




Running a monitoring platform like Zabbix in a production environment demands reliability and resilience. When your monitoring solution is down, you’re flying blind – and for many organizations, that simply isn’t acceptable. This post introduces a robust high-availability (HA) architecture for Zabbix, using PostgreSQL, Patroni, etcd, HAProxy, keepalived and PgBackRest. Built on RHEL 9 or derrivates, this solution combines modern open-source tools to provide automatic failover, load balancing, and seamless monitoring, all while maintaining consistency and performance.
Architecture overview
The HA design consists of multiple layers working in tandem to maintain continuity even during node or service failures:
Database Cluster Layer
2 or more nodes form the PostgreSQL cluster, managed by Patroni and coordinated using etcd. At any given time, one node is the primary (read/write), and the others are hot standbys ready to take over automatically.
Consensus layer
etcd runs on the same nodes and acts as the distributed configuration store and coordination layer for Patroni. It ensures a consistent cluster state and enables safe failover decisions.
Load balancing layer
Two HAProxy nodes provide a single point of entry for all clients (including Zabbix), routing requests to the current PostgreSQL primary. These nodes are monitored and coordinated via Keepalived to maintain a floating Virtual IP (VIP), ensuring seamless failover at the connection layer.
Backup layer
A separate backup server is responsible for running PgBackRest, which handles full and incremental backups, WAL archiving, and Point-In-Time Recovery (PITR). This server communicates securely with all database nodes over SSH.
Monitoring layer
Two Zabbix servers, running in active-passive mode, continuously monitor all layers of this stack including the HAProxy health, Patroni cluster role, and etcd status by accessing the PostgreSQL VIP for backend connectivity.
This multi-tiered setup ensures that no single failure be it a database, load balancer, or monitoring server brings down the monitoring platform.
Why HA matters for Zabbix
Zabbix depends heavily on its PostgreSQL database backend. Every metric, trigger, event, and alert is stored there. If PostgreSQL becomes unavailable, even briefly, data loss or monitoring blind spots can occur. That’s why introducing HA at the database layer is a crucial step when scaling Zabbix for enterprise environments.
While Zabbix itself supports HA at the application level, this architecture ensures that the database backend is also fully fault-tolerant, using modern consensus-based clustering with automatic failover.
Component overview
To achieve HA, we bring together several specialized components, each fulfilling a critical role in the system:
PostgreSQL
The relational database engine used by Zabbix. In this example setup, it runs on three nodes, forming a cluster managed by Patroni.
Patroni
Patroni is the orchestrator for the PostgreSQL cluster. It monitors node health, manages replication, promotes standbys when needed, and ensures only one writable leader exists at any time. Patroni leverages a distributed consensus store in this case, etcd but other DCS’s are possible to coordinate decisions across the cluster.
etcd
etcd is a lightweight and highly available key-value store used by Patroni to maintain the cluster’s state. It stores leader election data, health statuses, and locks. We deploy it as a three-node cluster, co-located with the PostgreSQL nodes for convenience, though this setup can be scaled independently if needed as etcd is very latency prone.
HAProxy
To simplify application connectivity, HAProxy acts as a load balancer in front of the database cluster. It monitors the role of each node using Patroni’s REST API and routes connections to the active primary server. If the leader fails, HAProxy automatically reroutes traffic to the new primary.

