTATUS}": "1",
"{#IFADMINSTATUS}": "1",
"{#IFDEVDES}": "CPU Pkg/ID/Node: 0/1/0 Intel(R) Xeon(R) Silver 4314 CPU @ 2.40G"
},
{
"{#SNMPINDEX}": "3",
"{#IFNAME}": "vmnic2",
"{#IFDESCR}": "Device vmnic2 at 72:00.0 ntg3",
"{#IFTYPE}": "6",
"{#IFOPERSTATUS}": "2",
"{#IFADMINSTATUS}": "1",
"{#IFDEVDES}": "CPU Pkg/ID/Node: 0/2/0 Intel(R) Xeon(R) Silver 4314 CPU @ 2.40G"
}
]
HTTP
[
{
"database": "db1",
"created_at": "2024-02-01T12:30:00Z",
"encoding": "UTF8",
"tablespaces": [
{
"name": "ts1",
"max_size": "10GB"
},
{
"name": "ts2",
"max_size": "20GB"
},
{
"name": "ts3",
"max_size": "15GB"
}
]
},
{
"database": "db2",
"created_at": "2023-11-15T08:45:00Z",
"encoding": "UTF16",
"tablespaces": [
{
"name": "ts1",
"max_size": "5GB"
},
{
"name": "ts2",
"max_size": "25GB"
},
{
"name": "ts3",
"max_size": "30GB"
}
]
}
]
Por lo tanto, independientemente de cómo se estructure el descubrimiento, es necesario respetar y adherirse al protocolo JSON.
Desde la versión 4.2 de Zabbix, ya no se espera que el objeto «data» devuelto por LLD contenga el formato JSON. Por lo tanto, LLD puede aceptar un JSON normal, que contiene solo un array, y también puede realizar nuevas funciones como el preprocesamiento de valores de item (elementos) y rutas personalizadas, entre otras posibilidades.
Tras estos cambios, LLD puede extraer automáticamente el valor de la clave y asignarlo a una macro, por ejemplo, usando {#MACRO} = $.key. Las nuevas comprobaciones utilizan este método sin necesidad de incluir el elemento «data».
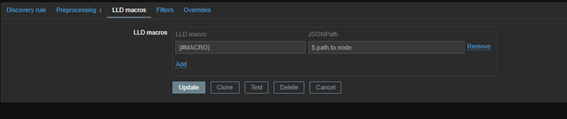
Con la función de macros LLD, podemos asignar cualquier clave del JSON a una macro en el proceso de descubrimiento. Esto será útil para crear elementos, triggers, gráficos y etiquetas. También podemos usar macros en filtros y anulaciones.
Monitoreo jerárquico
A continuación, presentamos los elementos que componen un sistema de monitorización jerárquico.
Hosts
Imagina que el equipo de operaciones solicita monitorizar, mediante Zabbix, un entorno VMware compuesto por 200 máquinas virtuales y 6 hipervisores. Esta monitorización es crucial para la finalización de un proyecto crítico, y el equipo dispone de tan solo 3 días para registrar y validar todo.
La idea inicial sería utilizar la API de Zabbix combinada con automatización en Python u otro lenguaje. Sin embargo, Zabbix ya ofrece una función extremadamente eficiente: la monitorización nativa de VMware, capaz de descubrir y registrar automáticamente hipervisores y máquinas virtuales desde un único host configurado.
El trabajo inicial del equipo consiste en revisar y personalizar las plantillas oficiales de VMware, ajustándolas al escenario necesario, ya sea añadiendo o eliminando métricas, cambiando la gravedad de los triggers, creando nuevos elementos, entre otros ajustes.
Con tus credenciales de VMware y la URL de vCenter, simplemente crea el host en Zabbix, asocia la plantilla correspondiente y deja que el Low-Level Discovery (LLD) haga el resto. En pocos minutos, Zabbix identifica todo el entorno y crea automáticamente los hosts correspondientes, eliminando la necesidad de registro manual.
