Introducción
Imagínese la felicidad de comenzar un proyecto de monitoreo de activos de red con Zabbix[i]. De hecho, hoy, el manejo básico de la herramienta es tan fácil que los primeros resultados de las recolecciones de datos ya nos dejarían casi completamente satisfechos, por ejemplo, al aplicar un template a un host y ver los datos ya «brotando» en los dashboards.
Si todavía no lo hizo, ¡pruébelo! Cree un web server. Usted puede usar Apache o, además, Nginx, aplicándole el correspondiente template[ii]nativo para la recolección de métricas vía HTTP: “Apache by HTTP” o “Nginx by HTTP”. Usted observará que métricas interesantes son recolectadas y enseguida se conseguirá crear (ya estarán creados) gráficos para consumo en dashboards. Pero, ¿qué es eso? ¿Está listo? No, y vendrá algo más.
Con Zabbix, podemos ir más allá. Discutiremos en este primer artículo cómo pensar nuevas métricas, nuevos casos, cómo apoyar y alcanzar algunos resultados importantes para el negocio, introduciendo conceptos que muchos analistas dejaron escapar porque cayeron en la trampa de la «facilidad» y algunos otros conceptos nuevos, como los que se usan en algunos proyectos de Ciencia de Datos.
¿Nuestro objetivo? Descubrir algunas nuevas funciones de Zabbix que surgieron a partir de la versión 6.0 y presentar modelos prácticos de análisis y exhibición de datos, creando insights.
Contexto
Para que nuestro estudio sea dirigido, mantendremos el enfoque en las métricas de un web server, teniendo em mente que el desarrollo sugerido aquí podrá ser aplicado en otros servicios, observando su debido contexto.
Nuestro web server se ejecuta bajo nginx 1.18.0. Aplicamos el template “Nginx by HTTP”. Las métricas recolectadas son las siguientes:
-
- HTTP agent master item: get_stub_status
- Dependent items[i]:
Nginx: Connections accepted per second
Nginx: Connections dropped per second
Nginx: Connections handled per second
- Simple check items:
Nginx: Service response time
Ok, esas son las posibilidades actuales.
Creamos un dashboard sencillo, con base en las métricas recolectadas con el templae nativo. ¿Qué pueden ellas decirnos sobre nuestro web server?
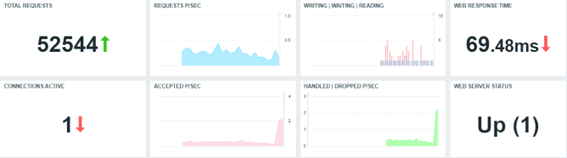
Todos los Widgets, en este caso, se están reflejando las métricas recolectadas por la propuesta del template estándar “Nginx by HTTP”.
Sin muchos detalles sobre el formateo de los Widgets, existen algunas críticas que necesitamos hacer, como especialistas en Zabbix y con alguna comprensión de la aplicación que estamos monitoreando. Todas las críticas, claro, son constructivas y sugerencias para implantaciones para ahora o para el futuro (por ejemplo, cambiar el template estándar). Señalaremos algunos elementos en la próxima sesión.
Reflexiones para generar nuevas métricas
Observando las métricas que se recolectaron inicialmente, vamos a enumerar algunas preguntas y, en seguida, vamos a intentar responderlas, usando nuestra serie de artículos, comenzando por esta.
- ¿Por qué la cantidad de requisiciones totales solo sube?
- Sabemos que la cantidad de requisiciones activas al momento de la recolección. Tenemos un histórico. Podemos generar un gráfico. Entonces, en qué momento tuvimos más o menos conexiones en determinada hora. Y si lo comparamos con la hora anterior, ¿cuál es el porcentaje de variación?
- ¿Cuál fue el mejor o el peor tiempo de respuesta en la última hora, en el día de hoy, en la semana, en el mes o en el año?
- Con base en la observación de los tiempos de respuesta, ¿podemos prever una probable caída de aplicación?
- ¿Podemos detectar anomalías por medio de un estándar de comportamiento del servicio?
- ¿Sería posible establecer una «baseline”? ¿Cómo se hace eso?
- Si hay una baseline, es posible realizar una comparación con el esperado x hecho. ¿Cómo representar esa diferencia? ¿Qué podría significar?
Esas son algunas de varias preguntas que podemos y debemos hacer de forma constructiva. Veamos cómo responder a algunas de esas preguntas.
