




Preprocessing is a great tool to make data collection precise and crystal clear. That’s why we prepared some great examples of how you can use that tool to achieve the same.
Contents
I. What is pre-processing? (1:12:11)
II. Why do we need preprocessing? (1:16:08)
1. Data cleansing (1:18:40)
2. Data editing (1:23:55)
3. Data reduction (1:30:21)
4. Data wrangling (1:33:34)
III. How it works? (1:36:29)
IV. Zabbix 5.0 improvements (1:38:19)
V. Questions and answers (1:40:38)
What is pre-processing?
In computer science, a preprocessor is a program that processes its input data to produce output that is used as input to another program, for instance, to the application monitoring your environment. Both require tuning (for instance, buffer and transaction log).
Information may be a plain number, a string, some text, JSON arrays, or even SQL queries. Still, most of the time, you need to receive some specific data, make that data understandable, and save as many resources as possible. So, data preprocessing is used not only in machine learning, but for data collection, all to make input data easier to work with.
The more items you have, the more space you save with preprocessing, leaving your database smaller, requiring fewer resources, and operating faster.
In summary:
- Preprocessing allows defining transformation rules for the retrieved item values before they are actually saved to the database.
- One or several transformations are possible before saving values to the database.
- Transformations are executed in the order, in which they are defined.
- Preprocessing is done either by the Zabbix Server or by Zabbix Proxy (for items monitored by proxy).
Preprocessing can be used not only to transform data, but also to validate the received metrics and optimize the collected data to improve Zabbix performance and scalability. All of this is covered in our one-day training course focused on different types of Zabbix preprocessing. During the training you will learn how to define and combine preprocessing steps by performing practical tasks under the guidance of a Zabbix certified trainer.
Why do we need preprocessing?
- Data cleansing — the process, which helps to detect incorrect values and remove them out of monitoring or change them in a way that makes incorrect data clearly visible.
- Data editing — the process of changing or adjusting the data making it easier to read and more convenient to use in the database or your environment.
- Data reduction — the principle which allows to save a lot of time and resources, for instance, as the case is with the dependent items, where you can collect unimaginable amounts of output without storing unnecessary parts of it in Zabbix.
- Data wrangling — data transformation or conversion
Data cleansing
As the result of data processing depends also on the quality of the data collected, the data collected sometimes should be cleansed. Improper data can be removed by several methods:
- Defining a range by specifying minimum/maximum values (inclusive).
- Specifying a regular expression that will look for an error or a value that must match or not match.
- Checking for an application-level error message located at JSONPath.
- Checking for an application-level error message located at xpath.
Defining a range
If we need to define a range or, for instance, we are collecting temperature values, or something in percentage, we might need numbers from 1 to 100. Occasionally, a value might be ‘0’ in case of an error, or we might constantly, but not very often receive some other value that we need to exclude. In this case, we can discard this value that does not fit in our statistics and display only the correct data.
Another way is to adjust the range. For instance, when collecting successful logins or successful sessions to make unsuccessful logins and sessions more visible, their ‘0’ value may be replaced by ‘999’ to display a jump in the graph.
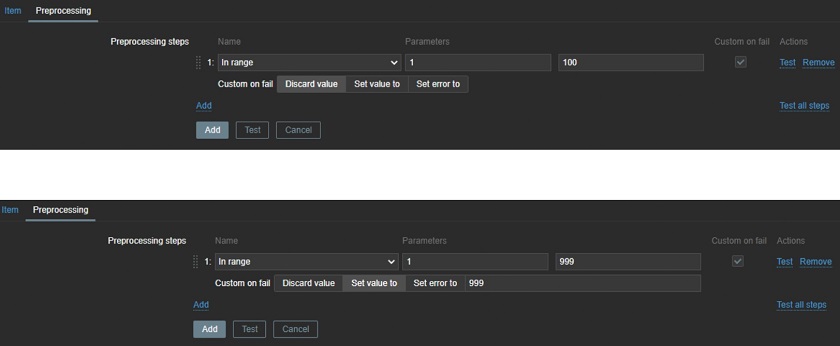
Defining a range
Regular expressions
Regular expressions can be used in an unlimited number of ways. One of the options is to define, that value needs to match a regular expression and, depending on if it matches or not, it can be collected or discarded.