Keepalived
Keepalived provides a floating virtual IP address (VIP) across the HAProxy nodes. This VIP allows client systems, such as the Zabbix frontend, to connect to a single stable IP even if one HAProxy node fails.
PgBackRest
To protect the data itself, we use PgBackRest for full and incremental backups, as well as Point-In-Time Recovery (PITR). A dedicated backup server is included to pull and store archive logs and backups securely via SSH.
Zabbix server
Finally, we run two Zabbix servers in active-passive mode. Both are configured to connect to the PostgreSQL cluster through the VIP exposed by HAProxy. The Zabbix frontend is deployed on both nodes as well, ensuring continued accessibility through the load-balanced setup.
Topology at a glance
Here’s a simplified view of the architecture:
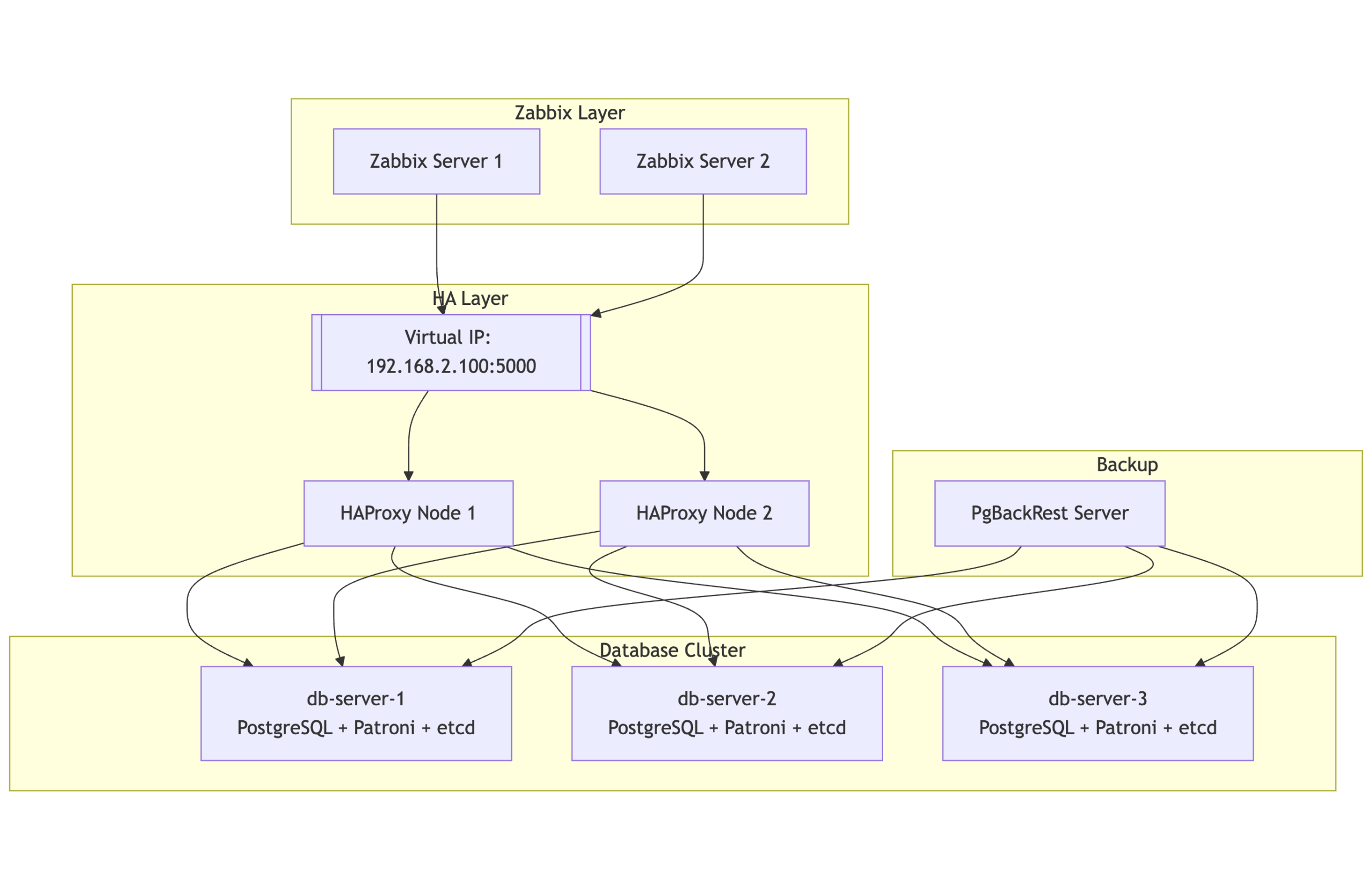
- 2 or more database nodes (PostgreSQL + Patroni + etcd)
- Two HAProxy nodes, each configured with Keepalived to manage a floating virtual IP
- One backup node for PgBackRest
- Two Zabbix servers pointing to the PostgreSQL VIP
All systems are tied together with consistent hostname mappings, time synchronization (Chrony), and service monitoring.
Notes:
- PgBackRest is directly connected to all three PostgreSQL nodes, allowing it to archive WAL segments and pull backups regardless of which node is primary.
- This design enables full standby backups and supports Point-In-Time Recovery (PITR).
- HAProxy ensures Zabbix always talks to the current primary node, while Patroni and etcd handle automatic failover and cluster state management.
Design rationale
This setup prioritizes resilience and self-healing. If any single component fails a database node, a load balancer, or even a monitoring server the system continues to function.
Using Patroni with etcd ensures that failovers are handled automatically, without human intervention. HAProxy ensures client traffic is always routed to the current primary, while Keepalived ensures that this routing layer itself is highly available.
We opted for PgBackRest over simple scripts or base backups because it provides not just efficient incremental backups, but also full WAL archiving and point-in-time recovery, which are invaluable for both disaster recovery and debugging.
Lastly, we chose to integrate Zabbix itself into this HA design, treating it not just as a application but as a fully resilient service able to monitor itself, so to speak.
Real-world considerations
- Resource planning: While our nodes run comfortably, scaling this setup to heavy workloads requires careful tuning of memory, I/O, and PostgreSQL parameters.
- etcd placement: Although we run etcd co-located with the database nodes in this example, separating etcd onto dedicated infrastructure is ideal for large-scale environments. This avoids resource contention and preserves quorum in extreme failure scenarios.
- Monitoring the monitors: Zabbix itself must be monitored. In our setup, each component including etcd, Patroni, and PostgreSQL exposes health endpoints that can be used by Zabbix agents or scripts to generate alerts on replication lag, cluster health, and failover events.
Conclusion
This architecture provides a solid foundation for running Zabbix in a fault-tolerant, production-ready environment. It not only ensures high availability for the database layer but also offers flexibility, observability, and operational safety.
Whether you’re running internal infrastructure monitoring or offering Zabbix as a managed service, adopting this type of HA setup removes single points of failure and gives you peace of mind — all using open-source technologies that are battle-tested and widely supported.
If you need assistance with the migration or want to ensure best practices for scaling and optimizing Zabbix, don’t hesitate to reach out to OICTS. We are a Zabbix Premium Partner operating globally, with offices in the USA, UK, Netherlands, and Belgium, and we’re ready to help you every step of the way.





Thank you Patrik for sharing such valuable insights.
I have a question regarding Keepalived functionality, specifically the use of standard VRRP (broadcast/multicast) to manage a floating IP in a public cloud environment.
In Azure VMs, there currently isn’t a native mechanism to seamlessly move or reassign a floating IP between hosts. This creates a single point of failure (SPOF) in setups using HAProxy with Keepalived.
Could you please share how you are planning to mitigate this limitation in Azure? Are there alternative approaches or design patterns you would recommend to achieve high availability in this scenario?
Looking forward to your thoughts.