Este es solo un ejemplo de la eficiencia de crear hosts mediante LLD. Este mismo enfoque se puede aplicar a otros escenarios, como controladores Wi-Fi de fabricantes como Cisco, Huawei, UniFi, Aruba y muchos otros, lo que permite el descubrimiento automático de puntos de acceso, interfaces, radios y otros componentes.
Itens
Con el Low-Level Discovery (LLD), es posible crear elementos de prácticamente cualquier tipo, automatizando rutinas y logrando una monitorización mucho más inteligente, estandarizada y dinámica. Entre los tipos de elementos que se pueden descubrir automáticamente se incluyen sistemas de archivos, interfaces de red, servicios, volúmenes, instancias y muchos otros.
Podemos asignar cualquier clave del JSON a una macro en el proceso de descubrimiento. Esto será útil para crear elementos, triggers, gráficos y etiquetas. También podemos usar macros en filtros y anulaciones.
Además, al crear elementos mediante LLD, Zabbix aplica lógica interna para decidir cuándo crear, actualizar, deshabilitar o eliminar elementos automáticamente, según:
- Filtros (aceptar o descartar descubrimientos según reglas);
- Anulaciones (anulaciones condicionales de las propiedades de los elementos);
- Cambios detectados en el entorno.
De esta forma, la monitorización se mantiene coherente con la realidad, reduciendo el trabajo manual, eliminando errores y garantizando la escalabilidad para entornos grandes y dinámicos.
Triggers
Los triggers generados mediante LLD se configuran dentro de la misma regla de descubrimiento utilizada para los elementos. La lógica de creación es idéntica a la de los triggers tradicionales: utilizan las mismas funciones, expresiones y operadores de Zabbix. La principal diferencia radica en la expresión, que normalmente utiliza macros de descubrimiento para referenciar dinámicamente los elementos creados.
Por ejemplo, al monitorizar el uso del sistema de archivos, un trigger LLD podría usar la macro {#FSNAME} para identificar cada volumen individualmente. Por lo tanto, una expresión como:
{Template vFS: vfs.fs.size[{#FSNAME},pfree].last()} < 20
Esto podría representar la regla: «Activar una alerta si el volumen detectado tiene menos del 20% de espacio libre».
Los triggers LLD se pueden configurar para:
- Se creará habilitado o solo se detectará (permaneciendo deshabilitado inicialmente);
- Recibirá etiquetas específicas;
- Seguirá los estándares de gravedad definidos en el prototipo.
Además, los triggers detectados también se pueden modificar mediante anulaciones, lo que permite realizar ajustes precisos como:
- Modificar los niveles de gravedad según criterios específicos;
- Activar o desactivar ciertos desencadenantes;
- Añadir o eliminar etiquetas;
- Personalizar expresiones según patrones predefinidos.
De esta forma, el uso de triggers mediante LLD garantiza la automatización, la coherencia y la escalabilidad, realizando un seguimiento dinámico de cualquier cambio en el entorno monitorizado.
Exemplos práticos de Low-Level Discovery
Descubrimiento de interfaces de red
Para crear un sistema automatizado de monitorización de interfaces de red, siga estos pasos:
Cree un descubrimiento en la lista de descubrimientos que contenga:
- Nombre: Network interfaces Discovery;
- Tipo: SNMP Agent;
- Key: net.if.discoverySNMP OID = discovery[{#IFOPERSTATUS},1.3.6.1.2.1.2.2.1.8,{#IFADMINSTATUS},1.3.6.1.2.1.2.2.1.7,{#IFALIAS},1.3.6.1.2.1.31.1.1.1.18,{#IFNAME},1.3.6.1.2.1.31.1.1.1.1,{#IFDESCR},1.3.6.1.2.1.2.2.1.2,{#IFTYPE},1.3.6.1.2.1.2.2.1.3];
- Update interval: 1h ou 1d;
- Eliminar recursos perdidos: cuántos días después de que LLD ya no encuentre el elemento, los triggers y los gráficos.
