




In this blog post, you will learn how to set up MySQL partitioning using existing community resources. If you wish to learn more about Zabbix MySQL database partitioning, check out this blog post for an extensive guide below.
This guide is meant to work for all most prominent MySQL features including MySQL 8, MariaDB or other MySQL forks. So whichever version or type you are running, this guide should be able to get you up and running.
Contents
- Introduction
- How to
- Partitioning the database
- Setting up the Perl script
- Using stored procedures
- Disable Zabbix housekeeper
- Conclusion
For a video guide, check out the Zabbix YouTube here: https://youtu.be/KbwIoPasMYI
Introduction
Zabbix housekeeper can’t clean up your old data efficiently enough once your server reaches a certain size, which makes sense. Zabbix housekeeper is built to go through your database and search for a row older than the time defined in your Zabbix frontend and then delete that row. It has to do this for every single history or trend data entry, which results in a slow performing process once you have a fairly large MySQL database. We can see an indicator of this happening in the following screenshot:
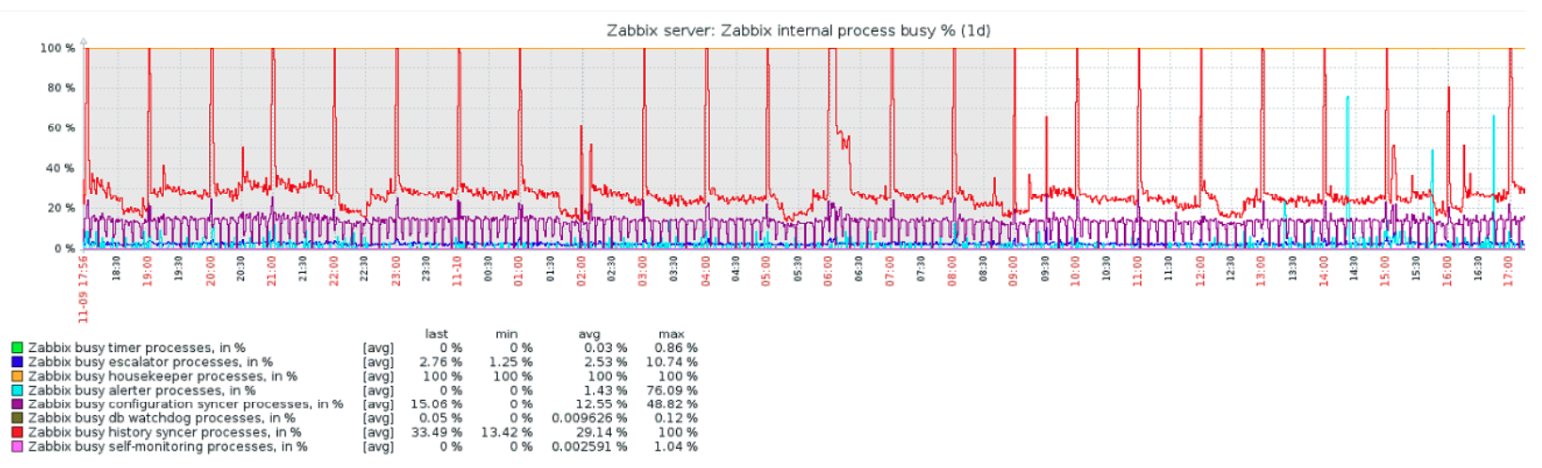
You could see that your Zabbix housekeeper process will be busy all the time and that your database is filling up constantly. A solution built natively into Zabbix for PostgreSQL is TimescaleDB, but unfortunately there’s no such built in feature for MySQL. There is however the amazing solution of MySQL partitioning, which we’ll run through in this blogpost.
MySQL partitioning is the process of dividing your database into time based chunks. This will make it possible to easily drop an entire partition once it has become too old according to the partition retention period that we’ve specified. This is a lot faster than going through data line by line as the built-in Zabbix housekeeper does
So let’s waste no more time and let’s get started!
If you are looking for an extensive guide on this and many more Zabbix implementations like this check out our Zabbix book here:
https://www.thezabbixbook.com/ch01-zabbix-components/partitioning-database/
If you are interested in more resources like this one, check out our GitHub here:
https://github.com/OpensourceICTSolutions/
How to
Now to make this all possible we are going to need to login to our Zabbix database server and partition the database. Before doing so make sure to stop the Zabbix server process or make a copy of your database and partition the database on a different server. If you don’t know how to do this, read the documentation on doing a MySQL dump and MySQL import:
https://mariadb.com/kb/en/mysqldump/
https://mariadb.com/kb/en/mariadb-import/
Whichever method you’ll use ALWAYS make sure to make a backup of your database. Although rare, data corruption is always a possibility when performing large scale changes on your DB.
To prevent MySQL running out of space, also make sure to have a generous amount of free space on your system. Running partitioning when you have a full storage space could lead to corrupted database data. Check your free space with:
df -h
Partitioning the database
Once you have stopped your Zabbix server or once you’ve imported your database backup to a different server we can start the partitioning process. Before doing anything, please note that creating partitions can be a VERY time consuming process, consisting of several days on big databases. Make sure to run the commands for partitioning in a tmux session. Install tmux with:
dnf install tmux
or on Debian based systems
apt-get install tmux
Now we can issue the tmux command to open a new tmux session:
tmux
Which will open a terminal for us that will remain active even if our SSH session times out. Now we are ready to partition.
We’ll be partitioning the following tables:
| Table name | Purpose | Data type |
|---|---|---|
| history | Keeps raw history | Numeric (float) |
| history_uint | Keeps raw history | Numeric (unsigned) |
| history_str | Keeps raw short string data | Character |
| history_text | Keeps raw long string data | Text |
| history_log | Keeps raw log strings | Log |
| history_bin | Keeps binary data in this table | Binary |
| trends | Keeps reduced dataset (trends) | Numeric (float) |
| trends_uint | Keeps reduced dataset (trends) | Numeric (unsigned) |
To start partitioning let’s login to MySQL with:
mysql -u root -p
Because partitioning is a time based process we are going to need to know the oldest data entry for each of the tables above. We’ll need to issue a command for all of them, so let’s do that first with:
SELECT FROM_UNIXTIME(MIN(clock)) FROM history_uint;
Issue the same command for all tables, changing history_uint to the respective table name. After issuing the commands write down the output for each of the tables, we will need this to define our partitions. The output will give you back a timestamp, which will be the earliest partition we need to create. In this example I’ll use the timestamp 19-12-2020, so exactly 2 months ago at the time of writing this post on 19-02-2021.
Now we will need to prepare our partitioning command. Our history tables will be partitioned by day and our trends tables will be partitioned by month.
Then let’s start with our history_uint table:
ALTER TABLE history_uint PARTITION BY RANGE ( clock) (PARTITION p2020_12_19 VALUES LESS THAN (UNIX_TIMESTAMP("2020-12-20 00:00:00")) ENGINE = InnoDB, PARTITION p2020_12_20 VALUES LESS THAN (UNIX_TIMESTAMP("2020-12-21 00:00:00")) ENGINE = InnoDB, PARTITION p2020_12_21 VALUES LESS THAN (UNIX_TIMESTAMP("2020-12-22 00:00:00")) ENGINE = InnoDB, PARTITION p2020_12_22 VALUES LESS THAN (UNIX_TIMESTAMP("2020-12-23 00:00:00")) ENGINE = InnoDB, … PARTITION p2021_02_18 VALUES LESS THAN (UNIX_TIMESTAMP("2021-02-19 00:00:00")) ENGINE = InnoDB, PARTITION p2021_02_19 VALUES LESS THAN (UNIX_TIMESTAMP("2021-02-20 00:00:00")) ENGINE = InnoDB, PARTITION p2021_02_20 VALUES LESS THAN (UNIX_TIMESTAMP("2021-02-21 00:00:00")) ENGINE = InnoDB, PARTITION p2021_02_21 VALUES LESS THAN (UNIX_TIMESTAMP("2021-02-22 00:00:00")) ENGINE = InnoDB, PARTITION p2021_02_22 VALUES LESS THAN (UNIX_TIMESTAMP("2021-02-23 00:00:00")) ENGINE = InnoDB);
Make sure to add a partition for every day – that’s what the ellipsis signifies here (…)
You can see that we used our earliest timestamp of 19-12-2020 to define our first partition. Our last partition is a bit in the future ending on 22-12-2020. This is how we define our partitions range. Make sure to do the same thing using your own timestamp which you collected in the first step after logging in to MySQL. Keep in mind! This might be different for each table.