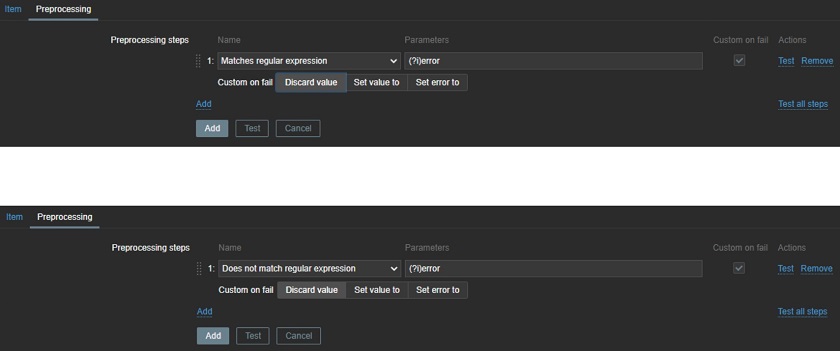
Using regular expressions
In Zabbix, you can create regular expressions filters on global or item level to filter specific values, such as:
- Windows service startup state
^(automatic|automatic delayed|manual|disabled)$
- only numbers
([1-9]+)
- domain names
((?>[a-z\-0-9]{2,}\.){1,}[a-z]{2,8})(?:\s|\/)
- or even smiley faces 🙂
([0-9A-Za-z'\&\-\.\/\(\)=:;]+)|((?::|;|=)(?:-)?(?:\)|D|P))
JSONPath or XPath
You can use JSONPath or XPath to check for errors in JSON or in XML, for instance, to display the errors or just to discard the unneeded values.
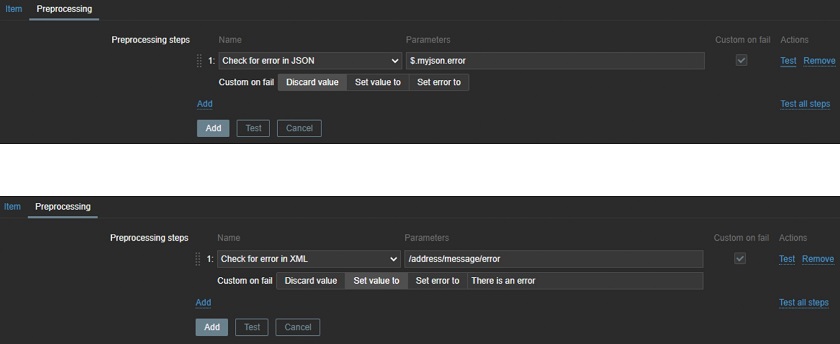
Using JSONPath and XPath
Data editing
Data editing can involve:
- replacing,
- trimming,
- using regex,
- multiplying, and
- using JavaScript.
Replacing
You can find a string error and replace it with ‘0’. But replacing can be tricky in case of different error messages or if an item contains many different values. So, replacing must be precise, i.e. you can use a regular expression to extract the word ‘error‘, then replace it with ‘0‘, and collect or discard only ‘0‘. Don’t forget to use value mapping on item level!