- Eliminar recursos perdidos: cuántos días después de que LLD ya no encuentre el elemento, los activadores y los gráficos
- Si introduce 1d, se eliminará en 1 día; 30d, en treinta días; y 0d, se eliminará inmediatamente.
- Deshabilitar funciones perdidas: Esta nueva opción permite deshabilitar elementos, garantizando que no haya elementos no compatibles ni alertas innecesarias en el entorno. Hay 3 opciones: Nunca, Inmediatamente y Después.
- Descripción: Introduzca una breve descripción de qué es LLD.
Ejemplo de Discovery:
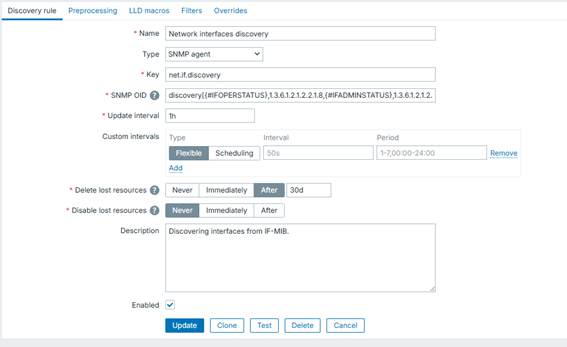
Cuando se configura correctamente, este descubrimiento devolverá algo como:
{
"{#SNMPINDEX}": "9",
"{#IFOPERSTATUS}": "1",
"{#IFADMINSTATUS}": "1",
"{#IFALIAS}": AP_192.168.16.200",
"{#IFNAME}": "Gi1/0/1",
"{#IFDESCR}": "GigabitEthernet1/0/1",
"{#IFTYPE}": "6",
"{#IFTRUNK}": "2"
},
{
"{#SNMPINDEX}": "10",
"{#IFOPERSTATUS}": "1",
"{#IFADMINSTATUS}": "1",
"{#IFALIAS}": "AP_192.168.16.199",
"{#IFNAME}": "Gi1/0/2",
"{#IFDESCR}": "GigabitEthernet1/0/2",
"{#IFTYPE}": "6",
"{#IFTRUNK}": "1"
},
{
"{#SNMPINDEX}": "11",
"{#IFOPERSTATUS}": "1",
"{#IFADMINSTATUS}": "1",
"{#IFALIAS}": "DVR 192.168.0.100",
"{#IFNAME}": "Gi1/0/3",
"{#IFDESCR}": "GigabitEthernet1/0/3",
"{#IFTYPE}": "6",
"{#IFTRUNK}": "2"
}
Tenga en cuenta que siempre se devolverá un objeto JSON, como se mencionó anteriormente. Este objeto contiene las macros que se pueden usar para crear filtros, nombres de elementos, triggers y gráficos.
Continuemos con el ejemplo.
En la sección de prototipos de itens, acceda y cree uno nuevo, siguiendo los parámetros que se indican a continuación:
- Nombre: ingrese el nombre, como por ejemplo Interface {#IFNAME}({#IFALIAS}): Bits received (observe el uso de macros);
- Tipo: en ese caso, SNMP Agent;
- Clave: Identificador de hasta 2048 caracteres. Debe ser único; utilice macros. En este caso, utilice: net.if.in[ifHCInOctets.{#SNMPINDEX}];
- Tipo de información: qué tipo de datos se almacenarán en la base de datos de Zabbix, como número (entero o decimal), carácter, registro, texto o binario. En este ejemplo: Entero;
- OID SNMP: corresponde al árbol OID, donde se encuentra la siguiente información: 1.3.6.1.2.1.31.1.1.1.6.{#SNMPINDEX};
- Unidades: Para las interfaces de red, utilice bps; Zabbix realizará la conversión a bytes por segundo. (1024 -> 1 KBps);
- Intervalo de actualización: el intervalo en el que Zabbix consulta al equipo de red para obtener el valor que se está transmitiendo, haciendo referencia al OID. En este ejemplo, 3m;
- Antecedentes: Tenemos dos opciones: «No almacenar» o «Almacenar hasta»;
- No almacenar: el valor no se guardará en la base de datos;
- Almacenar hasta: especifique la duración del almacenamiento para el historial detallado y sin procesar en la base de datos. En este ejemplo, utilizaremos 7 días, 7d;
- Tendencias: tenemos las opciones «No almacenar» o «Almacenar hasta»;
- No almacenar: el valor no se guardará en la base de datos.