Apply the same process to each of your history tables before moving on the trends tables. Tip: Make a text note to prepare all commands using the guide before executing anything. It make it a lot easier to do this.
For our trends tables we will still work with the collected timestamp of 19-12-2020. Basically what we want is all data in the month of December 2020 upwards. The partition statements will look like this for the trends_uint table:
ALTER TABLE trends_uint PARTITION BY RANGE ( clock)
(PARTITION p2020_10 VALUES LESS THAN (UNIX_TIMESTAMP("2020-11-01 00:00:00")) ENGINE = InnoDB,
PARTITION p2020_11 VALUES LESS THAN (UNIX_TIMESTAMP("2020-12-01 00:00:00")) ENGINE = InnoDB,
PARTITION p2020_12 VALUES LESS THAN (UNIX_TIMESTAMP("2021-01-01 00:00:00")) ENGINE = InnoDB,
PARTITION p2021_01 VALUES LESS THAN (UNIX_TIMESTAMP("2021-02-01 00:00:00")) ENGINE = InnoDB,
PARTITION p2021_02 VALUES LESS THAN (UNIX_TIMESTAMP("2021-03-01 00:00:00")) ENGINE = InnoDB,
PARTITION p2021_03 VALUES LESS THAN (UNIX_TIMESTAMP("2021-04-01 00:00:00")) ENGINE = InnoDB);
As you can see, here we are partitioning by month instead of by day, which makes sense in case of our trends tables. Do not forget to do this for all our trends tables, which are the trends and trends_uint tables using your respective collected timestamp.
After preparing this MySQL query command for each table you can now put them into your MySQL terminal table by table. Please do not forget to use the tmux command as mentioned earlier and bring some patience, it can take a few days per table for bigger databases, which is why I always recommend setting up partitioning BEFORE going live with a new Zabbix setup.
Setting up the Perl script
Partitioning is not everything though, we still need to maintain the partitioned setup. MySQL will not create new partitions for us automatically, we need to automate this. The best way to do this is by using the publicly available Perl script. We are not sure who wrote this one, but you can find it on our GitHub repository:
https://github.com/OpensourceICTSolutions/zabbix-mysql-partitioning-perl
Download the script from our GitHub and save it on your Zabbix database server in the following folder:
/usr/lib/zabbix/
Then make the script executable with:
chmod 750 /usr/lib/zabbix/mysql_zbx_part.pl
Next, we need want to edit it with the following command (yes you can also use nano):
vim /usr/lib/zabbix/mysql_zbx_part.pl
There’s a few lines here we want to edit. First our MySQL/login details:
my $dsn = 'DBI:mysql:'.$db_schema.':mysql_socket=/var/lib/mysql/mysql.sock'; my $db_user_name = 'zabbix'; my $db_password = 'password';
Change them to your respective use on your server. The username and password can (for example) be the same credentials you’ve specified in your Zabbix server configuration file. Also keep in mind you might have your MySQL socket in a different location. In that case change “/var/lib/mysql/mysql.sock” to the correct MySQL socket path. This is often the case on Ubuntu servers where to path might be “/var/run/mysqld/mysql.sock”.
Second we need to edit the amount of time we want to save our data for is defined in the following lines:
my $tables = { 'history' => { 'period' => 'day', 'keep_history' => '60'},
'history_log' => { 'period' => 'day', 'keep_history' => '60'},
'history_str' => { 'period' => 'day', 'keep_history' => '60'},
'history_text' => { 'period' => 'day', 'keep_history' => '60'},
'history_uint' => { 'period' => 'day', 'keep_history' => '60'},
'history_bin' => { 'period' => 'day', 'keep_history' => '60'},
'trends' => { 'period' => 'month', 'keep_history' => '12'},
'trends_uint' => { 'period' => 'month', 'keep_history' => '12'},
Third, change the timezone to the timezone configured on your Zabbix database server. We are located in the Netherlands so we’ve used Europe/Amsterdam.
my $curr_tz = 'Europe/Amsterdam';
In the script we also have some lines that might have to be commented/uncommented in case your are using an older or newer MySQL installation. If you are using MySQL 5.5 and earlier or MySQL 8.x and later make sure to comment the following lines starting at # MySQL 5.6 + MariaDB
# my $sth = $dbh->prepare(qq{SELECT plugin_status FROM information_schema.plugins WHERE plugin_name = 'partition'});
#
# $sth->execute();
#
# my $row = $sth->fetchrow_array();
#
# $sth->finish();
# return 1 if $row eq 'ACTIVE';
#
Uncomment the following for MySQL 5.5 starting at # MySQL 5.5
# my $sth = $dbh->prepare(qq{SELECT variable_value FROM information_schema.global_variables WHERE variable_name = 'have_partitioning'});
#return 1 if $row eq 'YES';
#
If you want to use the script with MySQL 8 or later uncomment the following starting from # MySQL 8.x (NOT MariaDB!)
# MySQL 8.x (NOT MariaDB!)
# my $sth = $dbh->prepare(qq{select version();});
# $sth->execute();
# my $row = $sth->fetchrow_array();
# $sth->finish();
# return 1 if $row >= 8;
#
Keep in mind, ONLY do this if you are using MySQL 5.5 and earlier or MySQL 8.x and later. If you are on MySQL 5.6 or MariaDB do NOT change these lines.
For Zabbix 5.4 and OLDER versions also make sure to uncomment the following line. Do not do this for Zabbix 6.0 and higher though:
# $dbh->do("DELETE FROM auditlog_details WHERE NOT EXISTS (SELECT NULL FROM auditlog WHERE auditlog.auditid = auditlog_details.auditid)");
For Zabbix 6.4 and OLDER versions also make sure to comment the following line. Do not do this for Zabbix 7.0 and higher though:
'history_bin' => { 'period' => 'day', 'keep_history' => '60'},
By default we’ve defined a period of 60 days for history tables and 12 months for trends tables. Change these values to your preferred period of time. Keep in mind, the longer we store History and Trends the bigger our database will be.
Now let’s add a cronjob with:
crontab -e
Then add the following line:
55 22 * * * /usr/lib/zabbix/mysql_zbx_part.pl >/dev/null 2>&1
We also need to install some Perl dependencies with:
dnf install perl-DateTime perl-Sys-Syslog
or on Debian based systems
apt-get install libdatetime-perl liblogger-syslog-perl
That’s it! You are now done and you have setup MySQL partitioning. We could execute the script manually with:
perl /usr/lib/zabbix/mysql_zbx_part.pl
Then we can check and see if it worked with:
journalctl -t mysql_zbx_part
This will give you back a list of created and deleted partitions if you’ve done everything right.
Using Stored Procedures
Please note: You can skip this part if you’ve used the Perl script in the previous step.