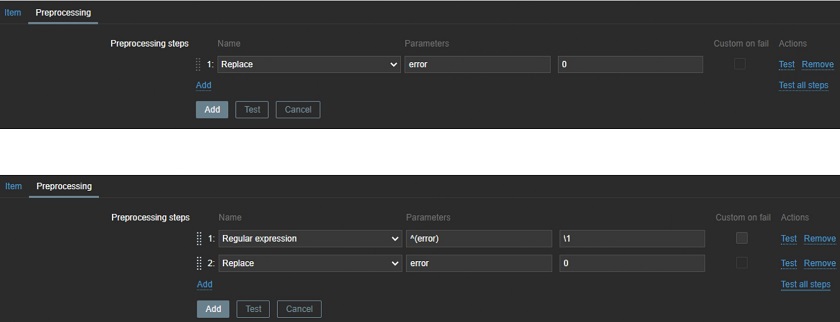
Data replacing
Trimming
Trimming — removing any values that do not allow you to see the data as you expect or to change the format of how the data will be saved in the database (including different history tables). Trimming saves a lot of space by keeping the value as short as possible or converting values from being a string to being a number.

Trimming
Here are some more regular expressions to use:
network adapters
^(eth[0-9]$)|(^eth[0-9]:[1-9]$)
short filesystem regex
^(ntfs|fat32|zfs)$
SNMP storage devices
^(Physical memory|Virtual memory|Memory buffers|Cached memory|Swap space)$
Multiplying
Multiplying is a simple but very efficient option to transform the data. There are many commands or requests, for instance, a command to MySQL returning the data specifically in kilobytes, so you can use a custom multiplier to display more understandable values in Zabbix.

Kilobytes to bytes
In some cases, the data may be retrieved in milliseconds that might be confusing. This data can be transformed by multiplying so that the data in Zabbix is easier to digest.

Milliseconds to seconds
However if the item type of information is Numeric (unsigned), incoming values with a fractional part will be trimmed (i.e. ‘0.9’ will become ‘0’) before the custom multiplier is applied.
Using JavaScript
- JavaScript can help you change absolutely anything, i.e. track certificate expiration simpler and make trigger building easier, for instance when a simple Date.parse() won’t do.
var split = value.split(' '),
MONTHS_LIST = ['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun', 'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec'],
month_index = ('0' + (MONTHS_LIST.indexOf(split[0]) + 1)).slice(-2),
ISOdate = split[3] + '-' + month_index + '-' + split[1] + 'T' + split[2],
now = Date.now();
return parseInt((Date.parse(ISOdate) - now) / 1000);
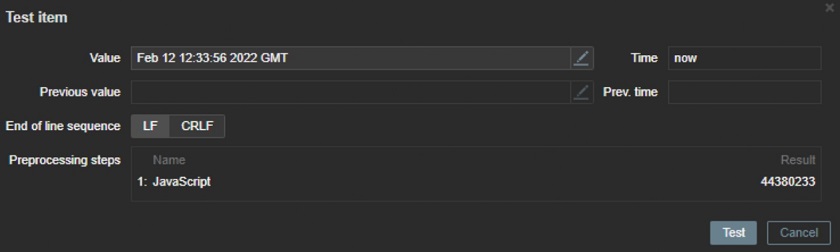
Getting time till the end of certificates in seconds
- If you have older SNMP devices in your environment and their uptime is displayed as date and time in hexadecimal numbers. This requires a lot to actually transform this data into something more understandable.
'use strict';
var str = value;
alert("str: " + str);
var y256 = str.slice(0,2); var y = str.slice(3,5); var m = str.slice(6,8);
var d = str.slice(9,11); var h = str.slice(12,14); var min = str.slice(15,17);
var y256Base10 = +("0x" + y256);
var yBase10 = +("0x" + y);
var Year = 256*y256Base10 + yBase10;
var mBase10 = +("0x" + m);
var dBase10 = +("0x" + d);
var hBase10 = +("0x" + h);
var minBase10 = +("0x" + min);
var YR = String(Year); var MM = String(mBase10); var DD = String(dBase10);
var HH = String(hBase10);
var MIN = String(minBase10);
if (mBase10 < 10) MM = "0" + MM; if (dBase10 < 10) DD = "0" + DD;
if (hBase10 < 10) HH = "0" + HH; if (minBase10 < 10) MIN = "0" + MIN;
var Date = YR + "-" + MM + "-" + DD + " " + HH + ":" + MIN;
return Date;
With the help of JavaScript pre-processing, you can get more readable values.