Generando nuevas métricas
1º paso: Clone el template “Nginx by HTTP” y cree template “Nginx by HTTP modified”.
2º paso: Ingrese al ítem “Nginx: Requests total” y en la guía “Preprocessing”, añada otro paso al final: “Simple change”. Debe quedar exactamente como en la imagen abajo:
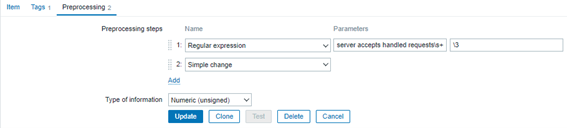
Este ítem es un “Dependent item” de “Nginx: Get stub status page”, el cual se recolecta por medio del HTTP agent a cada minuto. Por lo tanto, si el número de conexiones apenas crece (y sólo va a recomenzar cuando y si el servicio Nginx es reiniciado), el valor actual será sustraído del valor antes recolectado, lo que nos dará la diferencia de conexiones en el último minuto.
La fórmula que representa el Preprocessing “Simple change” puede ser ilustrada abajo:

Así, también se sugiere cambiar el nombre del ítem para “Nginx: Requests at last minute”, pues no se trata más de un total de requisiciones. Ahora, vamos a generar métrica de nuevas conexiones por minuto.
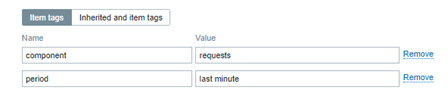
Añada también una nueva información en la guía Tag[i] del ítem, como en la figura abajo:
Variaciones de la misma métrica
ahora que cambiamos un punto importante en el template, nuestro monitoreo consigue decirnos cuántas nuevas conexiones por minuto el web server recibió y, con eso, podemos generar métricas para un total de conexiones en bloques específicos de tiempo (timeshift[i]), como:
- Durante la última hora
- Hoy, hasta ahora
- Ayer
- Durante esta semana
- Durante la semana anterior
- Durante este mes
- Durante el mes anterior
- Durante este año
- Durante el año anterior
Ese ejercicio puede ser interesante. Vamos a crear varios ítems del tipo «Calculated» con las siguientes fórmulas:
sum(//nginx.requests.total,1h:now/h) # Suma de nuevas conexiones durante la hora anterior
sum(//nginx.requests.total,1h:now/h+1h) # Suma de nuevas conexiones de la hora actual
Los documentos de la fabricante son cruciales para que esos ítems sean correctamente creados y va a ayudar también en la selección entre rescatar el valor de «history» o de «trends». Vea este enlace.
Mejorando nuestro dashboard
Con los nuevos valores, ahora podemos dejar nuestro dashboard más interesante. Vamos a ver:
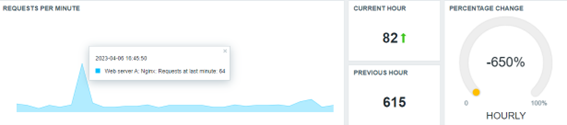
El mismo framework puede ser usado para exhibir los datos diarios, semanales, anuales y sus correspondientes comparaciones. Será necesario un poco de paciencia, en este caso, pues si construimos los nuevos ítems ahora, llevará un tiempo hasta que algunos de ellos hagan su primera recolección (o semanal, mensual o anual, por ejemplo).
Generando estadísticas básicas
Como lo sabemos, es perfectamente posible generar algunas estadísticas básicas con Zabbix. Algunas preguntas pueden nuevamente guiarnos para las respuestas que vendrán en formato de métricas:
- ¿Cuál es el mejor tiempo de respuesta que el servicio ha presentado hoy?
- ¿Y cuál ha sido el peor tiempo de respuesta?
- ¿Cuál es el promedio del día?
Vamos a iniciar con estas más básicas y avanzar con las demás, posteriormente.