- Almacenar hasta: especifique la duración del almacenamiento para las tendencias, que es el historial agregado, incluido el cálculo de los valores mínimo, promedio y máximo, contados cada hora.
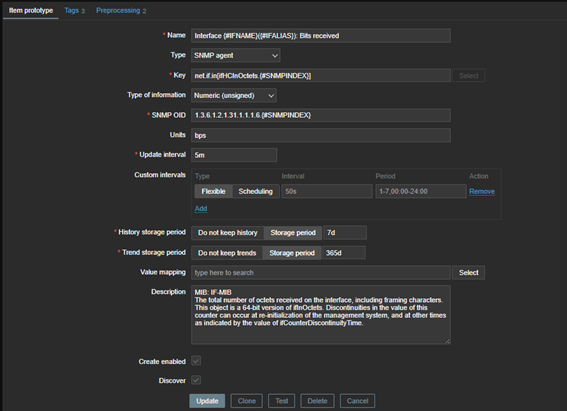
Dado que este es un elemento que cambia cada pocos segundos, configúrelo en la etapa de preprocesamiento:
- Cambios por segundo;
- Multiplicador personalizado: 8.

Con esta configuración, Zabbix podrá crear tantos elementos de interfaz del tipo ´bits recibidos´ como existan en el equipo monitorizado.
Detección del sistema de archivos
Para crear una regla de detección automatizada del sistema de archivos, podemos utilizar la detección mediante el agente de Zabbix, SNMP, scripts externos, HTTP, etc. En este ejemplo, mostraremos cómo usar el agente de Zabbix.
En «Descubrimiento», cree uno nuevo con los siguientes parámetros:
- Nombre: Mounted filesystem Discovery;
- Tipo: Zabbix Agent;
- Clave: vfs.fs.discovery;
- Intervalo de actualización: 1d ou 1h;
- Excluir recursos perdidos: 30d ou 7d.
Con esta configuración, Zabbix podrá comunicarse con el host de destino y descubrir todas las particiones o sistemas de archivos presentes.
{
"{#FSNAME}": "/boot",
"{#FSTYPE}": "xfs"
},
{
"{#FSNAME}": "/opt",
"{#FSTYPE}": "xfs"
},
{
"{#FSNAME}": "/usr/users",
"{#FSTYPE}": "xfs"
},
{
"{#FSNAME}": "/var",
"{#FSTYPE}": "xfs"
},
{
"{#FSNAME}": "/root/home",
"{#FSTYPE}": "xfs"
},
{
"{#FSNAME}": "/var/crash",
"{#FSTYPE}": "xfs"
},
{
"{#FSNAME}": "/app",
"{#FSTYPE}": "xfs"
},
{
"{#FSNAME}": "/home",
"{#FSTYPE}": "xfs"
}
Podemos observar que el JSON devuelve todos los sistemas de archivos montados en el sistema. En función de esta información, podemos crear los elementos según nuestras necesidades.