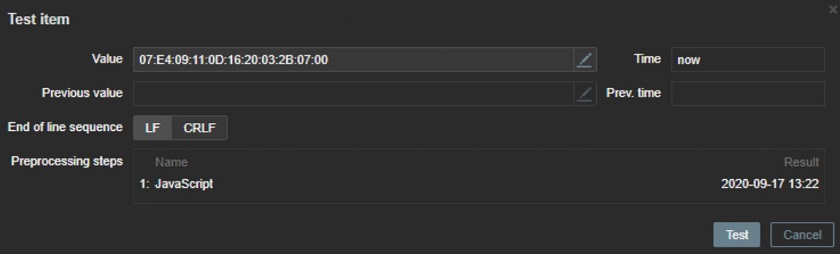
Converting SNMP ‘DateandTime’ to Timestamp
Data reduction
- XML XPath,
- JSONPath,
- regex,
- throttling,
- replacing.
XML Path
1. Prepare an XML

2. Find a service you are looking for.
/rhs_check/services/service[1]
3. Add some more steps:
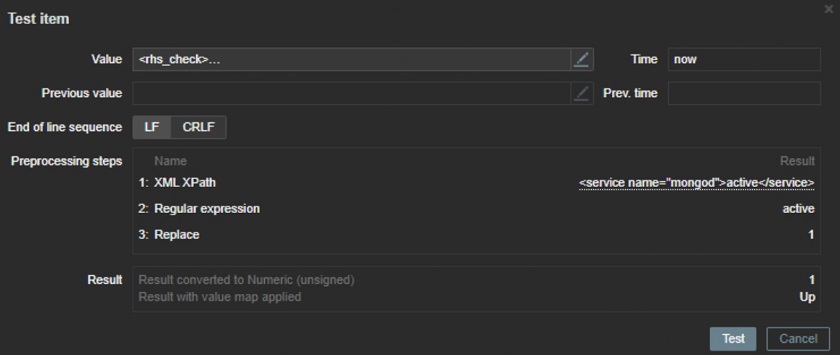
We can use XML to get some specific values. At the same time, we can combine our preprocessing steps. So, we can get a specific service, use a regular expression to actually find and check if it is in a specific state (this time “active”), and then just replace it with the number — one. Then we can use value mapping in Zabbix to collect the number in the database and, at the same time, display the actual status. This helps to save a lot of space and still to display the required data.
“The Path of the JSON”
{ "obj2testobj2Connection": "OK", "objam.testHttpConnection": "OK",
"obj2.testobj2ServerComponents": "OK", "tomcat.freememory.threshold": "2132131000", "tomcat.freememory": "OK", "tomcat.freememory.actual": "13123131121", "objam.testNFSStore": "OK" }
If you’re not sure how to get some specific value out of JSON above, use JSONPath. Don’t forget to transform the retrieved value.

JSONPath
NOTE. You can use square brackets and quotes instead of the dots.
Throttling
By default Zabbix saves all the data collected in to the database.
Before throttling
Introduction of throttling allows saving only values when they are changing, skipping the same values, which saves space and resources making the Zabbix database growing slower and perform faster
After throttling
Replacing

Replacing twice
Data replacement can give different results. So, at the first replacement step ‘Up‘ the value can be ‘1‘, at the second replacement step ‘Down‘ the value will change to ‘0‘.

Replacement steps
Data wrangling
- Boolean/Octal/Hexadecimal to decimal.
If you want to transform a boolean value to decimal, you need to transform basically one positive and one negative value. This again saves a lot of space. You can also use volume mapping to make it readable, useful, and efficient.
