Running a monitoring platform like Zabbix in a production environment requires bulletproof availability at the database layer. Any downtime in PostgreSQL, even for seconds, can disrupt monitoring visibility, triggering blind spots in alerts and data collection.
This post introduces a streamlined High-Availability (HA) architecture for Zabbix using PostgreSQL, pg_auto_failover, HAProxy, and PgBackRest. Built on RHEL 9 or derivatives, this architecture removes single points of failure and automates failover using minimal external dependencies, making it a strong candidate for modern observability backends.
Architecture overview
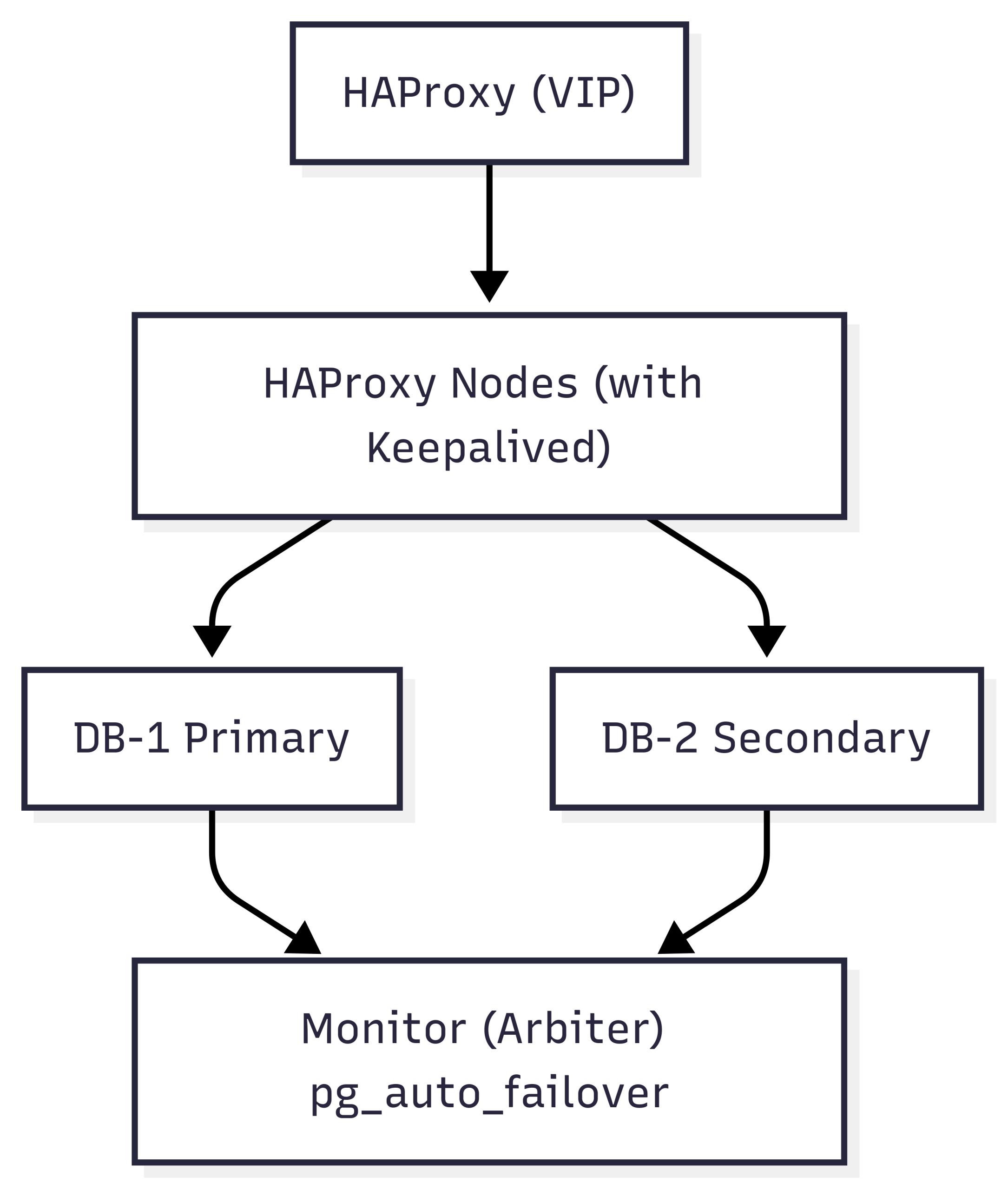
This HA design simplifies deployment by using a dedicated monitor node to orchestrate automatic failover between two PostgreSQL database nodes. With pg_auto_failover, we avoid the need for complex consensus layers like etcd or Consul while still achieving fast, reliable failover and recovery.
