Introdução
No artigo anterior, exploramos um pouco dos conceitos utilizados em estatística básica para estimar alguns tempos de respostas de uma aplicação web. Na ocasião, trabalhamos média, mediana e 50º percentil, criando contexto para melhoria do template nativo de monitoramento do nginx e ainda, exibimos os resultados instigantes em alguns dashboards. Vamos dar continuidade ao nosso trabalho, desta vez, analisando a variabilidade dos valores coletados durante o monitoramento.
Como este artigo é continuidade de outro, recomendamos a leitura do anterior antes de seguir com esta. Vamos em frente. Desejo a você uma excelente leitura.
Um pouco de estatística básica
Em estatística, uma distribuição de dados possui ao menos 4 momentos:
- Estimativas de localização
- Variabilidade
- Assimetria
- Curtose
No artigo anterior, introduzimos o 1º momento, conhecendo um pouco das Estimativas de Localização da nossa distribuição de dados, ou seja, analisamos alguns valores dos tempos de resposta da nossa aplicação web. Entendemos então que os tempos de resposta possuem valores mínimos, máximos, médios, podendo ou não serem influenciados pelos outliers, ou seja, pelos picos de um tempo de resposta muito bom ou muito ruim. Concluímos temporariamente que os tempos de resposta são variados, mas podemos conhecer um pouco mais sobre essas variações. Vamos então entrar no 2º momento de uma distribuição de dados: a variabilidade.
Variabilidade
Na certeza de que nossos tempos de resposta são variáveis na maioria das vezes, ou seja, assimétricos, quais indicadores dessa variabilidade podemos conhecer ou trabalhar? Quais deles são de fato importantes para nós? O que eles nos dizem?
Em uma análise exploratória de dados, passamos a conhecer esses indicadores (dentre outros), mesmo que alguns deles não façam sentido no final (dependendo da sua aplicação). Sim! Há casos em que os indicadores podem não fazer sentido para nossa análise por termos outros pontos a considerar ou ainda, um contexto (ou a falta dele) para nos ajudar a compreender melhor seus resultados.
Vamos trabalhar alguns:
- Variância
- Desvio-padrão
- Desvio Absoluto Médio da Mediana (MAD)
- Amplitude
- Amplitude Interquartil – IQR
Amplitude
O conceito de amplitude é simples e sua fórmula também: é a diferença entre o maior e o menor valor. Nesse caso, estamos falando de uma distribuição de dados que reflete o período da hora anterior, por exemplo (,1h:now/h), e nos interessa saber a amplitude da variação dos tempos de resposta da aplicação web.
Para representar o cálculo da amplitude no template “Nginx by HTTP modifided”, crie o seguinte Calculated item:
- trendmax(//net.tcp.service.perf[http,”{HOST.CONN}”,”{$NGINX.STUB_STATUS.PORT}”],1h:now/h)
- trendmin(//net.tcp.service.perf[http,”{HOST.CONN}”,”{$NGINX.STUB_STATUS.PORT}”],1h:now/h)
Desconsiderando o template e a aplicação web, a amplitude pode ser representada pela seguinte fórmula:
- max(/host/key)-min(/host/key)
Porém, estamos analisando uma distribuição de dados considerando apenas a hora anterior, logo:
- trendmax(/host/key,1h:now/h)-trendmin(/host/key,1h:now/h)
O restante das alterações está considerando o uso do template “Nginx by HTTP modified”.
Alterando nosso dashboard, teremos a seguinte visão:
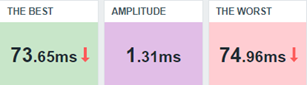
A interpretação desse resultado pode ser a seguinte: entre o pior tempo de resposta e o melhor, a variação é muito pequena, o que leva a entender que durante aquela hora, os tempos de resposta se mantiveram bons, à princípio.
Porém, apenas a amplitude não deve bastar para diagnosticar a aplicação web naquele momento. É preciso combinar esse resultado com outros que veremos a seguir.
Contudo, podemos criar triggers que avaliem esse indicador, como:
- Se na hora anterior a amplitude do tempo de resposta for maior que 5 segundos, a aplicação web pode não ter respondido bem às requisições feitas a ela.
- Expression = last(/Nginx by HTTP modified/amplitude.previous.hour)>5
- Level = Information
- Se a amplitude for maior que 5 por 3 vezes consecutivas, isso pode significar que constantemente a aplicação web tem sofrido com a performance e algo precisa ser investigado, pois não é normal que haja tamanha variação tantas vezes, hora após hora.
- Expression = min(/Nginx by HTTP modified/amplitude.previous.hour,#3)>5
- Level = Warning
Lembrando que, se estamos avaliando a hora anterior, não faz sentido que a coleta ocorra a cada minuto. Um agendamento deve ser usado para que a métrica seja gerada uma única vez, sempre referente à hora anterior.
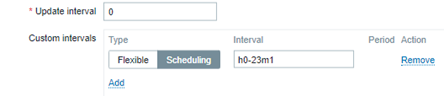
Assim, as expressões das triggers também vão avaliar os valores da forma correta e o flapping será evitado.
