




When you have devices spread across different locations and monitor these with a single Zabbix instance, you’ll encounter a challenge managing the various latencies to each location, especially when these locations span the world. Ping times can vary wildly from 10ms to 500ms and more depending on the internet connections.
Flexible latency threshold with User macros
Setting the max latency for all devices at 500ms isn’t really a good option, and overriding the {$ICMP_RESPONSE_TIME_WARN} for each individual device doesn’t scale well.
There is a better way though.
First move the {$ICMP_RESPONSE_TIME_WARN} macro from the “Template Module ICMP Ping” into a global macro (with the default value of 0.15, which is 150ms) and remove the macro from the template.
You can find global variables in the “Administration->General” menu. Click on the “GUI” dropdown and select “Macros”.

Then create templates for each location and set a custom {$ICMP_RESPONSE_TIME_WARN} macro (overriding the global macro) based on what was best for that particular location.
Lastly, add all devices for a location to the template for that location.
Now when a new device is added to a location, all that is needed is to add it to the correct template. An added benefit is that when the latency changes, changing the macro in the affected template changes the response time for every device that relies on that template.
Defining dependencies
Because networks often work as a tree structure, using dependencies can help suppress alerts for devices downstream. However, Zabbix’s dependency structure isn’t very intelligent. If an upstream device is checked just before an issue occurs, then a downstream device might hit
the 3 failed checks before the upstream device does, and alert. This can lead to many alerts even though Zabbix might suppress most of these alerts on the dashboard once it detects the upstream device is offline too.
Every network is different and this approach may need some tweaking for your network, but in our case, each remote location has a firewall that Zabbix pings, a switch that connects to that firewall, hosts that connect to the switch, and in some cases VM’s that reside on a host.
Each firewall has an external and internal interface that we monitor separately (if the internal interface is down, but the external interface up, that means something happened to the connected switch), and we monitor each.
So, we created a concept of “ICMP rings”.
The four rings
Zabbix pings the external interface of a remote firewall every 60s (default ICMP update interval). We’ll call this “Ring 0”. The internal Firewall interface is dependent on the external interface, This internal interface sits in “Ring 1”. Usually, the next device is a switch, which is dependent on the internal firewall, This switch lives in “Ring 2”. Hosts that we want to monitor on the remote network are dependent on the switch, and therefore live in “Ring 3”. We also have remote VM’s which exist on a remote host, and these live in “Ring 4”.