Database layer
Two PostgreSQL nodes are deployed in a primary/secondary configuration. These nodes are registered with a dedicated pg_auto_failover monitor, which continuously checks node health and replication status. In the event of a failure, the monitor promotes the secondary to primary with no manual intervention.
Each node is securely configured using scram-sha-256 authentication and self-signed / or owned SSL certificates to ensure encrypted communication within the cluster.
Monitor node (Arbiter)
The monitor node is a lightweight PostgreSQL instance that runs the pgautofailover extension. It holds state information about all participating nodes and acts as the arbiter during failover events. It requires only one node, reducing complexity compared to consensus-based DCS (Distributed Configuration Store) systems like etcd or ZooKeeper.
Load balancing layer
Two HAProxy nodes route all client (Zabbix) connections to the current PostgreSQL primary. A lightweight HTTP service on each DB node reports its current role (primary or not) and allows HAProxy to determine which node is writable. These proxies are kept highly available using Keepalived, which manages a shared Virtual IP (VIP) across both proxy servers.
This way, applications like Zabbix always connect to a stable endpoint, even during failover events.
Backup layer
Backups are handled using PgBackRest, deployed on a dedicated backup server. This server connects to both PostgreSQL nodes over SSH and performs the following:
- Full and incremental backups
- WAL archiving
- Point-In-Time Recovery (PITR)
Passwordless SSH and proper pgbackrest.conf mappings are set up to support seamless interaction regardless of which node is currently primary.
Component overview
| Component | Role |
| PostgreSQL | Relational backend storing all Zabbix metrics, alerts, events |
| pg_auto_failover | Ensures continuous availability by promoting replicas automatically |
| Monitor Node | Decides failover based on health checks and cluster state |
| HAProxy | Routes client traffic to the current primary |
| Keepalived | Provides VIP failover between HAProxy nodes |
| PgBackRest | Performs PITR-capable backups from any node |
| Zabbix Server | Connects to PostgreSQL via VIP to ensure continuity |
Topology at a glance
Design
Unlike Patroni, which requires a distributed configuration store like etcd, pg_auto_failover uses a dedicated monitor node that simplifies orchestration. This setup reduces the operational burden while still delivering robust failover, automatic reconfiguration, and synchronization safeguards, including:
- Synchronous_standby_names to enforce replication integrity
- Service integration with systemd for reliable restarts
- Failover detection with minimal latency
This design also ensures SSL-enabled encrypted communication, self-healing role changes, and full observability using Zabbix itself, which can be configured to monitor the PostgreSQL cluster through exposed health endpoints.
Real-world considerations
- Upgrade Planning: The pg_auto_failover version in RPM repos may lag behind the latest upstream features like set_monitor_setting. Pin the package version if consistency is required.
- Network Security: Only HAProxy nodes are allowed to query the internal role-check API on the DB nodes using custom firewall rules.
- Cluster Hygiene: Always clean up config folders (~postgres/.config/pg_autoctl/…) if a node is misconfigured or needs to rejoin.
- SELinux: Configure SELinux, use semanage and audit2allow to fix custom ports (e.g., 9877 for health checks).
- Hybrid Logging: Setup PostgreSQL to log to both journald and traditional log files via stderr + logging_collector.
Conclusion
This architecture strikes a balance between simplicity and resilience. While Patroni is great for large-scale, multi-region setups requiring distributed consensus, pg_auto_failover offers a lighter-weight solution that covers most enterprise needs without complex dependencies.
By layering the following…
- PostgreSQL 17
- Pg_auto_failover with a single monitor
- HAProxy + Keepalived for VIP failover
- PgBackRest for backups
…you can then confidently run Zabbix in a highly available and secure fashion with minimal operational overhead.
If you’re considering implementing this setup or migrating from a single-node database backend, reach out to Opensource ICT Solutions, a Zabbix Premium Partner with global presence in the USA, the UK, the Netherlands, and Belgium. We can help you architect, deploy, and monitor Zabbix environments that scale with your needs.