Amplitude Interquartil – IQR
Considere os seguintes valores como exemplo:
3, 5, 2, 1, 3, 3, 2, 6, 7, 8, 6, 7, 6
Crie o arquivo vaules.txt em seu servidor web e insira cada um deles em uma linha. Leia o arquivo:
# cat values.txt
3
5
2
1
3
3
2
6
7
8
6
7
6
Agora, envie ao Zabbix com Zabbix sender.
# for x in `cat values.txt`; do zabbix_sender -z 127.0.0.1 -s “Web server A” -k input.values -o $x; done
Veja no frontend do Zabbix o histórico dos valores.
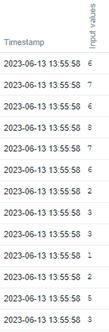
Agora, vamos criar os Calculated items para 75º percentil e 25º percentil.
- Key: iqr.test.75
Formula: percentile(//input.values,#13,75)
Type: Numeric (float) - Key: iqr.test.25
Formula: percentile(//input.values,#13,25)
Type: Numeric (float)
Se aplicássemos no terminal do Linux o comando “sort values.txt”, teríamos a numeração em ordem crescente sendo exibida. Vamos trabalhar com este conceito:
# sort values.txt
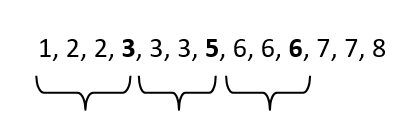
Da esquerda para a direita, avance até a 25º percentil. Você terá o número 3.
Desta vez, avance até o 50º percentil. Você terá o número 5.
Desta vez, avance até o 75º percentil. Você terá o número 6.
O IQR é a diferença entre o 75º percentil (Q3) e o 25º percentil (Q1). Assim, excluiremos valores à esquerda (menores) e à direita (maiores). Essa será a variabilidade entre quantis.
Para calcular o IQR no Zabbix, neste caso, faça:
- key: iqr.test
Formula: last(//iqr.test.75)-last(//iqr.test.25)
Agora, aplicaremos o conceito no tempo de resposta da aplicação web.
Item calculado para 75º percentil:
key: percentile.75.response.time.previous.hour
Formula: percentile(//net.tcp.service.perf[http,”{HOST.CONN}”,”{$NGINX.STUB_STATUS.PORT}”],1h:now/h,75)
Item calculado para 25º percentil:
key: percentile.25.response.time.previous.hour
Formula: percentile(//net.tcp.service.perf[http,”{HOST.CONN}”,”{$NGINX.STUB_STATUS.PORT}”],1h:now/h,25)
Item calculado para o IQR – Amplitude Interquartil
key: iqr.response.time.previous.hour
Formula: last(//percentile.75.response.time.previous.hour)-last(//percentile.25.response.time.previous.hour)
Mantenha o agendamento para o minuto 1 de cada hora, para evitar que o mesmo valor seja gerado mais de uma vez desnecessariamente e ajuste o dashboard.

Note que a AMPLITUDE, considerando o pior e o melhor tempo resposta da hora anterior, traz um valor significativamente “maior”, se comparado ao IQR. Isso porque no neste último (IQR), descartamos os valores muito pequenos e os muito grandes (outliers) e refizemos o cálculo. Então, assim como existe a média que é influenciada pelos valores muito maiores ou muito menores, existe a mediana, que representa um valor central e não é sensível aos extremos. Também podemos afirmar que a amplitude é sensível aos extremos, porém, o IQR é um indicador robusto, por não sofrer influência dos outliers.
Observação: estamos considerando apenas a hora anterior, porém, tente imaginar se fizemos os cálculos de IQR para todo um dia. Tente aplicar o que vimos, porém, com o time shift 1d:now/d e veja os indicadores do dia anterior.
Variância
A variância é uma forma de calcular a dispersão de dados, considerando sua média. No Zabbix, calcular a variância é simples, uma vez que existe uma fórmula específica para isso, através de um Calculated item.
A fórmula é a seguinte:
- Key: varpop.response.time.previous.hour
Formula: varpop(//net.tcp.service.perf[http,”{HOST.CONN}”,”{$NGINX.STUB_STATUS.PORT}”],1h:now/h)
Neste caso, o valor retornado pela fórmula indica a dispersão dos dados, porém, há uma característica na variância: em algum momento, eleva-se ao quadrado os valores para se alcançar o resultado, o que altera a escala dos valores os quais estamos observando na distribuição.
O que a fórmula acima faz, pode ser resumida nos seguintes passos:
1º passo) Calcular a média dos dados;
2º passo) Subtrair a média de cada observação;
3º passo) Elevar ao quadrado cada um dos resultados das subtrações;
4º passo) Somar todos os quadrados calculados no passo 3;
5º passo) Dividir o resultado da soma pelo total de observações.
No passo 3, temos a alteração da escala. No entanto, a medida de dispersão ainda é muito utilizada e pode ser útil para outros tipos de cálculos no futuro.
Desvio-padrão
É a raiz quadrada da variância.
