




Compreender como funciona a arquitetura do Zabbix, os componentes que fazem parte da estrutura e como eles se conectam é importante para garantir o correto uso do software. Mas, principalmente, para o desenvolvimento de um ambiente de monitoramento mais eficiente, estável e bem estruturado em diferentes cenários.
Neste artigo, vamos revisitar os conceitos e componentes centrais do Zabbix, explorando também boas práticas que ajudam a extrair o máximo desempenho e valor da solução.
Acompanhe!
Principais conceitos do ecossistema de monitoramento Zabbix
Coleta de dados
A coleta é um dos pilares do Zabbix e pode ser realizada de diversas maneiras, permitindo monitorar praticamente qualquer tipo de recurso. Entre as possibilidades, destacam‑se:
- Verificações de disponibilidade e desempenho;
- Suporte a vários protocolos, como ICMP, SNMP, IPMI, JMX, SSH e monitoramento VMware;
- Monitoramento via Zabbix Agent e Zabbix Agent2;
- Coletas através de ODBC para bancos de dados;
- Execução de verificações externas (External Checks), permitindo scripts personalizados;
- Coletas feitas diretamente pelo Zabbix Server, Proxy ou Agent.
Triggers e alertas
O mecanismo de triggers do Zabbix permite interpretar os dados coletados e identificar condições anômalas, através do disparo de alertas. Os principais recursos incluem:
- Criação de triggers personalizadas, flexíveis e com lógica avançada;
- Envio de alertas configuráveis, com escalonamento por usuário, grupo ou tipo de mídia;
- Execução de ações automáticas com comandos remotos, integrando o monitoramento à automação.
Visualização, gráficos e dashboards
O Zabbix oferece diversas maneiras de visualizar os dados, facilitando o entendimento do ambiente:
- Itens coletados podem ser inseridos em dashboards dinâmicos e interativos;
- Dashboards podem ser exportados e enviados automaticamente por e‑mail;
- Cada item pode gerar gráficos em tempo real;
- Possibilidade de criar mapas customizados, desde topologias de rede até representações de serviços.
Armazenamento de dados
O armazenamento estruturado das informações garante histórico e rastreabilidade, uma vez que:
- Todos os dados coletados são gravados em um banco de dados;
- Mantém histórico detalhado conforme políticas definidas;
- Conta com um mecanismo de limpeza (housekeeping) totalmente configurável.
Componentes principais da arquitetura Zabbix
Zabbix Server
O Zabbix Server é o núcleo central de todo o ecossistema de monitoramento, que coordena praticamente todas as operações essenciais da plataforma. Entre as principais responsabilidades do Server, estão:
- Realizar coletas diretas de alguns tipos de itens;
- Receber e processar dados enviados pelos proxies;
- Avaliar e calcular triggers;
- Acionar notificações e executar ações automáticas;
- Processar verificações internas e itens específicos;
- Manter e consultar toda a configuração do ambiente.
Toda a configuração (hosts, templates, itens, triggers, usuários, ações e demais objetos) é armazenada no banco de dados, e é sempre o Zabbix Server que se conecta a esse banco para carregar e atualizar essas informações. Sempre que o serviço do Zabbix Server é iniciado ou reiniciado, ele reconstrói o estado interno lendo integralmente a configuração armazenada.
Um exemplo prático desse funcionamento:
Quando você cria um novo item pelo frontend (ou via API), ele é imediatamente gravado nas tabelas do banco de dados. O Zabbix Server, então, periodicamente (aproximadamente a cada minuto) consulta essas tabelas para obter a lista atualizada de itens ativos. Essa lista é armazenada no cache interno do próprio Server. Por isso, alterações realizadas na interface podem levar até dois minutos para aparecer em seções como Latest Data.
Banco de dados
Como já mencionamos, o banco de dados é um dos componentes mais importantes do Zabbix. Ele funciona como o repositório central onde são armazenadas praticamente todas as informações de configuração do ambiente de monitoramento. Sem ele, o Zabbix Server simplesmente não consegue operar.
O banco registra itens essenciais, como:
- Hosts e grupos;
- Itens, triggers, gráficos e templates;
- Ações e mídias de notificação;
- Usuários, grupos de usuários e roles;
- Configurações de histórico e trends.