In each ring we increase the update interval time.
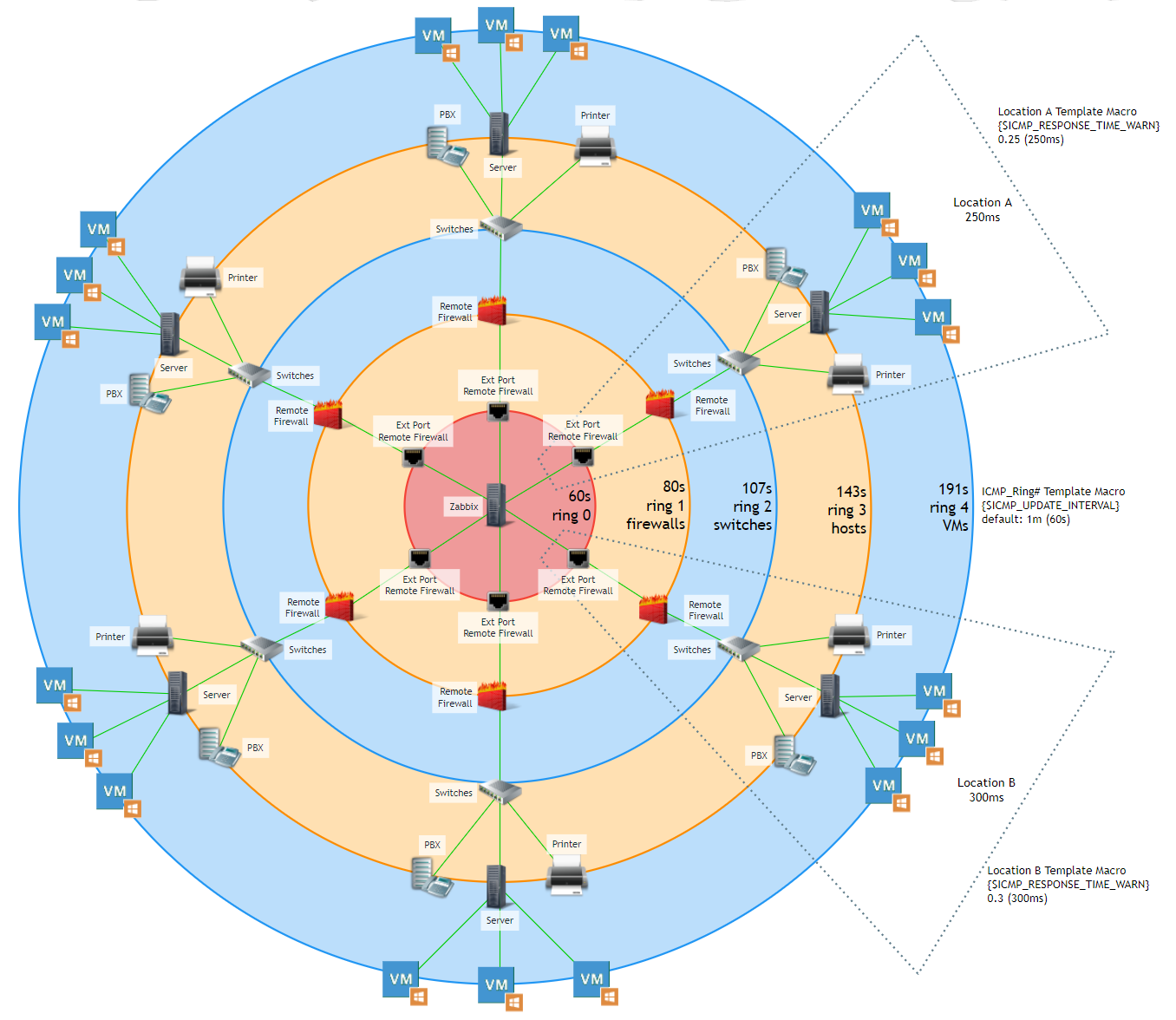
This means the further downstream a device is, the longer it takes to detect an outage.
But the upshot is that we won’t get alert storms any more.
First move the {$ICMP_UPDATE_INTERVAL} macro from the “Template Module ICMP Ping” to a global macro (with a value of 1m) and created templates called:
ICMP_Ring1_FW
ICMP_Ring2_SW
ICMP_Ring3_Hosts
ICMP_Ring4_VMs
Each Ring template has a macro {$ICMP_UPDATE_INTERVAL} set (overriding the global macro) with the below values for each ring.
ring 0 = 60s
ring 1 = 80s
ring 2 = 107s
ring 3 = 143s
ring 4 = 191s
These are not random. In order to always have an upstream device alert before a downstream device you need to take the update interval time (seconds) of the upstream ring, multiply it by its intervals+1, and then divide it by three (and round it off).
The resulting update interval will ensure an upstream device always alerts before a downstream device. The downside of this approach is that the further downstream a device is, the longer it takes to detect a problem.
(This could be mitigated by using a Zabbix proxy, but we’re working with a single instance).
🤔 How did I get to this formula? That’s pretty simple. Consider a firewall and switch, where the switch is dependent on the firewall. Now lets assume seconds after the firewall is checked (and found responsive), the link goes down. Seconds later the switch is checked, and found unresponsive. Strike one for the switch. Now the firewall is checked again, and is now unresponsive too. Strike one for the firewall. Next the switch is checked again, and its strike two. By the time the firewall hits strike 3, the switch is already well and truly alerting.
To allow the firewall to be checked 3 times we need to check the switch 4 times. We could simply increase the interval for every subsequent ring, but that’s not as efficient (we’d be adding 60s every time we increase the interval).
Rather, we can work with the seconds. 4 x 60 seconds equals 240 seconds. Divide that by 3 intervals (for the next ring) and that results in 80 seconds. If we check the switch every 80ms, that totals to 240s. We could add 1 or 2 seconds margin, to ensure the firewall has some extra time, but every second we add, we also need to add to subsequent downstream rings. Which means the time we need to detect issues becomes longer and longer.
In Zabbix version 5.0 The url https://zabbix/triggers.php isn’t available via the menu, but it allows you to filter triggers, for instance all ICMP unavailable triggers, and see what each is dependent on. We use host groups to set locations for devices, and combining a location host group with an ICMP unavailable trigger allows to quickly review whether dependencies are (correctly) set, and if so to what. In later versions this link will not work, since it now requires a context in the URL.






Great post! Thanks for your help on this!
Excellent article and very helpful. Thank you