Using MySQL stored procedures is another way to make sure our database partitions are created and deleted. Let me start by saying that this method is NOT RECOMMENDED and should only be used by organizations that do not allow any external scripts to be used. It’s a method that is hard to troubleshoot and when it breaks it could give you some real headache.
Nevertheless, at Opensource ICT Solutions we believe in flexibility and providing different solutions, and the option is there to do it. So here’s how:
First we need to login to MySQL with:
mysql -u root -p
Then we need to create our table to manage our partitions with:
CREATE TABLE manage_partitions ( tablename VARCHAR(64) NOT NULL COMMENT ‘Table name’, period VARCHAR(64) NOT NULL COMMENT ‘Period - daily or monthly’, keep_history INT(3) UNSIGNED NOT NULL DEFAULT ‘1’ COMMENT ‘For how many days or months to keep the partitions’, last_updated DATETIME DEFAULT NULL COMMENT ‘When a partition was added last time’,comments VARCHAR(128) DEFAULT ‘1’ COMMENT ‘Comments’, PRIMARY KEY (tablename) ) ENGINE=INNODB;
Then we can create our history information with:
INSERT INTO manage_partitions (tablename, period, keep_history, last_updated, comments) VALUES (‘history’, ‘day’, 60, now(), ‘’); INSERT INTO manage_partitions (tablename, period, keep_history, last_updated, comments) VALUES (‘history_uint’, ‘day’, 60, now(), ‘’); INSERT INTO manage_partitions (tablename, period, keep_history, last_updated, comments) VALUES (‘history_str’, ‘day’, 60, now(), ‘’); INSERT INTO manage_partitions (tablename, period, keep_history, last_updated, comments) VALUES (‘history_text’, ‘day’, 60, now(), ‘’); INSERT INTO manage_partitions (tablename, period, keep_history, last_updated, comments) VALUES (‘history_log’, ‘day’, 60, now(), ‘’); INSERT INTO manage_partitions (tablename, period, keep_history, last_updated, comments) VALUES (‘trends’, ‘month’, 12, now(), ‘’); INSERT INTO manage_partitions (tablename, period, keep_history, last_updated, comments) VALUES (‘trends_uint’, ‘month’, 12, now(), ‘’);
By default we’ve defined a period of 60 days for history tables and 12 months for trends tables. Change this to your preference.
Now we need to add some MySQL tasks to manage our partitions. First we’ll add the task to verify the existence of a required partition:
DELIMITER $$ USE zabbix$$ DROP PROCEDURE IF EXISTS create_next_partitions$$ CREATE PROCEDURE create_next_partitions(IN_SCHEMANAME VARCHAR(64))BEGINDECLARE TABLENAME_TMP VARCHAR(64);DECLARE PERIOD_TMP VARCHAR(12);DECLARE DONE INT DEFAULT 0; DECLARE get_prt_tables CURSOR FOR SELECT `tablename`, `period` FROM manage_partitions; DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = 1; OPEN get_prt_tables; loop_create_part: LOOP IF DONE THEN LEAVE loop_create_part; END IF; FETCH get_prt_tables INTO TABLENAME_TMP, PERIOD_TMP; CASE WHEN PERIOD_TMP = 'day' THEN CALL `create_partition_by_day`(IN_SCHEMANAME, TABLENAME_TMP); WHEN PERIOD_TMP = 'month' THEN CALL `create_partition_by_month`(IN_SCHEMANAME, TABLENAME_TMP); ELSE BEGIN ITERATE loop_create_part; END; END CASE; UPDATE manage_partitions set last_updated = NOW() WHERE tablename = TABLENAME_TMP; END LOOP loop_create_part; CLOSE get_prt_tables; END$$ DELIMITER ;
Now we can add the task to create partitions by day:
DELIMITER $$
USE zabbix$$
DROP PROCEDURE IF EXISTS create_partition_by_day$$
CREATE PROCEDURE create_partition_by_day(IN_SCHEMANAME VARCHAR(64), IN_TABLENAME VARCHAR(64))BEGINDECLARE ROWS_CNT INT UNSIGNED;DECLARE BEGINTIME TIMESTAMP;DECLARE ENDTIME INT UNSIGNED;DECLARE PARTITIONNAME VARCHAR(16);SET BEGINTIME = DATE(NOW()) + INTERVAL 1 DAY;SET PARTITIONNAME = DATE_FORMAT( BEGINTIME, ‘p%Y_%m_%d’ );
SET ENDTIME = UNIX_TIMESTAMP(BEGINTIME + INTERVAL 1 DAY);
SELECT COUNT(*) INTO ROWS_CNT
FROM information_schema.partitions
WHERE table_schema = IN_SCHEMANAME AND table_name = IN_TABLENAME AND partition_name = PARTITIONNAME;
IF ROWS_CNT = 0 THEN
SET @SQL = CONCAT( 'ALTER TABLE `', IN_SCHEMANAME, '`.`', IN_TABLENAME, '`',
' ADD PARTITION (PARTITION ', PARTITIONNAME, ' VALUES LESS THAN (', ENDTIME, '));' );
PREPARE STMT FROM @SQL;
EXECUTE STMT;
DEALLOCATE PREPARE STMT;
ELSE
SELECT CONCAT("partition `", PARTITIONNAME, "` for table `",IN_SCHEMANAME, ".", IN_TABLENAME, "` already exists") AS result;
END IF;
END$$
DELIMITER ;
We’ll also need a task to create partitions by month:
DELIMITER $$
USE zabbix$$
DROP PROCEDURE IF EXISTS create_partition_by_month$$
CREATE PROCEDURE create_partition_by_month(IN_SCHEMANAME VARCHAR(64), IN_TABLENAME VARCHAR(64))BEGINDECLARE ROWS_CNT INT UNSIGNED;DECLARE BEGINTIME TIMESTAMP;DECLARE ENDTIME INT UNSIGNED;DECLARE PARTITIONNAME VARCHAR(16);SET BEGINTIME = DATE(NOW() - INTERVAL DAY(NOW()) DAY + INTERVAL 1 DAY + INTERVAL 1 MONTH);SET PARTITIONNAME = DATE_FORMAT( BEGINTIME, ‘p%Y_%m’ );
SET ENDTIME = UNIX_TIMESTAMP(BEGINTIME + INTERVAL 1 MONTH);
SELECT COUNT(*) INTO ROWS_CNT
FROM information_schema.partitions
WHERE table_schema = IN_SCHEMANAME AND table_name = IN_TABLENAME AND partition_name = PARTITIONNAME;
IF ROWS_CNT = 0 THEN
SET @SQL = CONCAT( 'ALTER TABLE `', IN_SCHEMANAME, '`.`', IN_TABLENAME, '`',
' ADD PARTITION (PARTITION ', PARTITIONNAME, ' VALUES LESS THAN (', ENDTIME, '));' );
PREPARE STMT FROM @SQL;
EXECUTE STMT;
DEALLOCATE PREPARE STMT;
ELSE
SELECT CONCAT("partition `", PARTITIONNAME, "` for table `",IN_SCHEMANAME, ".", IN_TABLENAME, "` already exists") AS result;
END IF;
END$$
DELIMITER ;
Then also a task to verify and delete old partitions:
DELIMITER $$ USE zabbix$$ DROP PROCEDURE IF EXISTS drop_partitions$$ CREATE PROCEDURE drop_partitions(IN_SCHEMANAME VARCHAR(64))BEGINDECLARE TABLENAME_TMP VARCHAR(64);DECLARE PARTITIONNAME_TMP VARCHAR(64);DECLARE VALUES_LESS_TMP INT;DECLARE PERIOD_TMP VARCHAR(12);DECLARE KEEP_HISTORY_TMP INT;DECLARE KEEP_HISTORY_BEFORE INT;DECLARE DONE INT DEFAULT 0;DECLARE get_partitions CURSOR FORSELECT p.table_name, p.partition_name, LTRIM(RTRIM(p.partition_description)), mp.period, mp.keep_historyFROM information_schema.partitions pJOIN manage_partitions mp ON mp.tablename = p.table_nameWHERE p.table_schema = IN_SCHEMANAMEORDER BY p.table_name, p.subpartition_ordinal_position; DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = 1; OPEN get_partitions; loop_check_prt: LOOP IF DONE THEN LEAVE loop_check_prt; END IF; FETCH get_partitions INTO TABLENAME_TMP, PARTITIONNAME_TMP, VALUES_LESS_TMP, PERIOD_TMP, KEEP_HISTORY_TMP; CASE WHEN PERIOD_TMP = 'day' THEN SET KEEP_HISTORY_BEFORE = UNIX_TIMESTAMP(DATE(NOW() - INTERVAL KEEP_HISTORY_TMP DAY)); WHEN PERIOD_TMP = 'month' THEN SET KEEP_HISTORY_BEFORE = UNIX_TIMESTAMP(DATE(NOW() - INTERVAL KEEP_HISTORY_TMP MONTH - INTERVAL DAY(NOW())-1 DAY)); ELSE BEGIN ITERATE loop_check_prt; END; END CASE; IF KEEP_HISTORY_BEFORE >= VALUES_LESS_TMP THEN CALL drop_old_partition(IN_SCHEMANAME, TABLENAME_TMP, PARTITIONNAME_TMP); END IF; END LOOP loop_check_prt; CLOSE get_partitions; END$$ DELIMITER ;
Last but not least, a task to delete designated partitions:
DELIMITER $$
USE zabbix$$
DROP PROCEDURE IF EXISTS drop_old_partition$$
CREATE PROCEDURE drop_old_partition(IN_SCHEMANAME VARCHAR(64), IN_TABLENAME VARCHAR(64), IN_PARTITIONNAME VARCHAR(64))BEGINDECLARE ROWS_CNT INT UNSIGNED;
SELECT COUNT(*) INTO ROWS_CNT
FROM information_schema.partitions
WHERE table_schema = IN_SCHEMANAME AND table_name = IN_TABLENAME AND partition_name = IN_PARTITIONNAME;
IF ROWS_CNT = 1 THEN
SET @SQL = CONCAT( 'ALTER TABLE `', IN_SCHEMANAME, '`.`', IN_TABLENAME, '`',
' DROP PARTITION ', IN_PARTITIONNAME, ';' );
PREPARE STMT FROM @SQL;
EXECUTE STMT;
DEALLOCATE PREPARE STMT;
ELSE
SELECT CONCAT("partition `", IN_PARTITIONNAME, "` for table `", IN_SCHEMANAME, ".", IN_TABLENAME, "` not exists") AS result;
END IF;
END$$
DELIMITER ;DELIMITER $$
USE zabbix$$
DROP PROCEDURE IF EXISTS drop_old_partition$$
CREATE PROCEDURE drop_old_partition(IN_SCHEMANAME VARCHAR(64), IN_TABLENAME VARCHAR(64), IN_PARTITIONNAME VARCHAR(64))BEGINDECLARE ROWS_CNT INT UNSIGNED;
SELECT COUNT(*) INTO ROWS_CNT
FROM information_schema.partitions
WHERE table_schema = IN_SCHEMANAME AND table_name = IN_TABLENAME AND partition_name = IN_PARTITIONNAME;
IF ROWS_CNT = 1 THEN
SET @SQL = CONCAT( 'ALTER TABLE `', IN_SCHEMANAME, '`.`', IN_TABLENAME, '`',
' DROP PARTITION ', IN_PARTITIONNAME, ';' );
PREPARE STMT FROM @SQL;
EXECUTE STMT;
DEALLOCATE PREPARE STMT;
ELSE
SELECT CONCAT("partition `", IN_PARTITIONNAME, "` for table `", IN_SCHEMANAME, ".", IN_TABLENAME, "` not exists") AS result;
END IF;
END$$
DELIMITER ;
Now we’ll add an event scheduler to execute this all:
DELIMITER $$ USE zabbix$$ CREATE EVENT IF NOT EXISTS e_part_manage ON SCHEDULE EVERY 1 DAYSTARTS ‘2021-02-19 04:00:00’ ON COMPLETION PRESERVE ENABLE COMMENT ‘Creating and dropping partitions’ DO BEGIN CALL zabbix.drop_partitions(‘zabbix’); CALL zabbix.create_next_partitions(‘zabbix’); END$$ DELIMITER ;
That’s it for stored procedures. Easy peasy, once you know all the commands to execute.
Disable Zabbix housekeeper
After partitioning and setting up either the Perl script or Stored Procedures, we need to make sure to disable the Zabbix housekeeper for the History and Trends tables. Navigate to the Zabbix frontend and go to Administration | Housekeeping.
Make sure Enable internal housekeeping is turned off for History and Trends like this:
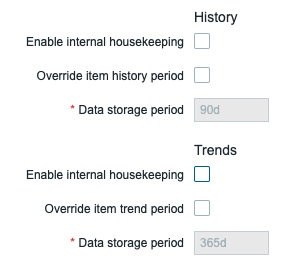
The Perl script or Stored Procedures will take over the process of deleting data and any housekeeper configuration set on items for History and Trends will no longer impact the data retention.
Conclusion
MySQL partitioning can seem to be a daring task and it definitely can be. In the past early posts by Zabbix community members made it possible for Zabbix users to setup partitioning. Overtime these posts have been lost, so we felt it was our task to make sure that there is a public guide out there at the ready for you to do this very important task.
After setting this all up make sure to keep an eye on your partitions for a few days as you might have missed something and they aren’t being created.
I hope you enjoyed reading this blog post and if you have any questions or need help configuring anything on your Zabbix setup feel free to contact me and the team at Opensource ICT Solutions.
Nathan Liefting
![]()
Common issues:
1. You might see the error: Table has no partition for value <unixtime>
1.1: If <unixtime> is in the future check if your newest partition matches the latest value present in each table with:
SELECT FROM_UNIXTIME(MAX(clock)) FROM history_uint;
1.2: If <unixtime> is in the past check if your oldest partition matches the oldest value present in each table with:
SELECT FROM_UNIXTIME(MIN(clock)) FROM history_uint;






Hi Nathan,
thanks for your help! I’ve an issue when i try to view a graph for an item. If i select a time of period of 7day, zabbix displays me the graph, but when i select a time of period of 30days, it shows me a query error. Can you help me?
In attachment, the error.
Thank you so much, I always wanted to sth like this using a perl/python script since 2019!!
Glad you liked it!
Hi Nathan,
Thanks for the guide. Is this dependent on MariaDB or can it work with MySQL V8?
The script works on both now, updated it yesterday to work with MySQL 8 🙂
For anyone else losing time with the above document: in the MySQL queries, after copy-pasting, adjust the “BEGINDECLARE” to BEGIN and make sure there’s space (or a newline) .
For some reason, in the ALTER TABLE history_uint query, another character was copied rather than an actual space (it was impossible to visibly see this; but may lead to failure of executing the whole query)
This should be fixed 🙂
Still not fixed btw. Maybe it’s the way de code blocks are displayed on this website. Maybe better to post the sql scripts on github. Just an idea:)
But thanks for the works!
Hi,
thanks for this documentation!
But executing manually the Alter table seems not needd?