Esses dados são carregados e processados pelo Zabbix Server sempre que o serviço é iniciado ou reiniciado. Durante o funcionamento normal, o servidor continua consultando o banco de dados regularmente para manter seu cache interno sempre atualizado. É esse cache que garante velocidade no processamento das coletas, triggers e visualizações.
Outro ponto importante é o housekeeping, o processo de limpeza automática do Zabbix. Ele atua diretamente no banco, removendo dados antigos de histórico, eventos e tendências conforme as políticas configuradas. Essa rotina evita o crescimento descontrolado do banco de dados, contribuindo para a saúde, desempenho e estabilidade do sistema.
Frontend web
O frontend web (também chamado de interface web), é a camada de interação entre o Zabbix e seus administradores ou usuários. É por meio dele que toda a configuração da plataforma é realizada: criação de templates, itens, triggers, dashboards, ajustes administrativos e o gerenciamento completo do ambiente de monitoramento.
A interface oferece uma navegação estruturada e intuitiva, permitindo visualizar dados em tempo real, explorar gráficos, consultar eventos, analisar problemas e acompanhar o estado da infraestrutura monitorada.
Além disso, o frontend web integra a API oficial do Zabbix, disponibilizando todas as operações necessárias para automação e integração com outras ferramentas. Tudo o que pode ser feito pela interface também pode ser realizado pela API, facilitando a criação de pipelines, scripts, integrações corporativas e fluxos de automação.
Como os dados fluem no Zabbix
Zabbix Agent
O Zabbix Agent é utilizado para monitorar sistemas operacionais e seus recursos. É capaz de coletar dados de discos rígidos, memória, CPU, interfaces de rede, processos, serviços e etc.
Atualmente, existem 2 tipos de Zabbix Agent:
O Agent clássico:
- Escrito em linguagem C;
- Possui daemon;
- Conta com extensões suportadas em C, quando customizados;
- Simultaneidade: verificações ativas para um único servidor são executadas sequencialmente;
- Faz intervalos programados/flexíveis, apenas para verificações passivas;
- Não possui armazenamento persistente;
- Conta com configuração de timeout limitado;
O Agent 2:
- Escrito em linguagem Go e em C;
- Conta com Systemd ao invés de Daemon;
- Permite a customização/criação de plugins em Go;
- Possibilita expandir a monitoração nativa para Docker, MySQL, PostgreSQL, Redis, systemd e outros;
- Simultaneidade: verificações diferentes ou múltiplas são executadas simultaneamente;
- Intervalos programados/flexíveis, apenas para verificações passivas e ativas;
- Possui armazenamento persistente;
- Configuração de timeout personalizado por plugin;
Dentro do Zabbix Agent, também temos as verificações passivas e ativas, que funcionam da seguinte maneira:
- Verificações Passivas → O Zabbix Agent responde a uma solicitação do Zabbix Server ou do Zabbix Proxy.
- Verificações Ativas → O Zabbix Agent coleta e envia os dados sem aguardar a uma solicitação do Zabbix Server ou Zabbix Proxy. Ao ser iniciado o serviço do Zabbix Agent, ele recupera uma lista de itens a serem monitorados e seus parâmetros logo após coleta, e envia os dados de acordo com os intervalos de coleta definidos.
É durante a criação do item que definimos qual tipo de verificação estamos criando. O Zabbix Agent processa items do tipo “Zabbix Agent” ou “Zabbix Agent (ativo)”. As verificações do tipo Zabbix Agent utiliza a porta TCP 10050, enquanto as do tipo Zabbix Agent (ativo) faz uso da porta TCP 10051.
Fluxo de coleta e processamento de dados no Zabbix
Após definir o tipo de coleta entre ativa ou passiva via Zabbix Agent, os dados começam a circular entre o Zabbix Server ou Proxy, seguindo o fluxo interno de processamento.
Pré-processamento
Assim que os dados são recebidos, inicia-se a etapa de pré-processamento, onde ocorrem transformações antes do armazenamento.
Entre as operações possíveis, estão:
- Conversão de unidades;
- Multiplicadores customizados;
- Extração via regex, JSONPath, JavaScript;
- Diversas outras regras disponíveis no Zabbix.