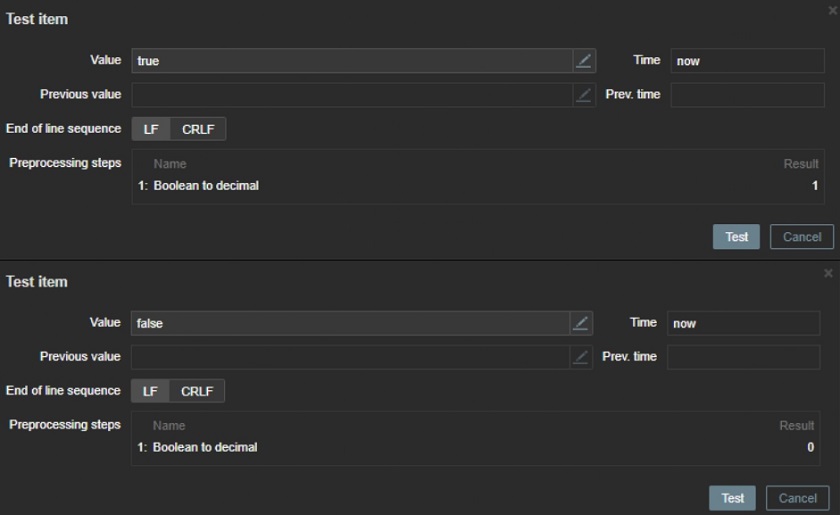
Boolean to decimal
Where
TRUE — true, t, yes, y, on, up, running, enabled, available.
FALSE — false, f, no, n, off, down, unused, disabled, unavailable.
The case when you may need to transform octal to decimal — is on memory monitoringl. Hexadecimal values are sometime retrieved from printers or other SNMP devices output.
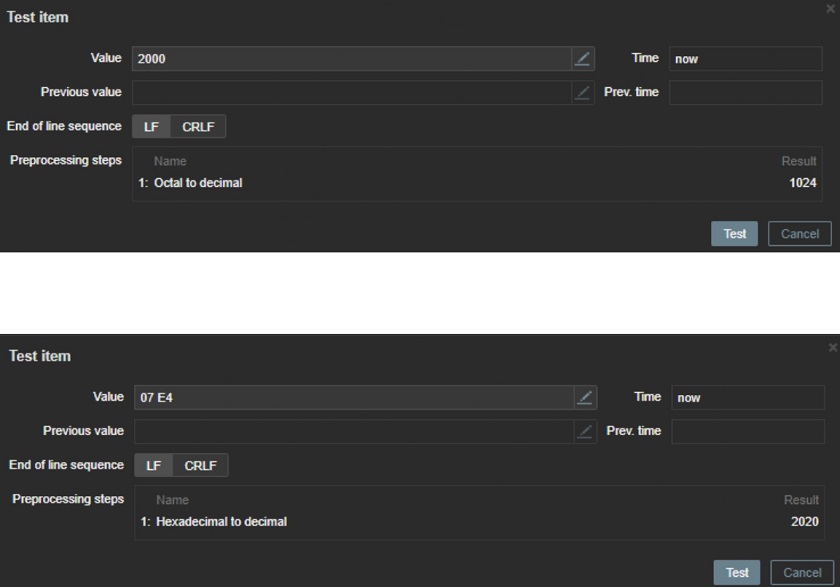
Octal/hexadecimal to decimal
- CSV to JSON.
You can simply transform CSV to JSON. But you need to make sure to have an equal amount of values in each row.
[{"Identifier":"9012","First name":"Rachel","Last name":"Booker"},
{"Identifier":"2070","First name":"Laura","Last name":"Grey"},
{"Identifier":"4081","First name":"Craig","Last name":"Johnson"},
{"Identifier":"9346","First name":"Mary","Last name":"Jenkins"},
{"Identifier":"5079","First name":"Jamie","Last name":"Smith"}]

Then you can use the result to actually find something you are looking for with JSONPath or maybe just use CSV to JSON and then put your CSV yo use in a low-level discovery rule.

CSV to JSON
- Prometheus pattern
You can define a Prometheus pattern to get a specific value and you won’t need to keep all other Prometheus output in your database. You will keep one small number by retrieving the needed value.
