Na minha experiência auditando ambientes de monitoramento corporativos, frequentemente encontro o mesmo padrão: um servidor Zabbix que funciona “bem”, mas que opera com a configuração padrão.
Embora o Zabbix seja famoso pela sua facilidade de implantação, permanecer na camada superficial expõe a infraestrutura a riscos de segurança desnecessários e gargalos de desempenho que costumam aparecer no pior momento possível.
Hoje quero aprofundar, a partir de uma perspectiva técnica, nesses recursos “ocultos” ou subutilizados que transformam uma instalação básica em um ambiente robusto de classe empresarial.
Falaremos de segurança Zabbix e de otimização de backend.
Segurança: Além do firewall
A segurança no Zabbix não termina nas regras de firewall ou no grupo de segurança da nuvem. Existem camadas internas que frequentemente são ignoradas.
De macros de texto a cofres externos (Vaults)
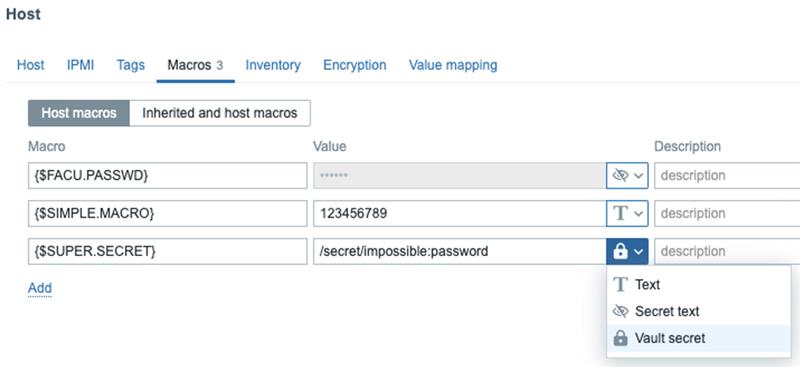
Um dos erros mais comuns é armazenar credenciais (SNMP community, passwords de bancos de dados, tokens de API) em macros globais visíveis ou simplesmente “ocultas” na interface.
Desde versões recentes, o Zabbix permite integração nativa com HashiCorp Vault ou CyberArk. Isso significa que o servidor Zabbix nunca armazena a senha; ele apenas solicita o token ao vault quando é necessário executar o check.
- Por que usar: se o seu servidor Zabbix for comprometido ou se alguém exportar um template, as credenciais não vão junto com ele.
- Configuração-chave: em zabbix_server.conf, procure os parâmetros “VaultToken” e “VaultUrl”.
Criptografia de tráfego (TLS-PSK)
Ainda vejo muitos agentes Zabbix se comunicando com o servidor em texto plano (porta 10050/10051).
Em redes internas confiáveis pode parecer aceitável, mas em ambientes híbridos ou DMZ, é um risco crítico. Configurar PSK (Pre-Shared Key) é uma tarefa única de configuração que garante que ninguém possa injetar dados falsos nem ler suas métricas em trânsito.
O princípio do menor privilégio
Muitos administradores ainda utilizam contas “Super Admin” para tarefas diárias de monitoramento ou para scripts de integração. O recurso “oculto” moderno são os User Roles granulares.
Agora você pode criar um papel específico para um operador que apenas visualize dashboards, mas não possa executar scripts; ou um papel para uma API com acesso de leitura, mas com o acesso ao frontend web bloqueado.
- Dica de segurança: crie um papel específico com acesso negado à interface gráfica e atribua-o aos seus usuários de API/automação. Isso reduz drasticamente a superfície de ataque.
Política de retenção: Menos é mais
Uma das recomendações oficiais do Zabbix mais ignoradas é a configuração de armazenamento do item. Por padrão, muitos templates armazenam 90 dias de histórico (History). Isso é ineficiente e desnecessário para a maioria das métricas.
A best practice para máxima eficiência é:
- History (Dados brutos): reduzir para 7 ou 14 dias. Raramente você precisa saber o uso exato de CPU por segundo de um mês atrás.
- Trends (Dados agregados): aumentar para 365 dias (ou mais). Isso ocupa pouquíssimo espaço e permite visualizar a evolução anual.
Ao ajustar isso nos seus templates base, o processo de Housekeeping (limpeza de dados) deixa de estrangular a CPU do seu banco de dados a cada hora.
A eficiência no Zabbix não se trata apenas de “adicionar mais CPU”. Trata-se de como processamos e armazenamos os dados.
A revolução do TimescaleDB
Se você está utilizando PostgreSQL e ainda não implementou TimescaleDB, está desperdiçando recursos.