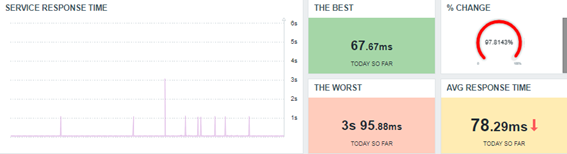
Todas las respuestas se encontraron usando funciones sencillas, como:
Mejor tiempo de respuesta hoy, hasta ahora (today so far)
min(//net.tcp.service.perf[http,»{HOST.CONN}»,»{$NGINX.STUB_STATUS.PORT}»],1d:now/d+1d)
Peor tiempo de respuesta hoy, hasta ahora (today so far)
max(//net.tcp.service.perf[http,»{HOST.CONN}»,»{$NGINX.STUB_STATUS.PORT}»],1d:now/d+1d)
Promedio del mejor tiempo de respuesta hoy, hasta ahora (today so far)
avg(//net.tcp.service.perf[http,»{HOST.CONN}»,»{$NGINX.STUB_STATUS.PORT}»],1d:now/d+1d)
Ok. ¿Algo nuevo aquí? Creo que no. Pero, merece una reflexión:
¿Por qué estamos buscando el mayor, menor y el promedio de los valores recolectados con las funciones máx, mín y avg, respectivamente, en vez de usar trendmax, trendmin y trendavg? Estas últimas rescatan datos ya calculados para los valores mayores, menores y para los promedios de cada hora de la tabla trens, en vez de realizar todo el cálculo por los valores recuperados de la tabla history a lo largo del tiempo. Piense en el coste operacional que esa tarea tendrá cuando vayamos a calcular los valores semanales, mensuales y anuales.
Sin embargo, hay un detalle importante: cuando optamos por Trend-based Functions en vez de History Functions, asumimos que nuestras estadísticas nos retornarán valores hasta la última hora completa, señalando los valores de la hora actual, hasta que ella sea terminada y Zabbix haga el sincronismo de la hora con el banco de datos, para comenzar el ciclo nuevamente. Vale revisar cómo se genera la tabla trends.
Vamos a reproducir el dashboard, ahora, usando Trend-based Functions para las estadísticas.
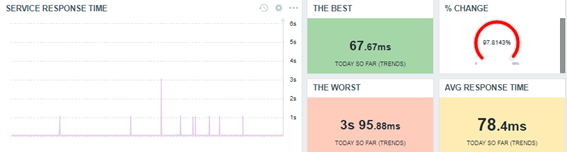
Observe que alcanzamos básicamente el mismo resultado, pero de forma más eficaz y con menos esfuerzo de Zabbix (consecuentemente, exigiendo menos de toda la solución y aumentando el desempeño de todos los cálculos involucrados).
Insights
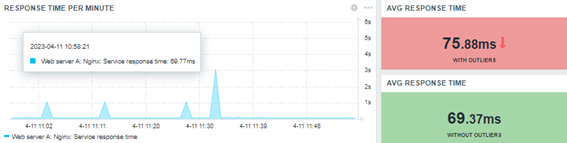
Si un tiempo de respuesta es muy breve, como 0.06766 (el mejor del día) o, aún, si es muy grande, como 3.1017 (el peor del día), imagínese cuáles valores son posibles entre ellos (entre el mínimo y el máximo).
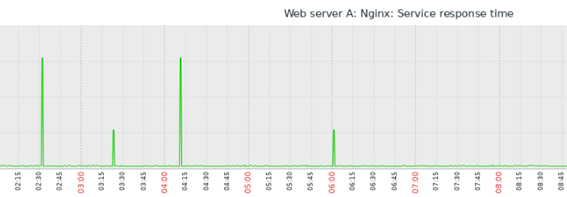
¿Cómo calcular el promedio?
El promedio aritmético tradicional suma la cantidad de valores reunidos en determinado período, dividiendo esa suma por la cantidad de valores.
Hasta aquí, ok. La función “avg” o, además, la “trendavg” son responsables por generar (o rescatar) esos cálculos, por así decirlo. Pero, observando el gráfico anterior, tenemos que en determinado período, apenas en algunos momentos suceden «picos» del tiempo de respuesta, de modo que en todo el resto del tiempo analizado, la operación tal vez haya sido como esperado, o sea, ignorando los picos, deberíamos calcular un nuevo promedio, pues los valores más altos van a cambiar nuestro promedio sustancialmente y, tal vez, no sea el cálculo adecuado para medir cómo está respondiendo nuestra aplicación web. Sin embargo, también es verdad que los «picos» son importantes, pues pueden significar un error, una ‘desviación’, dentro de lo que era esperado. Esos errores o desviaciones todavía no podrían ser considerados «anomalías» (estudiaremos anomalías más tarde).
En estadística, los «picos» se llaman «outliers». Ellos representan el error, la desviación (no estamos hablando, todavía, sobre desviación estándar) y son influenciadores de las estimaciones de ubicación (los promedios que queremos calcular).
Las funciones “avg” y “trendavg” son fácilmente influenciadas por los outliers. Entonces, ¿cómo podríamos crear una estimación robusta para el promedio del tiempo de respuesta de nuestra aplicación web desconsiderando los outliers? Existen algunas salidas.