# HELP wmi_logical_disk_free_bytes Free space in bytes (LogicalDisk.PercentFreeSpace)
# TYPE wmi_logical_disk_free_bytes gauge
wmi_logical_disk_free_bytes{volume="C:"} 3.5180249088e+11
wmi_logical_disk_free_bytes{volume="D:"} 2.627731456e+09
wmi_logical_disk_free_bytes{volume="HarddiskVolume4"}
4.59276288e+08
wmi_service_state{name="dhcp",state="continue pending"} 0
wmi_service_state{name="dhcp",state="pause pending"} 0
wmi_service_state{name="dhcp",state="paused"} 0
wmi_service_state{name="dhcp",state="running"} 1
wmi_service_state{name="dhcp",state="start pending"} 0
wmi_service_state{name="dhcp",state="stop pending"} 0
wmi_service_state{name="dhcp",state="stopped"} 0
wmi_service_state{name="dhcp",state="unknown"} 0
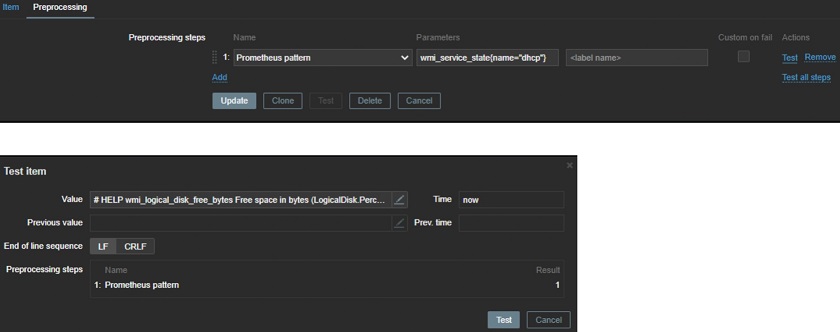
Prometheus pattern
- Simple change
Simple change — basically calculating the difference between the values — the current and the one previously retrieved and let’s you collect this diferrence.
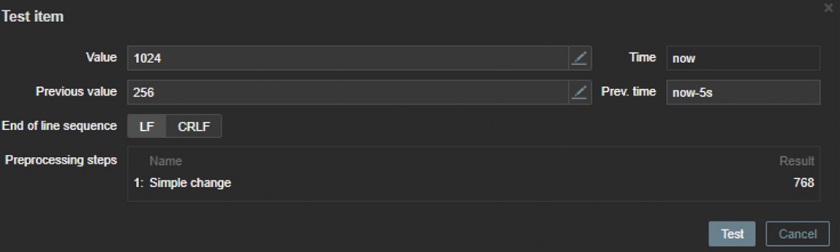
Simple change
Simple change is evaluated as:
value-prev_value
where
value — current value;
prev_value — previously received value.
This setting can be useful to measure a constantly growing value.
- Change per second
Change per second — calculating the value change (the difference between the
current and the previous value) speed per second.
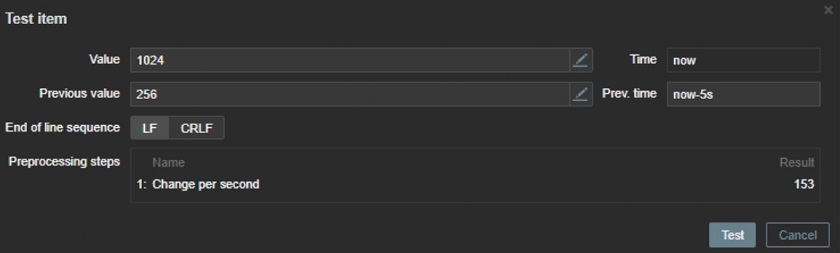
Change per second
Change per second is evaluated as:
(value-prev_value)/(time-prev_time)
where
value — current value;
prev_value — previously received value;
time — current timestamp;
prev_time — timestamp of previous value.