Configuring the perl script, and executing once seems enough? The script automatically creates all previous and 10 future partitions?
Thanks
Hi,
The manual executing doesn’t have to be done if you added the Cronjob. But it can be done just to make sure everything is working correctly, as a verification step.
Furthermore you need to execute the script every single day to make sure the partitions will be deleted and created.
Kind regards,
Nathan
I’m trying to get started with this, but just the initial queries (SELECT FROM_UNIXTIME(MIN(clock)) FROM history_uint; etc.) seem to be taking forever. I’ve been sitting here for 10-15 minutes just waiting for the first to return anything. Is this normal?
This means that most probably you should take a look at MySQL database performance tuning. The queries can definitely take some time though!
Hi Nathan,
Thanks for this blog post, this is very useful !
MySQL server doesn’t allow to have partitions and foreign keys (https://dev.mysql.com/doc/refman/5.6/en/partitioning-limitations-storage-engines.html), this prevents me to partition the “events” and “alerts” tables.
What would be your recommandation for this ?
It there anything we have to take care when upgrading a Zabbix instance where the database is partitioned ? Do you already do an upgrade of Zabbix in this situation ?
Thanks a lot for all your help !
Stéphane
It currently isn’t recommended to partition these tables, the script also doesn’t include those tables. Use Zabbix housekeeper for these tables.
For your upgrade process keep in mind that when upgrading the to Zabbix 6.0+ the database key upgrade will also remove partitioning and it will need to be done again. Make sure to factor in that time.
Hi Nathan,
Great article, thank You for this. On question from my side: What does it mean: “big database”? What should be the daily growth of the DB to consider it as big? Maybe there are any other indicators for this?
Hi Mariusz,
Just starting “big” is definitely ambiguous, I wrote it like that because it really depends and there is no real way to state it in a blog. What I mean is, always use TMUX when the database is bigger than anything beyond just a test.
In terms of when it can take long. I’ve seen databases of 500GB taking a week on VERY poor hardware. I’ve also seen database >1TB taking a day. It all depends on the hardware (disks speed mainly).
To be on the safe side and do some asumptions, if you’re anywhere near 500GB keep a whole day blocked in the agenda to partition your database.
Not sure if this helps anyone, but I wrote a quick script to create the list of partitions for the ALTER TABLE query.
$minDate is an example date that you will get from the following command.
if anyone wants to expand this, I suggest getting a list of all the tables you want to partition and their clock min values, create a hash table, then loop through each set.
https://4sysops.com/archives/the-powershell-hash-table/
The idea is that we have to create a partition for each day, however, in my example, the minDate is the earliest date from the aforementioned table.
The Auditlog table in my zabbix instances goes back to June, so again. Many partitions are needed.
The task of copy/pasting then modifying each PARTITION line for each table, is going to be insanely long, so I guess the best way to do this is to just get the initial date, then create the partitions list automatically.
This is what the script below does. It’s not very elegant, but it does the job.
[datetime]$minDate = "2022-08-15 00:00:00" $currDate = get-date -Format "yyyy-MM-dd hh:mm:ss" while ([datetime]$minDate -le [datetime]$currDate) { if ($minDate.day -lt 10) { $unix_DayStampCorrection = "0"+$($minDate.Day) } else { $unix_DayStampCorrection = $minDate.Day } if ($minDate.Month -lt 10) { $unix_MonthStampCorrection = "0"+$($minDate.Month) } else { $unix_MonthStampCorrection = $minDate.Month } if ($minDate.Day -eq 1) { Write-Host "PARTITION p$($minDate.Year)_$($minDate.AddMonths(-1).Month)_$($minDate.AddDays(-1).Day) VALUES LESS THAN (UNIX_TIMESTAMP("$($minDate.year)-$($unix_MonthStampCorrection)-$($unix_DayStampCorrection) 00:00:00")) ENGINE = InnoDB," } else { Write-Host "PARTITION p$($minDate.Year)_$($minDate.Month)_$($minDate.AddDays(-1).Day) VALUES LESS THAN (UNIX_TIMESTAMP("$($minDate.year)-$($unix_MonthStampCorrection)-$($unix_DayStampCorrection) 00:00:00")) ENGINE = InnoDB," } $mindate = $minDate.AddDays(1) }This will result in something like this, which you can just insert into your ALTER TABLE query. Don’t forget to remove the comma from the last line.
PARTITION p2022_8_14 VALUES LESS THAN (UNIX_TIMESTAMP("2022-08-15 00:00:00")) ENGINE = InnoDB, PARTITION p2022_8_15 VALUES LESS THAN (UNIX_TIMESTAMP("2022-08-16 00:00:00")) ENGINE = InnoDB, PARTITION p2022_8_16 VALUES LESS THAN (UNIX_TIMESTAMP("2022-08-17 00:00:00")) ENGINE = InnoDB, PARTITION p2022_8_17 VALUES LESS THAN (UNIX_TIMESTAMP("2022-08-18 00:00:00")) ENGINE = InnoDB, PARTITION p2022_8_18 VALUES LESS THAN (UNIX_TIMESTAMP("2022-08-19 00:00:00")) ENGINE = InnoDB, PARTITION p2022_8_19 VALUES LESS THAN (UNIX_TIMESTAMP("2022-08-20 00:00:00")) ENGINE = InnoDB, PARTITION p2022_8_20 VALUES LESS THAN (UNIX_TIMESTAMP("2022-08-21 00:00:00")) ENGINE = InnoDB, PARTITION p2022_8_21 VALUES LESS THAN (UNIX_TIMESTAMP("2022-08-22 00:00:00")) ENGINE = InnoDB, PARTITION p2022_8_22 VALUES LESS THAN (UNIX_TIMESTAMP("2022-08-23 00:00:00")) ENGINE = InnoDB, PARTITION p2022_8_23 VALUES LESS THAN (UNIX_TIMESTAMP("2022-08-24 00:00:00")) ENGINE = InnoDB, PARTITION