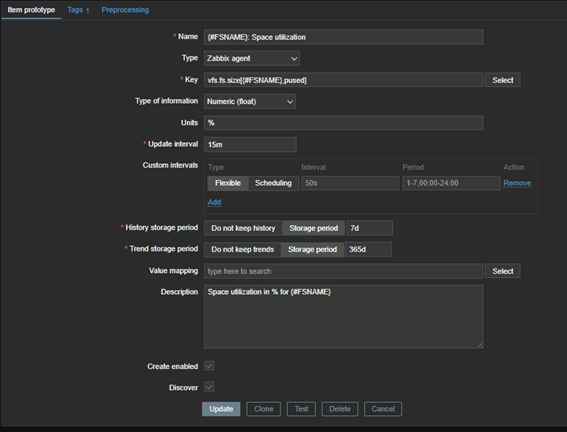
Aquí crearemos el elemento para la utilización del espacio. Para ello, haga clic en «Nuevo» y defina:
- Nombre: {#FSNAME}: Utilización del espacio, donde la macro será el nombre del sistema de archivos devuelto por el JSON;
- Tipo: Agente Zabbix;
- Clave: vfs.fs.size[{#FSNAME},pused];
- Tipo de información: decimal numérico;
- Unidad: en este caso, será un porcentaje, por lo que se utiliza el símbolo %;
- Intervalo de actualización: 15 min.
- Para Historial y Tendencias: utilice 7 días y 365 días, respectivamente.
- Logo, devemos ter essa configuração:
Una vez realizado el descubrimiento en el host de destino, Zabbix creará los elementos. Aquí tenemos el elemento de monitorización para el espacio utilizado en /home:
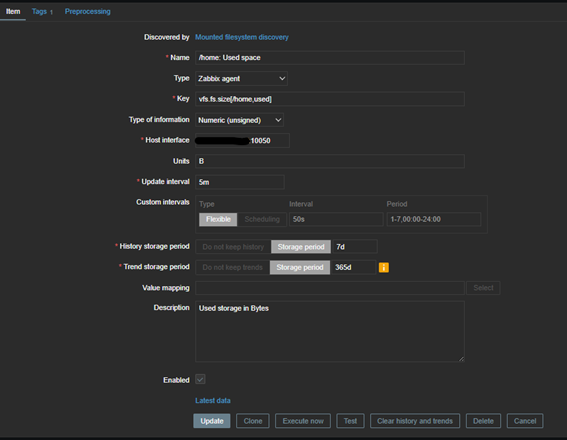
Con el gráfico creado correctamente, deberíamos obtener un resultado similar a este:

Descubrimiento de aplicaciones
Ahora imagina que un host con Windows se ha añadido recientemente a la monitorización de Zabbix y que también tiene servicios que monitorizar. Con el agente de Zabbix y claves específicas, esto es posible. He aquí cómo:
En «Descubrimiento», crea:
- Nombre: Detección de servicios de Windows;
- Tipo: Agente Zabbix;
- Clave: service.discovery;
- Intervalo de actualización: 1 día o 1 hora;
- Eliminar recursos perdidos: 30 días o 7 días
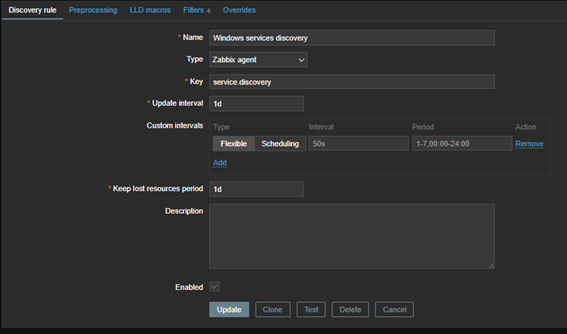
Con esta configuración de descubrimiento, Zabbix puede proporcionar la siguiente información inicial:
{
"{#SERVICE.NAME}": "AJRouter",
"{#SERVICE.DISPLAYNAME}": "AllJoyn Router Service",
"{#SERVICE.DESCRIPTION}": "Routes AllJoyn messages for the local AllJoyn clients. If this service is stopped the AllJoyn clients that do not have their own bundled routers will be unable to run.",
"{#SERVICE.STATE}": 6,
"{#SERVICE.STATENAME}": "stopped",
"{#SERVICE.PATH}": "C:\\Windows\\system32\\svchost.exe -k LocalServiceNetworkRestricted -p",
"{#SERVICE.USER}": "NT AUTHORITY\\LocalService",
"{#SERVICE.STARTUPTRIGGER}": 1,
"{#SERVICE.STARTUP}": 2,
"{#SERVICE.STARTUPNAME}": "manual"
},
{
"{#SERVICE.NAME}": "ALG",
"{#SERVICE.DISPLAYNAME}": "Application Layer Gateway Service",
"{#SERVICE.DESCRIPTION}": "Provides support for 3rd party protocol plug-ins for Internet Connection Sharing",
"{#SERVICE.STATE}": 6,
"{#SERVICE.STATENAME}": "stopped",
"{#SERVICE.PATH}": "C:\\Windows\\System32\\alg.exe",
"{#SERVICE.USER}": "NT AUTHORITY\\LocalService",
"{#SERVICE.STARTUPTRIGGER}": 0,
"{#SERVICE.STARTUP}": 2,
"{#SERVICE.STARTUPNAME}": "manual"
}
Con esta información, estamos listos para crear los artículos.