How it works?
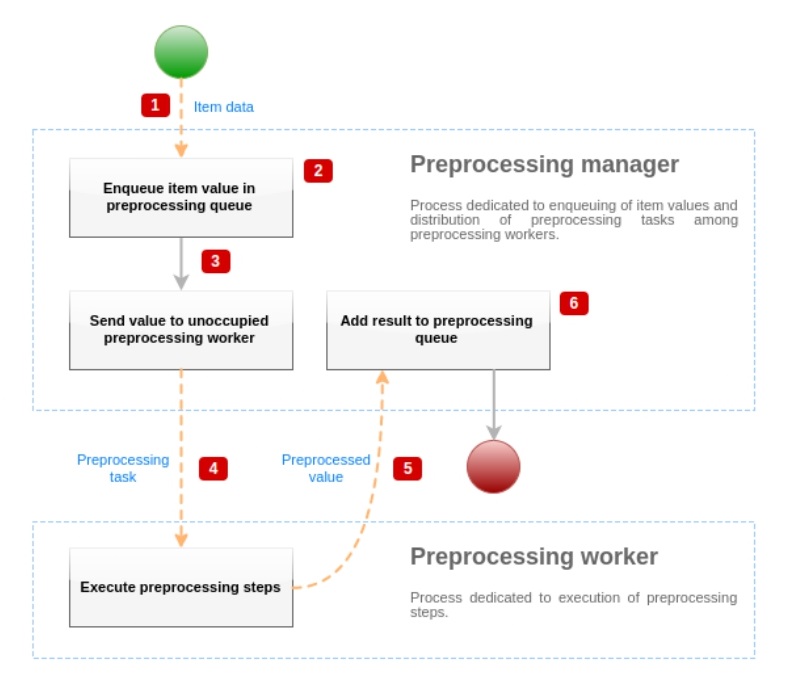
It all starts with the preprocessing manager that passes the values and stores them in the queue. The preprocessing manager checks how the pre-processing workers are loaded, which workers are currently busy or free, and depending on that tasks are assigned to a specific preprocessing worker. Then, the preprocessing worker starts executing all the tasks, and after the value is preprocessed, it will be stored in the queue. If there’s no more processing to be done with the value coming out after one of the steps, the value is transformed to the specific data type that you may use and then store in the database.
Item can be placed at the end or at the beginning of the preprocessing queue. Zabbix internal items are always placed at the beginning of the preprocessing queue, while other item types are enqueued at the end.
Zabbix 5.0 improvements
Maximum count of dependent items for one master item is now 29999 (earlier — 999)
[ZBX-17694] Memory usage became significantly lower 15K dependent items with master worth of 209 KB needed around 3 GB RAM with total busy time in manager of 2.115940 seconds, but after changes, 4.6 MB is the peak and busy time is 0.688623 seconds.
[ZBX-17720] Exclude disabled dependent items from preprocessing configuration.
[ZBX-17548] Don’t store history in Proxy DB If History storage period is 0.
Resources
- Regex — https://regex101.com
- JSONPath — https://jsonpath.com
- Xpath — http://xpather.com
- Documentation
Questions and answers
Question. Doesn’t throttling lead to gaps in the data, graphs, etc.?
Answer. In graphs, it will. But preprocessing allows you to execute one additional check in the interval that you define (heartbeat), and that will connect the graphs.
Question. Would you recommend using the ‘Replace’ preprocessing step instead of value mapping?
Answer. If you want to actually replace words with numbers, then I would recommend using ‘Replace’, but if you want to make information more human readable in the frontend – value mapping is needed. So, you may use ‘Replace’ and value mapping together to save some space and make information more readable.






Thank you very much for this document
I’m asking how to use the result/output in Preprocessing ,For ex i configured Windows Template to read event ID5074 with a Preprocessing to output only the IIS pool needs recycle and i want to run Trigger action with a PowerShell script to recycle that pool, Any idea? Thanks.