Introducción a la mediana
Considere que los datos inseridos en el banco de datos obedecen al tiempo de su recolección, después, imagínese el siguiente orden de recolección empleado para crear una gráfico estándar:
| 2023-04-06 16:24:50 1680809090 0.06977 |
| 2023-04-06 16:23:50 1680809030 0.06981 |
| 2023-04-06 16:22:50 1680808970 0.07046 |
| 2023-04-06 16:21:50 1680808910 0.0694 |
| 2023-04-06 16:20:50 1680808850 0.06837 |
| 2023-04-06 16:19:50 1680808790 0.06941 |
| 2023-04-06 16:18:53 1680808733 3.1101 |
| 2023-04-06 16:17:51 1680808671 0.06942 |
| 2023-04-06 16:16:50 1680808610 0.07015 |
| 2023-04-06 16:15:50 1680808550 0.06971 |
| 2023-04-06 16:14:50 1680808490 0.07029 |
Cuando calculemos el promedio aritmético, no importará el orden de esos valores. Pero, si organizamos de forma creciente esos mismos valores, podemos tener una visión diferente:
| 0.06837 | 0.0694 | 0.06941 | 0.06942 | 0.06971 | 0.06977 | 0.06981 | 0.07015 | 0.07029 | 0.07046 | 3.1101 |
Tabla 1.0 – 11 valores recolectados, clasificados de forma creciente.
In this case, the values are ordered by from the smallest one to the biggest one, ignoring their timestamp.
Look at the outlier at the end. It’s not important for us right now.
En ese caso, con los valores ordenados de forma creciente, por ejemplo, observamos que la mediana es exactamente el valor central del conjunto de datos observados, sin ser influenciados por el outliers en pantalla. La línea de datos anterior tiene 11 posiciones, lo que hace fácil la ubicación de la mediana (la central, señalada en bold). Pero, ¿y si hubiera un número par de valores? ¿Cuál sería, entonces, la mediana? Vea a continuación:
| 0.0694 | 0.06941 | 0.06942 | 0.06971 | 0.06977 | 0.06981 | 0.07015 | 0.07029 | 0.07046 | 3.1101 |
Tabla 2.0 – 10 valores recolectados, clasificados de forma creciente.
Retiramos de la Tabla 1.0 el primer valor. De esa forma, tenemos 2 grupos, con cantidad de datos exactamente igual. No hay posición central.
Algunos softwares implantan algoritmos diferentes para calcular la mediana. Algunos, por ejemplo, implantan la mediana como siendo el promedio de dos números que representan la división del 1º y 2º grupo de datos. Los dos números en pantalla están representados en la Tabla 2.0 en bold.
¿Cómo calcular la mediana en Zabbix?
Podemos trabajar el concepto de percentil, en este caso. La mediana, como es un valor central, es sinónimo del “50º percentil”.
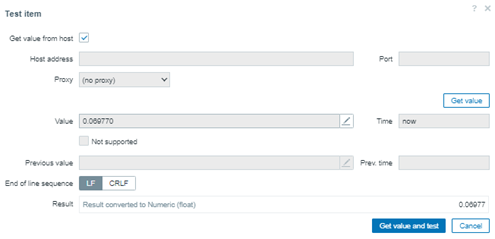
Tome como base los valores de la tabla 1.0. Cree un «Trapper ítem en Zabbix e insiera apenas esos valores:
0.06837, 0.0694, 0.06941, 0.06942, 0.06971, 0.06977, 0.06981, 0.07015, 0.07029, 0.07046, 3.1101
# for x in `cat numbers.txt`; do zabbix_sender -z 159.223.145.187 -s «Web server A» -k percentile.test -o «$x»; done
Al final, tendremos 11 valores en la base de datos de la cual queremos obtener la mediana.
En seguida, cree un Calculated ítem con la siguiente fórmula:
percentile(//percentile.test,#11,50)
En este caso, nuestra lectura será: observe los últimos 11 datos reunidos y regrese al valor ocupa el 50º percentil. Como los valores son impares, es fácil hacer la comparación.