Note que, se em algum momento a variância foi obtida com a elevação de valores ao quadrado, agora, podemos voltar à escala original dos dados observados.
Existem ao menos 2 formas de se fazer isso:
- Utilizar a fórmula para extrair a raiz quadrada da variância:
- Key: varpop.previous.hour
- Formula: sqrt(last(//varpop.response.time.previous.hour))
- A outra, é usar chaves específicas da versão 6.0 para esse tipo de cálculo, com base na população total dos dados, ou apenas em uma amostra:
- tddevpop
- stddevsamp
Uma maneira fácil de entender o conceito do desvio-padrão é: considerando os valores de uma distribuição, o quão longe da média eles estão? Então, ao aplicar uma fórmula específica, chegaremos nesse indicador.
Veja:
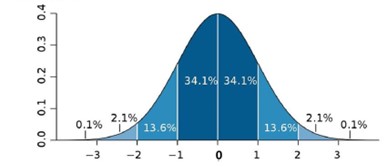
Esta é uma imagem comum encontrada na Internet e nos ajuda a interpretar alguns resultados, sendo o mais básico deles, o seguinte: Quanto mais longe de zero o desvio estiver, mais longe da média nossos valores estarão. Quanto mais próximo de zero, mais próximo à média os valores estarão, logo, não haverá um grande desvio.
Considere o seguinte Calculated item:
- stddevpop(//net.tcp.service.perf[http,”{HOST.CONN}”,”{$NGINX.STUB_STATUS.PORT}”],1h:now/h)
Estamos calculando o desvio-padrão de todos os valores coletados na hora anterior, para avaliarmos se os valores estão muito longe de sua média, ou próximos a ela. O resultado:
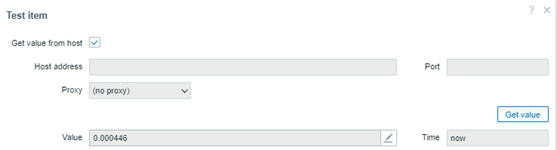
Considere que o valor não chega a retornar 1. Ele se mantém em 0.000446. Se não chega a ter um desvio, significa que a variabilidade dos tempos de resposta da hora anterior em nossa aplicação web pode estar com uma assimetria baixa ou moderada, que não há tantos picos (outliers) e que tudo pode estar correndo como esperado. Contudo, ainda é preciso avaliar outras métricas antes de dar um diagnóstico.
Observações importantes sobre o desvio-padrão:
- É sensível aos outliers
- Pode ser calculado com base em todos os valores de uma distribuição (população) ou ainda, com base em uma amostragem
- Utiliza-se a fórmula: stddevsamp. Neste caso, pode retornar um valor diferente da outra fórmula.
Desvio Absoluto Médio da Mediana (MAD)
Assim como o desvio-padrão, o MAD nos ajuda a entender se os valores de uma distribuição estão afastados de sua mediana. A boa notícia é que este indicador de desvio não considera os outliers, logo, é uma estimativa robusta.
Atenção: se um dos seus objetivos for identificar outliers ou considerá-los durante a análise, a função MAD não é recomendada, justamente por ignorá-los.
Vejamos como ficaria nosso dashboard com algumas funções de variabilidade as quais estamos estudando:
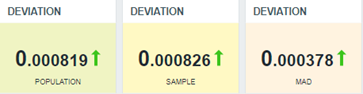
Perceba que a última é baseada em MAD e por isso tende a ter um valor de desvio menor que as duas primeiras, pois não está considerando os valores das extremidades (maiores e menores). Neste caso, ainda assim, não temos um desvio. À princípio, nossa aplicação web está mantendo os tempos de resposta dentro da média.
Dashboard Exploratório
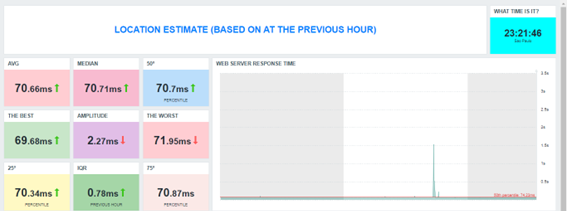
Conclusão (parcial)
Neste artigo, continuamos os estudos sobre os momentos de uma distribuição de dados, introduzindo o conceito de variabilidade e algumas das técnicas utilizadas para encontrar indicadores.
Sabemos que os tempos de reposta de uma aplicação web podem variar (certamente serão bem diferentes um do outro ao longo de um período) e o estudo desta variabilidade, pode nos ajudar a compreender se esta aplicação, em específico, está ou não tendo uma boa performance.
Claro, este é um exemplo puramente didático e o conceito de distribuição de dados, estimativas de localização e variabilidade podem ser empregados para análise exploratória de dados considerando um período mais longo, como dias, semanas, meses e anos. Neste caso, é imprescindível o uso de trends ou invés de history.
Nosso objetivo é trazer à luz alguns dados para além dos mais óbvios, nos permitido conhecer melhor nossa aplicação.
Nos próximos artigos, falaremos de assimetria e curtose, os 3º e 4º momentos de uma distribuição, respectivamente.