TimescaleDB converte as tabelas de histórico em hypertables, permitindo uma compressão massiva (muitas vezes reduzindo o espaço em disco em 90%) e eliminando a necessidade do lento processo de housekeeping por DELETEs, substituindo-o pela remoção de chunks muito mais eficiente

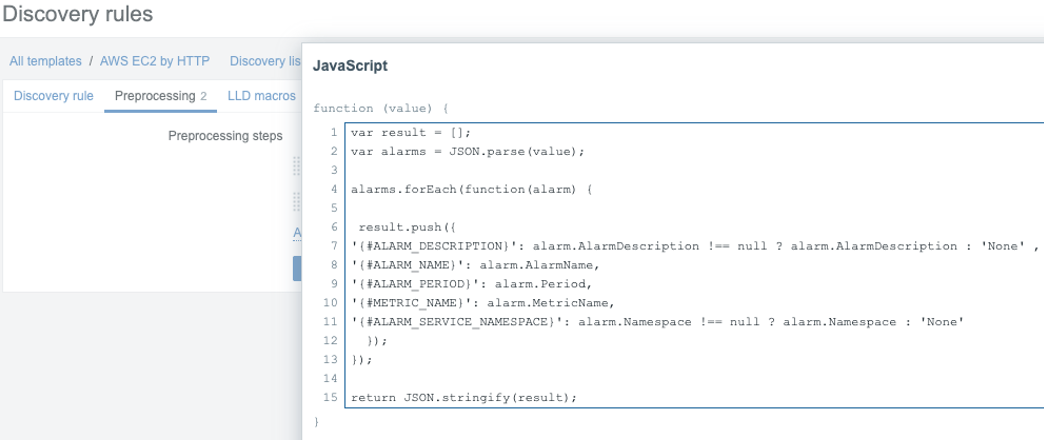
Pré-processamento com JavaScript: Menos scripts externos
Antigamente, para manipular um dado complexo, chamávamos um external script em Bash ou Python. Isso é custoso em nível de sistema operacional (forking de processos).
Hoje, o recurso “oculto” mais poderoso é o pré-processamento com JavaScript. Você pode fazer parse de JSON, XML ou realizar lógica matemática complexa diretamente no fluxo de coleta de dados do servidor, sem invocar processos externos.
- Exemplo: transformar uma resposta JSON de uma API diretamente em métricas utilizáveis na etapa de descoberta (LLD).
Triggers inteligentes: História vs. Tendências
Um erro silencioso que compromete o desempenho do banco de dados é o uso incorreto de funções de tempo nos triggers. É comum ver expressões como avg(/host/key, 1w) para calcular a média de uma semana.
Qual é o problema? O Zabbix tenta calcular isso com base no histórico (history). Se o item é coletado a cada minuto, o banco de dados precisa ler e processar mais de 10.000 linhas para avaliar um único trigger.
O recurso “oculto” aqui são as Funções de Tendência:
(trendavg, trendmin, trendmax, etc.).
O Zabbix já armazena dados pré-calculados e agregados por hora na tabela de tendências. Ao alterar a função para trendavg(/host/key, 1w), o Zabbix precisa ler apenas 168 registros (24 horas x 7 dias) em vez de 10.000.
- Quando usar História (avg, min, max): para detecções precisas em janelas curtas (ex.: últimos 10–60 minutos).
- Quando usar Tendências (trendavg, trendmin, trendmax): para análise de capacidade, comparações de longo prazo (semanas, meses) ou linhas de base, onde a granularidade exata por minuto não é crítica.
Impacto: você libera drasticamente o Value Cache e reduz operações de I/O em disco, permitindo que seu servidor monitore mais hosts com o mesmo hardware.
Comparativo de eficiência
Suponhamos que queremos um alerta se o uso de disco atual for maior que a média dos últimos 30 dias (para detectar anomalias de crescimento). Assumindo um Update Interval de 1 minuto:
Forma ineficiente (Uso de Histórico):
last(/BD_Server/vfs.fs.size[/,pused]) > avg(/BD_Server/vfs.fs.size[/,pused], 30d)
- O que o Zabbix faz: consulta a tabela history.
- Custo: precisa ler 43.200 registros (60 min * 24h * 30 dias) cada vez que o trigger é avaliado.
- Resultado: pressão no banco de dados e lentidão.
Forma otimizada (Uso de Tendências):
last(/BD_Server/vfs.fs.size[/,pused]) > trendavg(/BD_Server/vfs.fs.size[/,pused], 30d)
- O que o Zabbix faz: consulta a tabela trends (dados já agregados por hora).
- Custo: lê apenas 720 registros (24h * 30 dias).
- Resultado: o mesmo cálculo lógico, porém 60 vezes mais rápido e leve.
Exemplos práticos de configuração (Tuning)
Para administradores de sistemas, segue uma comparação de parâmetros que costumam marcar a diferença entre um servidor lento e um otimizado.
|
Parâmetro (zabbix_server.conf) |
Configuração
Padrão |
Recomendação | Impacto |
| StartPollers | 5 | Ajustar conforme demanda em % | Reduz a fila de items, mas cuidado: pollers demais podem saturar a DB. |
| StartPollersUnreachable | 1 | 10 – 20 | Vital. Evita que os pollers normais fiquem bloqueados aguardando hosts indisponíveis. |
| ValueCacheSize | 8M | 128M – 512M (segundo RAM) | Reduz drasticamente leituras no banco de dados para triggers. |
Conclusão
Implementar segurança Zabbix avançada por meio de Vaults e criptografia, junto com a otimização do banco de dados com TimescaleDB, não são apenas “melhorias”; são requisitos para qualquer ambiente crítico moderno.
Essas configurações ocultas permitem que o Zabbix escale junto com sua infraestrutura, em vez de se tornar um gargalo. Minha sugestão é começar auditando o ValueCache e avaliar a migração para TimescaleDB caso você ainda utilize tabelas SQL padrão.
Quer se aprofundar em como implementar TimescaleDB ou a integração com Vault? Consulte nossa documentação técnica oficial ou entre em contato para uma consultoria.