Somente após essa etapa os valores seguem para o próximo estágio.
Configuration Syncer e atualização de caches
Em seguida, o configuration syncer entra em ação. Ele mantém atualizadas todas as informações de:
- Itens;
- Triggers;
- Configurações de coleta;
- Hosts.
Nesse processo, o Zabbix atualiza os principais caches internos:
- History → Armazena temporariamente os dados coletados antes da escrita no banco;
- Values → Guarda os últimos valores, utilizados nos cálculos das triggers;
- Trends → Consolida dados para armazenamento otimizado a longo prazo.
History Syncer e gravação no banco
Após a atualização dos caches, o history Syncer grava definitivamente os dados no banco de dados do Zabbix.
Avaliação de triggers e geração de eventos
A cada coleta, o Zabbix Server avalia as triggers associadas aos itens, aplicando as funções configuradas.
Se alguma condição for atendida, um evento é gerado.
Exemplo: a condição prevê que, se o uso de CPU estiver acima de 95% por 10 minutos, um evento deve ser disparado.
Com o evento criado, o Zabbix pode executar ações como:
- Envio de notificações (e-mail, SMS, ligação);
- Execução de comandos remotos;
- Abertura automática de chamados;
- Outras integrações de automação.
Visualização dos dados
O frontend do Zabbix oferece uma interface rica para análise das métricas coletadas. A partir dele, é possível criar:
- Gráficos;
- Dashboards;
- Mapas;
- Relatórios.
Com o Zabbix Web Service, também é possível programar o envio automático de relatórios. Toda a análise das métricas armazenadas ocorre diretamente nessa interface.
Tipos de implantações comuns no Zabbix
Ao planejar a infraestrutura de monitoramento com Zabbix, normalmente consideramos três modelos principais de implantação: instalação All-in-One ou Standalone, instalação em 2 camadas e instalação em 3 camadas.
Cada um deles varia em complexidade, escalabilidade e resiliência, dependendo das necessidades do ambiente. Vamos explicar brevemente, com indicações de uso, a seguir:
Instalação All-in-One ou Standalone
Este é o modelo mais simples e menos complexo dos 3 cenários apresentados. Todos os componentes são instalados em um único servidor:
- Zabbix Server;
- Banco de dados;
- Frontend web.
Esse cenário é indicado para pequenos ambientes, onde a carga e novos valores por segundo é baixo, para laboratórios, provas de conceito, etc. Dessa maneira, a concorrência dos serviços/processos por recursos não é tão grande.
Instalação em 2 camadas
Esse modelo é de complexidade média, e consiste em realizar uma separação dos componentes da seguinte maneira:
- Zabbix Server + frontend web;
- Banco de Dados.
Nesse cenário, teremos ao menos 2 servidores dedicados ao core do monitoramento Zabbix. É indicado para ambientes médios, onde o volume de métricas coletas já é alto, considerando acessos de usuários e consultas.
Instalação em 3 camadas
Entre os 3 cenários, esse é o mais complexo de implantação. Também é considerado o mais robusto e escalável. A divisão dos componentes acontece da seguinte maneira:
- Zabbix Server;
- Frontend web;
- Banco de dados.
Este cenário é indicado para ambientes grandes, com altos valores recebidos por segundo, quantidade considerável de usuários realizando consultas.