Ahora, vamos a trabajar un valor par de datos y analizar quién se encaja en el percentil. Tenemos, entonces, la Tabla 2.0, con 10 valores. Retiramos de la Tabla 1.0 el valor 0.06837:
0.0694, 0.06941, 0.06942, 0.06971, 0.06977, 0.06981, 0.07015, 0.07029, 0.07046, 3.1101
Limpie el histórico, para evitar errores, ajuste la fórmula para que el percentil busque apenas los 10 últimos valores reunidos y aplique un nuevo test.
percentile(//percentile.test,#10,50)
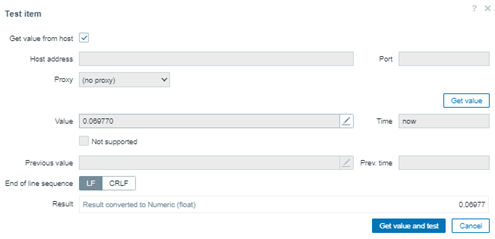
¡Curioso! Obtuvimos el mismo valor. Pero existe una explicación muy interesante.
Dado el conjunto de los valores, los señalados en verde ocupan la posición de 0 a 50º percentil. Y los anaranjados, ocupan del 51º al 100º percentil. Vea:

Para testear y comprobar, basta alterar el último test para recuperar quién se encaja en la posición 51º percentil.
percentile(//percentile.test,#10,51)
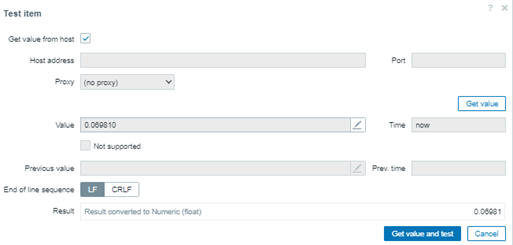
Observe que el valor 0.06981 es el próximo. El primero de la tabla, en el segundo grupo de valores. Pero, si el test se cambia nuevamente, por ejemplo, para buscar que se encaje en 55º percentil, el resultado será el mismo. El resultado solo cambiará si señalamos la posición 61º percentil, en esta caso, en que tenemos apenas 10 valores siendo observados, si evaluamos una cantidad mayor de datos, tendremos nuevos y diferentes resultados.
¿Average o Percentile?
Ambas formas de cálculos son correctas para buscar una estimación de ubicación. Sin embargo, es necesario entender que la primera (average) considera los outliers, ya la segunda (percentile), no. Pero, cada una de las técnicas tienen determinada aplicación, según la necesidad de observación.
Veamos una actualización de nuestro dashboard:
No necesitamos convencer a nadie sobre la métrica correcta, pero exhibir la información y su contexto.
Mediana
Si observamos que la mediana ocupa el valor central de los datos, la fórmula de 50º percentil será útil cuando la cantidad de valores observados sea impar. Sin embargo, reunimos valores de tiempo de respuesta a cada minuto y en una hora de observación tendremos 60 posiciones, probablemente, variadas.
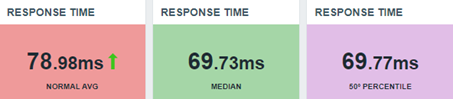
¿Y si la idea del 51º percentil nos pudiera ofrecer el segundo valor para poder calcular la mediana? Fantástico. Nuevamente, un Calculated item:
(last(//percentile.50.input.values)+last(//percentile.51.input.values))/2
Esta es la fórmula de nuestra mediana, si no queremos arriesgarnos en usar el 50º percentil. Entonces, usando los mismos 10 valores del ejercicio anterior, veamos el resultado:
Conclusión (parcial)
En este artículo, explotamos un poco de lo mucho que las funciones de Zabbix nos pueden ofrecer y muchas otras métricas e insights se pueden obtener con estudio y dedicación.
El «Analista de Monitoreo» puede convertirse en un genuino «Científico de Datos» en el ámbito de la Tecnología de la Información y de la Comunicación (TIC) y nuestra herramienta de monitoreo favorita nos apoya de diferentes formas.
Comenzamos nuestra serie con preguntas y no todas fueron respondidas. En el próximo artículo, tendremos más respuestas y más insights maravillosos.
No se olvide: las estimaciones alcanzadas con cálculos de promedio, mediana y percentil, no son las únicas formas de llegar a resultados, existen además muchos otros métodos a ser explotados, sin embargo, este es el inicio de nuestro estudio.
_____________
[1] Infográfico Zabbix (unirede.net)
[1] [1] https://www.unirede.net/zabbix-templates-onde-conseguir/
[1] https://www.unirede.net/monitoramento-de-certificados-digitais-de-websites-com-zabbix-agent2/
[1] Tagging: Monitorando todos os serviços! – YouTube
[1] [1] Timeshift – YouTube