En «Prototipos de elementos», cree:
- Nombre: Estado del servicio «{#SERVICE.NAME}» ({#SERVICE.DISPLAYNAME});
- Tipo: Agente Zabbix;
- Clave: service.info[«{#SERVICE.NAME}»,state];
- Tipo de información: entero;
- Intervalo de actualización: 1 min o 3 min.
- Para el historial y las tendencias: utilice 7 días y 365 días, respectivamente.
Por lo tanto, deberíamos tener esta configuración:
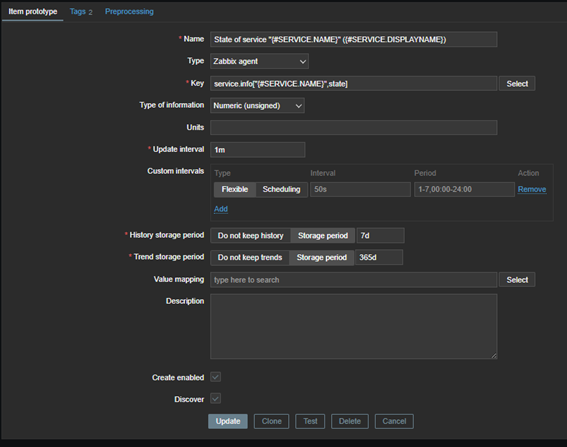
Con estos parámetros, Zabbix debería poder crear todos los elementos relacionados con el descubrimiento de los servicios existentes en el host.

Mejores prácticas en el uso del Low-Level Discovery
Al diseñar reglas de Low-Level Discovery en Zabbix, es fundamental tomar ciertas precauciones para evitar sobrecargar el entorno y generar una cantidad excesiva de elementos. Dos puntos críticos a considerar son la explosión de elementos y el intervalo de descubrimiento.
Explosión de itens
Un LLD (Elemento de Registro Cargable) mal configurado puede generar miles de elementos innecesarios en un host, aumentando el volumen de datos almacenados, consumiendo más recursos del servidor Zabbix y degradando el rendimiento general.
Para minimizar este riesgo, es fundamental utilizar filtros LLD, que permiten crear únicamente los elementos realmente necesarios. Algunos ejemplos de filtrado eficiente incluyen:
- Cree elementos solo para las interfaces cuyo estado operativo sea «ACTIVO».
- Descubra puertos solo cuando la descripción de la interfaz contenga una cadena específica, como «[Monitor]».
- Excluya las interfaces virtuales, VLAN, interfaces de bucle invertido o puertos administrativos, según las necesidades del entorno.
Un LLD bien ajustado produce un conjunto de elementos claros y relevantes, lo que garantiza una supervisión eficiente.
Intervalo de descubrimiento de LLD
El intervalo de descubrimiento determina con qué frecuencia Zabbix vuelve a ejecutar LLD para identificar nuevos elementos o eliminar elementos inexistentes.