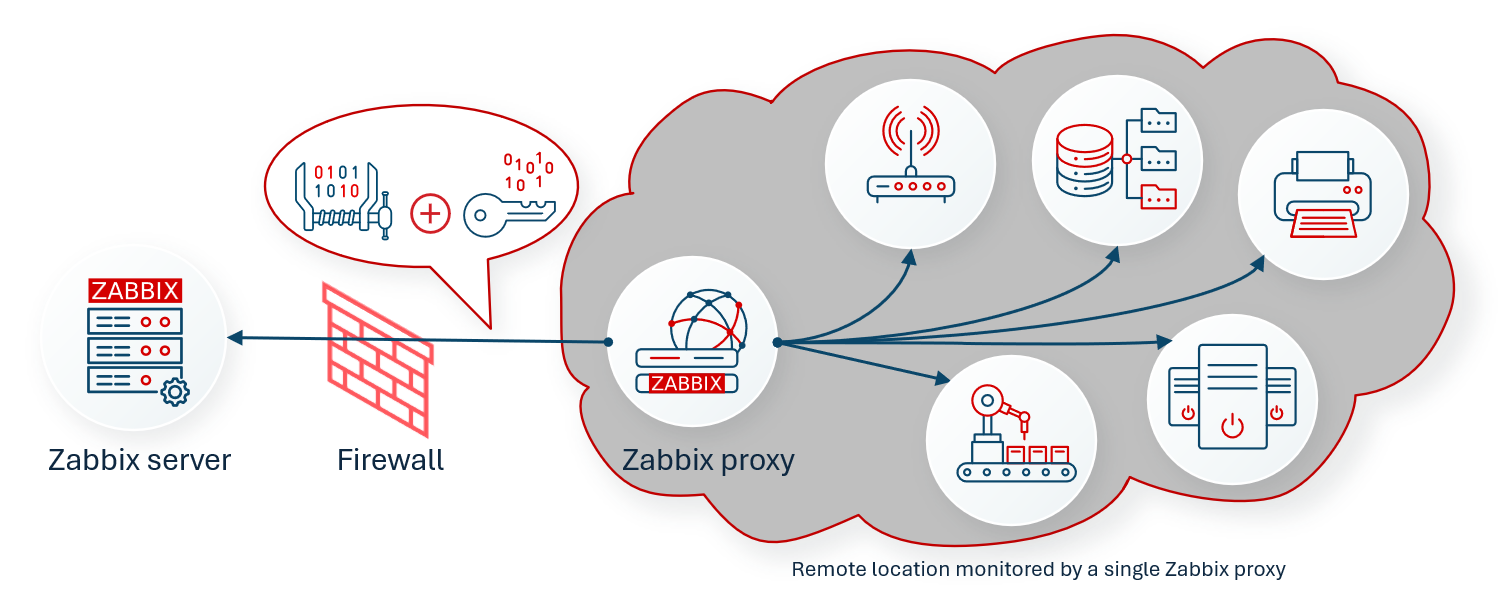
Dentro do planejamento da arquitetura de um ambiente Zabbix, é importante considerar o uso do Zabbix Proxy, um componente extremamente útil e aplicável a qualquer um dos modelos de implantação apresentados. O Zabbix Proxy atua como um coletor intermediário, capaz de monitorar desde alguns até milhares de dispositivos, e encaminhar todos os dados para o Zabbix Server.
O proxy desempenha um papel estratégico ao permitir o monitoramento de redes remotas ou isoladas, onde o Zabbix Server não possui acesso direto.
Um cenário comum é a criação de uma máquina virtual (VM) com o proxy em um ambiente remoto, responsável por:
- Coletar métricas localmente;
- Armazenar temporariamente os dados;
- Encaminhá-los ao Zabbix Server quando a comunicação estiver disponível.
Dessa forma, evita-se a necessidade de abrir diversas regras de firewall, configurar NAT ou expor portas sensíveis, reduzindo riscos de segurança.
A utilização do Zabbix Proxy conta com benefícios como:
- Mais segurança: reduz a exposição de portas e minimiza a superfície de ataque;
- Maior resiliência: o proxy pode continuar coletando dados mesmo que a conexão com o server seja temporariamente perdida;
- Melhor desempenho: distribui a carga de coleta e pré-processamento, diminuindo o trabalho do Zabbix Server.
Na imagem abaixo, temos um exemplo de utilização do Zabbix Proxy:
Conclusão
Dominar os componentes presentes na arquitetura do Zabbix possibilita construir e suportar um ambiente de monitoramento eficaz, seguro e escalável.
Ao entender como esses elementos se relacionam e interagem dentro do ecossistema Zabbix, além de projetar ambientes mais resilientes e robustos, com melhor distribuição de carga entre coleta e processamento de dados, o profissional também contribui para que os problemas identificados no monitoramento sejam tratados com maior agilidade e precisão.
Aprender a teoria é o primeiro passo para coloca o monitoramento em prática. Aproveite para se aprofundar nas demais funcionalidades da ferramenta consultando a documentação oficial do Zabbix.




Muito importante conhecer a arquitetura!