p2022_8_24 VALUES LESS THAN (UNIX_TIMESTAMP("2022-08-25 00:00:00")) ENGINE = InnoDB, PARTITION p2022_8_25 VALUES LESS THAN (UNIX_TIMESTAMP("2022-08-26 00:00:00")) ENGINE = InnoDB, PARTITION p2022_8_26 VALUES LESS THAN (UNIX_TIMESTAMP("2022-08-27 00:00:00")) ENGINE = InnoDB, PARTITION p2022_8_27 VALUES LESS THAN (UNIX_TIMESTAMP("2022-08-28 00:00:00")) ENGINE = InnoDB, PARTITION p2022_8_28 VALUES LESS THAN (UNIX_TIMESTAMP("2022-08-29 00:00:00")) ENGINE = InnoDB, PARTITION p2022_8_29 VALUES LESS THAN (UNIX_TIMESTAMP("2022-08-30 00:00:00")) ENGINE = InnoDB, PARTITION p2022_8_30 VALUES LESS THAN (UNIX_TIMESTAMP("2022-08-31 00:00:00")) ENGINE = InnoDB, PARTITION p2022_8_31 VALUES LESS THAN (UNIX_TIMESTAMP("2022-09-01 00:00:00")) ENGINE = InnoDB, PARTITION p2022_9_1 VALUES LESS THAN (UNIX_TIMESTAMP("2022-09-02 00:00:00")) ENGINE = InnoDB, PARTITION p2022_9_2 VALUES LESS THAN (UNIX_TIMESTAMP("2022-09-03 00:00:00")) ENGINE = InnoDB, PARTITION p2022_9_3 VALUES LESS THAN (UNIX_TIMESTAMP("2022-09-04 00:00:00")) ENGINE = InnoDB, PARTITION p2022_9_4 VALUES LESS THAN (UNIX_TIMESTAMP("2022-09-05 00:00:00")) ENGINE = InnoDB, PARTITION p2022_9_5 VALUES LESS THAN (UNIX_TIMESTAMP("2022-09-06 00:00:00")) ENGINE = InnoDB, PARTITION p2022_9_6 VALUES LESS THAN (UNIX_TIMESTAMP("2022-09-07 00:00:00")) ENGINE = InnoDB, PARTITION p2022_9_7 VALUES LESS THAN (UNIX_TIMESTAMP("2022-09-08 00:00:00")) ENGINE = InnoDB, PARTITION p2022_9_8 VALUES LESS THAN (UNIX_TIMESTAMP("2022-09-09 00:00:00")) ENGINE = InnoDB, PARTITION p2022_9_9 VALUES LESS THAN (UNIX_TIMESTAMP("2022-09-10 00:00:00")) ENGINE = InnoDB, PARTITION p2022_9_10 VALUES LESS THAN (UNIX_TIMESTAMP("2022-09-11 00:00:00")) ENGINE = InnoDB, PARTITION p2022_9_11 VALUES LESS THAN (UNIX_TIMESTAMP("2022-09-12 00:00:00")) ENGINE = InnoDB, PARTITION p2022_9_12 VALUES LESS THAN (UNIX_TIMESTAMP("2022-09-13 00:00:00")) ENGINE = InnoDB, PARTITION p2022_9_13 VALUES LESS THAN (UNIX_TIMESTAMP("2022-09-14 00:00:00")) ENGINE = InnoDB, PARTITION p2022_9_14 VALUES LESS THAN (UNIX_TIMESTAMP("2022-09-15 00:00:00")) ENGINE = InnoDB, PARTITION p2022_9_15 VALUES LESS THAN (UNIX_TIMESTAMP("2022-09-16 00:00:00")) ENGINE = InnoDB, PARTITION p2022_9_16 VALUES LESS THAN (UNIX_TIMESTAMP("2022-09-17 00:00:00")) ENGINE = InnoDB, PARTITION p2022_9_17 VALUES LESS THAN (UNIX_TIMESTAMP("2022-09-18 00:00:00")) ENGINE = InnoDB, PARTITION p2022_9_18 VALUES LESS THAN (UNIX_TIMESTAMP("2022-09-19 00:00:00")) ENGINE = InnoDB, PARTITION p2022_9_19 VALUES LESS THAN (UNIX_TIMESTAMP("2022-09-20 00:00:00")) ENGINE = InnoDB, PARTITION p2022_9_20 VALUES LESS THAN (UNIX_TIMESTAMP("2022-09-21 00:00:00")) ENGINE = InnoDB, PARTITION p2022_9_21 VALUES LESS THAN (UNIX_TIMESTAMP("2022-09-22 00:00:00")) ENGINE = InnoDB, PARTITION p2022_9_22 VALUES LESS THAN (UNIX_TIMESTAMP("2022-09-23 00:00:00")) ENGINE = InnoDB, PARTITION p2022_9_23 VALUES LESS THAN (UNIX_TIMESTAMP("2022-09-24 00:00:00")) ENGINE = InnoDB, PARTITION p2022_9_24 VALUES LESS THAN (UNIX_TIMESTAMP("2022-09-25 00:00:00")) ENGINE = InnoDB, PARTITION p2022_9_25 VALUES LESS THAN (UNIX_TIMESTAMP("2022-09-26 00:00:00")) ENGINE = InnoDB, PARTITION p2022_9_26 VALUES LESS THAN (UNIX_TIMESTAMP("2022-09-27 00:00:00")) ENGINE = InnoDB, PARTITION p2022_9_27 VALUES LESS THAN (UNIX_TIMESTAMP("2022-09-28 00:00:00")) ENGINE = InnoDB, PARTITION p2022_9_28 VALUES LESS THAN (UNIX_TIMESTAMP("2022-09-29 00:00:00")) ENGINE = InnoDB, PARTITION p2022_9_29 VALUES LESS THAN (UNIX_TIMESTAMP("2022-09-30 00:00:00")) ENGINE = InnoDB, PARTITION p2022_9_30 VALUES LESS THAN (UNIX_TIMESTAMP("2022-10-01 00:00:00")) ENGINE = InnoDB, PARTITION p2022_10_1 VALUES LESS THAN (UNIX_TIMESTAMP("2022-10-02 00:00:00")) ENGINE = InnoDB, PARTITION p2022_10_2 VALUES LESS THAN (UNIX_TIMESTAMP("2022-10-03 00:00:00")) ENGINE = InnoDB, PARTITION p2022_10_3 VALUES LESS THAN (UNIX_TIMESTAMP("2022-10-04 00:00:00")) ENGINE = InnoDB, PARTITION p2022_10_4 VALUES LESS THAN (UNIX_TIMESTAMP("2022-10-05 00:00:00")) ENGINE = InnoDB, PARTITION p2022_10_5 VALUES LESS THAN (UNIX_TIMESTAMP("2022-10-06 00:00:00")) ENGINE = InnoDB, PARTITION p2022_10_6 VALUES LESS THAN (UNIX_TIMESTAMP("2022-10-07 00:00:00")) ENGINE = InnoDB, PARTITION p2022_10_7 VALUES LESS THAN (UNIX_TIMESTAMP("2022-10-08 00:00:00")) ENGINE = InnoDB, PARTITION p2022_10_8 VALUES LESS THAN (UNIX_TIMESTAMP("2022-10-09 00:00:00")) ENGINE = InnoDB, PARTITION p2022_10_9 VALUES LESS THAN (UNIX_TIMESTAMP("2022-10-10 00:00:00")) ENGINE = InnoDB, PARTITION p2022_10_10 VALUES LESS THAN (UNIX_TIMESTAMP("2022-10-11 00:00:00")) ENGINE = InnoDB, PARTITION p2022_10_11 VALUES LESS THAN (UNIX_TIMESTAMP("2022-10-12 00:00:00")) ENGINE = InnoDB, PARTITION p2022_10_12 VALUES LESS THAN (UNIX_TIMESTAMP("2022-10-13 00:00:00")) ENGINE = InnoDB, PARTITION p2022_10_13 VALUES LESS THAN (UNIX_TIMESTAMP("2022-10-14 00:00:00")) ENGINE = InnoDB, PARTITION p2022_10_14 VALUES LESS THAN (UNIX_TIMESTAMP("2022-10-15 00:00:00")) ENGINE = InnoDB, PARTITION p2022_10_15 VALUES LESS THAN (UNIX_TIMESTAMP("2022-10-16 00:00:00")) ENGINE = InnoDB, PARTITION p2022_10_16 VALUES LESS THAN (UNIX_TIMESTAMP("2022-10-17 00:00:00")) ENGINE = InnoDB, PARTITION p2022_10_17 VALUES LESS THAN (UNIX_TIMESTAMP("2022-10-18 00:00:00")) ENGINE = InnoDB, PARTITION p2022_10_18 VALUES LESS THAN (UNIX_TIMESTAMP("2022-10-19 00:00:00")) ENGINE = InnoDB, PARTITION p2022_10_19 VALUES LESS THAN (UNIX_TIMESTAMP("2022-10-20 00:00:00")) ENGINE = InnoDB, PARTITION p2022_10_20 VALUES LESS THAN (UNIX_TIMESTAMP("2022-10-21 00:00:00")) ENGINE = InnoDB, PARTITION p2022_10_21 VALUES LESS THAN (UNIX_TIMESTAMP("2022-10-22 00:00:00")) ENGINE = InnoDB, PARTITION p2022_10_22 VALUES LESS THAN (UNIX_TIMESTAMP("2022-10-23 00:00:00")) ENGINE = InnoDB, PARTITION p2022_10_23 VALUES LESS THAN (UNIX_TIMESTAMP("2022-10-24 00:00:00")) ENGINE = InnoDB, PARTITION p2022_10_24 VALUES LESS THAN (UNIX_TIMESTAMP("2022-10-25 00:00:00")) ENGINE = InnoDB, PARTITION p2022_10_25 VALUES LESS THAN (UNIX_TIMESTAMP("2022-10-26 00:00:00")) ENGINE = InnoDB, PARTITION p2022_10_26 VALUES LESS THAN (UNIX_TIMESTAMP("2022-10-27 00:00:00")) ENGINE = InnoDB, PARTITION p2022_10_27 VALUES LESS THAN (UNIX_TIMESTAMP("2022-10-28 00:00:00")) ENGINE = InnoDB, PARTITION p2022_10_28 VALUES LESS THAN (UNIX_TIMESTAMP("2022-10-29 00:00:00")) ENGINE = InnoDB, PARTITION p2022_10_29 VALUES LESS THAN (UNIX_TIMESTAMP("2022-10-30 00:00:00")) ENGINE = InnoDB, PARTITION p2022_10_30 VALUES LESS THAN (UNIX_TIMESTAMP("2022-10-31 00:00:00")) ENGINE = InnoDB, PARTITION p2022_10_31 VALUES LESS THAN (UNIX_TIMESTAMP("2022-11-01 00:00:00")) ENGINE = InnoDB, PARTITION p2022_11_1 VALUES LESS THAN (UNIX_TIMESTAMP("2022-11-02 00:00:00")) ENGINE = InnoDB, PARTITION p2022_11_2 VALUES LESS THAN (UNIX_TIMESTAMP("2022-11-03 00:00:00")) ENGINE = InnoDB, PARTITION p2022_11_3 VALUES LESS THAN (UNIX_TIMESTAMP("2022-11-04 00:00:00")) ENGINE = InnoDB, PARTITION p2022_11_4 VALUES LESS THAN (UNIX_TIMESTAMP("2022-11-05 00:00:00")) ENGINE = InnoDB, PARTITION p2022_11_5 VALUES LESS THAN (UNIX_TIMESTAMP("2022-11-06 00:00:00")) ENGINE = InnoDB, PARTITION p2022_11_6 VALUES LESS THAN (UNIX_TIMESTAMP("2022-11-07 00:00:00")) ENGINE = InnoDB, PARTITION p2022_11_7 VALUES LESS THAN (UNIX_TIMESTAMP("2022-11-08 00:00:00")) ENGINE = InnoDB, PARTITION p2022_11_8 VALUES LESS THAN (UNIX_TIMESTAMP("2022-11-09 00:00:00")) ENGINE = InnoDB, PARTITION p2022_11_9 VALUES LESS THAN (UNIX_TIMESTAMP("2022-11-10 00:00:00")) ENGINE = InnoDB, PARTITION p2022_11_10 VALUES LESS THAN (UNIX_TIMESTAMP("2022-11-11 00:00:00")) ENGINE = InnoDB, PARTITION p2022_11_11 VALUES LESS THAN (UNIX_TIMESTAMP("2022-11-12 00:00:00")) ENGINE = InnoDB, PARTITION p2022_11_12 VALUES LESS THAN (UNIX_TIMESTAMP("2022-11-13 00:00:00")) ENGINE = InnoDB, PARTITION p2022_11_13 VALUES LESS THAN (UNIX_TIMESTAMP("2022-11-14 00:00:00")) ENGINE = InnoDB, PARTITION p2022_11_14 VALUES LESS THAN (UNIX_TIMESTAMP("2022-11-15 00:00:00")) ENGINE = InnoDB, PARTITION p2022_11_15 VALUES LESS THAN (UNIX_TIMESTAMP("2022-11-16 00:00:00")) ENGINE = InnoDB, PARTITION p2022_11_16 VALUES LESS THAN (UNIX_TIMESTAMP("2022-11-17 00:00:00")) ENGINE = InnoDB, PARTITION p2022_11_17 VALUES LESS THAN (UNIX_TIMESTAMP("2022-11-18 00:00:00")) ENGINE = InnoDB, PARTITION p2022_11_18 VALUES LESS THAN (UNIX_TIMESTAMP("2022-11-19 00:00:00")) ENGINE = InnoDB, PARTITION p2022_11_19 VALUES LESS THAN (UNIX_TIMESTAMP("2022-11-20 00:00:00")) ENGINE = InnoDB, PARTITION p2022_11_20 VALUES LESS THAN (UNIX_TIMESTAMP("2022-11-21 00:00:00")) ENGINE = InnoDB, PARTITION p2022_11_21 VALUES LESS THAN (UNIX_TIMESTAMP("2022-11-22 00:00:00")) ENGINE = InnoDB, PARTITION p2022_11_22 VALUES LESS THAN (UNIX_TIMESTAMP("2022-11-23 00:00:00")) ENGINE = InnoDB, PARTITION p2022_11_23 VALUES LESS THAN (UNIX_TIMESTAMP("2022-11-24 00:00:00")) ENGINE = InnoDB, PARTITION p2022_11_24 VALUES LESS THAN (UNIX_TIMESTAMP("2022-11-25 00:00:00")) ENGINE = InnoDB, PARTITION p2022_11_25 VALUES LESS THAN (UNIX_TIMESTAMP("2022-11-26 00:00:00")) ENGINE = InnoDB, PARTITION p2022_11_26 VALUES LESS THAN (UNIX_TIMESTAMP("2022-11-27 00:00:00")) ENGINE = InnoDB, PARTITION p2022_11_27 VALUES LESS THAN (UNIX_TIMESTAMP("2022-11-28 00:00:00")) ENGINE = InnoDB, PARTITION p2022_11_28 VALUES LESS THAN (UNIX_TIMESTAMP("2022-11-29 00:00:00")) ENGINE = InnoDB, PARTITION p2022_11_29 VALUES LESS THAN (UNIX_TIMESTAMP("2022-11-30 00:00:00")) ENGINE = InnoDB, PARTITION p2022_11_30 VALUES LESS THAN (UNIX_TIMESTAMP("2022-12-01 00:00:00")) ENGINE = InnoDB, PARTITION p2022_12_1 VALUES LESS THAN (UNIX_TIMESTAMP("2022-12-02 00:00:00")) ENGINE = InnoDB, PARTITION p2022_12_2 VALUES LESS THAN (UNIX_TIMESTAMP("2022-12-03 00:00:00")) ENGINE = InnoDB, PARTITION p2022_12_3 VALUES LESS THAN (UNIX_TIMESTAMP("2022-12-04 00:00:00")) ENGINE = InnoDB, PARTITION p2022_12_4 VALUES LESS THAN (UNIX_TIMESTAMP("2022-12-05 00:00:00")) ENGINE = InnoDB, PARTITION p2022_12_5 VALUES LESS THAN (UNIX_TIMESTAMP("2022-12-06 00:00:00")) ENGINE = InnoDB, PARTITION p2022_12_6 VALUES LESS THAN (UNIX_TIMESTAMP("2022-12-07 00:00:00")) ENGINE = InnoDB, PARTITION p2022_12_7 VALUES LESS THAN (UNIX_TIMESTAMP("2022-12-08 00:00:00")) ENGINE = InnoDB, PARTITION p2022_12_8 VALUES LESS THAN (UNIX_TIMESTAMP("2022-12-09 00:00:00")) ENGINE = InnoDB, PARTITION p2022_12_9 VALUES LESS THAN (UNIX_TIMESTAMP("2022-12-10 00:00:00")) ENGINE = InnoDB, PARTITION p2022_12_10 VALUES LESS THAN (UNIX_TIMESTAMP("2022-12-11 00:00:00")) ENGINE = InnoDB, PARTITION p2022_12_11 VALUES LESS THAN (UNIX_TIMESTAMP("2022-12-12 00:00:00")) ENGINE = InnoDB, PARTITION p2022_12_12 VALUES LESS THAN (UNIX_TIMESTAMP("2022-12-13 00:00:00")) ENGINE = InnoDB, PARTITION p2022_12_13 VALUES LESS THAN (UNIX_TIMESTAMP("2022-12-14 00:00:00")) ENGINE = InnoDB, PARTITION p2022_12_14 VALUES LESS THAN (UNIX_TIMESTAMP("2022-12-15 00:00:00")) ENGINE = InnoDB, PARTITION p2022_12_15 VALUES LESS THAN (UNIX_TIMESTAMP("2022-12-16 00:00:00")) ENGINE = InnoDB, PARTITION p2022_12_16 VALUES LESS THAN (UNIX_TIMESTAMP("2022-12-17 00:00:00")) ENGINE = InnoDB, PARTITION p2022_12_17 VALUES LESS THAN (UNIX_TIMESTAMP("2022-12-18 00:00:00")) ENGINE = InnoDB, PARTITION p2022_12_18 VALUES LESS THAN (UNIX_TIMESTAMP("2022-12-19 00:00:00")) ENGINE = InnoDB, PARTITION p2022_12_19 VALUES LESS THAN (UNIX_TIMESTAMP("2022-12-20 00:00:00")) ENGINE = InnoDB, PARTITION p2022_12_20 VALUES LESS THAN (UNIX_TIMESTAMP("2022-12-21 00:00:00")) ENGINE = InnoDB, PARTITION p2022_12_21 VALUES LESS THAN (UNIX_TIMESTAMP("2022-12-22 00:00:00")) ENGINE = InnoDB, PARTITION p2022_12_22 VALUES LESS THAN (UNIX_TIMESTAMP("2022-12-23 00:00:00")) ENGINE = InnoDB, PARTITION p2022_12_23 VALUES LESS THAN (UNIX_TIMESTAMP("2022-12-24 00:00:00")) ENGINE = InnoDB, PARTITION p2022_12_24 VALUES LESS THAN (UNIX_TIMESTAMP("2022-12-25 00:00:00")) ENGINE = InnoDB, PARTITION p2022_12_25 VALUES LESS THAN (UNIX_TIMESTAMP("2022-12-26 00:00:00")) ENGINE = InnoDB, PARTITION p2022_12_26 VALUES LESS THAN (UNIX_TIMESTAMP("2022-12-27 00:00:00")) ENGINE = InnoDB, PARTITION p2022_12_27 VALUES LESS THAN (UNIX_TIMESTAMP("2022-12-28 00:00:00")) ENGINE = InnoDB, PARTITION p2022_12_28 VALUES LESS THAN (UNIX_TIMESTAMP("2022-12-29 00:00:00")) ENGINE = InnoDB, PARTITION p2022_12_29 VALUES LESS THAN (UNIX_TIMESTAMP("2022-12-30 00:00:00")) ENGINE = InnoDB, PARTITION p2022_12_30 VALUES LESS THAN (UNIX_TIMESTAMP("2022-12-31 00:00:00")) ENGINE = InnoDB, PARTITION p2023_12_31 VALUES LESS THAN (UNIX_TIMESTAMP("2023-01-01 00:00:00")) ENGINE = InnoDB, PARTITION p2023_1_1 VALUES LESS THAN (UNIX_TIMESTAMP("2023-01-02 00:00:00")) ENGINE = InnoDB, PARTITION p2023_1_2 VALUES LESS THAN (UNIX_TIMESTAMP("2023-01-03 00:00:00")) ENGINE = InnoDB,You’ll need to repeat this for each table, if you don’t want to use the aforementioned hash
If anyone notices any mistakes in the output, I welcome their advice.
Seems like some of the code was formatter wrong by the website.
to add to this, on oracle Linux 8, the per-DateTime dependency can only be installed after you enable the ol8_codeready_builder repo with:
Repo can be found here:
https://public-yum.oracle.com/repo/OracleLinux/OL8/codeready/builder/x86_64/index.html
This powershell script is not generating the correct names for the partitions, it cuts the leading zeros on days and months. For example, on the last line of the above output, the partition is set as p2023_1_2 whereas it should be p2013_01_02.
Hi, I got all the way to the end and got this when running the perl script:
“Your installation of MySQL does not support table partitioning.”
I did a fresh install from the zabbix site – zabbix-release_6.2-4+ubuntu22.04_all.deb.
My MySQL version is: mysql Ver 8.0.32-0ubuntu0.22.04.2 for Linux on x86_64 ((Ubuntu))
How do I enable it besides trying to build from source?
Make sure to comment/uncomment the correct lines (see screenshot). Ubuntu 22.04 with MySQL 8.0.32 works with this script.
Hi Nathan.
Is it necessary to Stop Zabbix?
In my case my IT department cant be stay unmonitored and I need to partition 950 GB
Hi Dark-zbx,
It’s a good question and it’s exactly why I mention this:
“which is why I always recommend setting up partitioning BEFORE going live with a new Zabbix setup.”
Partitioning will lock your tables which is why I recommend that Zabbix server should be stopped before doing the partitioning. Since it doesn’t really allow us to write data to the table we are working on.
If your IT departement cannot stay unmonitored, I would recommend to find an alternative route like cloning your Zabbix database or throwing away your history. You’d have some loss of data, but at least you won’t miss any problems.
Good luck! and if you need any consultancy help feel free to reach out to us on oicts.com We do these partitioning shifts a lot and have numerous options to get it done with minimal impact.
Hi Nathan,
There is an error in your mysql procedures.
When using mysql cursors you should verify record existence AFTER fetching a record.
Thus, the code should look like
FETCH get_prt_tables INTO TABLENAME_TMP, PERIOD_TMP; IF DONE THEN LEAVE loop_create_part; END IF;Please fix it in both procedures, otherwise many users who use copy-paste approach will have erroneous code.
Regards,
Michał
Hi Nathan, thanks for sharing.
In case someone needs to run the Perl script in Docker, I’ve shared some modifications for that (also created a PR in your repository)
https://github.com/thiagomdiniz/zabbix-mysql-partitioning-perl/tree/add_docker_support
Hi everyone, I have organized an out-of-the-box solution based on the method suggested by the expert above~ Please take a look here:
https://github.com/hanzhongzi/zabbix_pratition_tables
In the paragraph regarding partitioning the history_uint table you state:
I think you meant to say “…ending on 23-02-2021” given the example shown?
Since my perl kung-fu is non-existent, I created a python version of the Opensource ICT Solutions Github project in Gitlab. It also includes a script to generate the initial partition queries.
https://gitlab.com/jhboricua/zabbix-mysql-partitioning
Hi, regarding housekeeper with it disabled functions like the Item based keep history are disabled? Also how does housekeeper handle deleted items and their data when it is disabled for history tables, will those stick around until the partition gets drop? I manage an instance with now almost 3TB of data and the past few weeks I have discovered that suddenly we have a growth of 100GB per week. Only major change in templates was we added new SNMP templates and one of them stores SNMP Walks with the keep history data for 1h but I can see history for the 3 weeks. So I wonder if this could be the cause and how I could address it? With the housekeeper not touching the history and trend tables.