Los intervalos muy cortos pueden:
- Genera sobrecarga en el servidor,
- Aumenta el número de solicitudes al host monitorizado,
- Provoca procesamiento innecesario.
Se recomienda establecer este intervalo con cautela, teniendo en cuenta la naturaleza de los objetos monitorizados y la frecuencia con la que cambian.
Intervalo de actualización para los elementos descubiertos
Cada elemento creado por un LLD tiene su propio intervalo de actualización, que define el tiempo entre las recopilaciones de datos. Este intervalo debe reflejar la variabilidad de la métrica.
a) Artículos con poco o ningún cambio
Ejemplos:
- Velocidad de la interfaz (ifSpeed);
- Tamaño del disco.
En este caso, el intervalo recomendado es de entre 12 y 24 horas.
b) Itens con cambios ocasionales, pero recurrentes
Ejemplos:
- Renovación de tokens;
- Volumen de disco con baja variación.
En este caso, el intervalo recomendado es de entre 3 y 6 horas.

c) Itens con cambios constantes
Ejemplos:
- Tráfico de red;
- Uso de CPU;
- Uso de memoria;
- I/O de disco.
En este caso, el intervalo recomendado es de entre 1 y 5 minutos, dependiendo de la criticidad de la métrica y del entorno que se esté monitorizando.
- Importante: Deben evitarse los intervalos inferiores a 10 segundos, ya que tienden a generar una carga excesiva e inestabilidad en la monitorización.
d) Este iten sufre cambios ocasionales, pero esto ocurre a diario.
Podemos utilizar la actualización en 3 o 6 horas, especialmente en casos como la renovación de un token de acceso o cuando el espacio en disco no se está utilizando mucho.
e) Itens con cambios constantes, de uso frecuente, como el tráfico de puertos de red, el uso de memoria, el uso de CPU.
Para este tipo de elementos, podemos usar entre 1 y 3 o 5 minutos; todo depende del entorno y de la importancia de la métrica para el negocio. Idealmente, no debería ser inferior a 10 segundos.

Además de las buenas prácticas ya mencionadas, otra característica esencial para mantener un entorno de monitorización eficiente es la limpieza automática de los elementos que LLD ya no devuelve o que ya no cumplen los filtros configurados.
Cuando LLD ejecuta de nuevo el proceso de descubrimiento, Zabbix identifica:
- Elementos que ya no existen en el host;
- Elementos que han sido renombrados;
- Elementos que han cambiado de estado;
- Elementos que ya no cumplen con los filtros definidos en la regla.
En este caso, el mecanismo de limpieza automática garantiza que estos elementos se eliminen automáticamente después del período configurado. Esta eliminación es esencial para:
- Mantenga una base de datos Zabbix limpia y optimizada;
- Evite la acumulación de elementos obsoletos;
- Reduzca los indicadores marcados como «No compatible»;
- Evite el consumo innecesario de CPU, memoria y E/S en el servidor;
- Asegúrese de que solo se supervisen los elementos válidos y relevantes.
Una política de limpieza automática eficaz complementa directamente el uso de filtros e intervalos adecuados, lo que contribuye a un entorno más ligero, estable y con un mejor rendimiento.
Mejore el uso de LLD en su empresa
La adopción de Low-Level Discovery (LLD) en Zabbix transforma la monitorización en un proceso escalable, estandarizado y sostenible, eliminando tareas manuales repetitivas y reduciendo la probabilidad de errores humanos.
Al reemplazar la creación manual de elementos, triggers y gráficos con prototipos y reglas de descubrimiento, logramos coherencia en la configuración entre instancias, aceleramos la implementación y garantizamos un mantenimiento mucho más sencillo en entornos dinámicos y a gran escala.
Cuente con el equipo técnico de Zabbix para que le recomiende las mejores soluciones para su negocio. Visite nuestra página de Servicios Profesionales para descubrir cómo podemos ayudarle a obtener mejores resultados con Zabbix.