Abstract
Imagine your happiness when you start a new enterprise device and application monitoring project using Zabbix[i]. Getting started is so easy, and the first results bring a lot of satisfaction very quickly. It’s a great feeling when you apply a specific template [ii]in a specific host and the data arrives like magic, allowing you to create and visualize some dashboards.
If you haven’t done this yet, you must try it as soon as possible. You can create a web server host using both Apache or Nginx web services, applying the appropriate template and getting metrics by HTTP checks in the “Apache by HTTP” or “Nginx by HTTP” templates. You will see interesting metrics being collected and you will be able to create and view some graphs or dashboards. But the work is not finished yet – you can do so much more using Zabbix!
In this article, I’ll talk about how we can think of new metrics and new use cases to support our businesses and gain important results and insights. I’ll also discuss how to use exploratory data analysis to introduce and implement some data science concepts using only Zabbix.
What is our goal?
Testing and learning some new Zabbix functions introduced from the 6.0 version, while comparing some results and discussing insights.
Contextualizing
While we’ll focus on the web server metrics, all the results of this study can be used later in different scenarios.
The web server runs nginx version 1.18.0 and we are using the “Nginx by HTTP” template to collect the following metrics:
- HTTP agent master item: get_stub_status
- Dependent items[i]:
Nginx: Connections accepted per second
Nginx: Connections dropped per second
Nginx: Connections handled per second
- Simple check items:
Nginx: Service response time
Below we have a simple dashboard created to view the initial results:
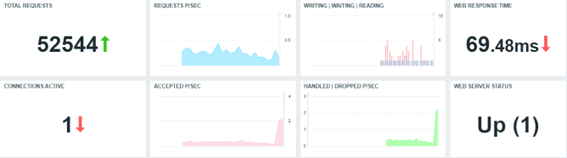
All widgets reflect metrics collected by using the out-of-the-box “Nginx by HTTP” template.
Even if we are Zabbix specialists and have some knowledge about our monitored application, there are some questions we need to ask ourselves. These questions do not need to be exhaustive, but they are relevant for our exercise. So let’s jump to the next topic.
Generating new metrics and bringing up some thoughts
Let’s think about the collected metrics at the beginning of this monitoring project:
- Why the does number of requests only increase?
- When did we have more or fewer connections, considering (for example) the last hour?
- What’s the percentage change when comparing the current hour with the previous one?
- Which value can represent the best or worst response time performance?
- When considering some collected values, can we predict an application’s downtime?
- Can we detect anomalies in an application based on the amount of collected values and application behavior?
- How to establish a baseline? Is it possible?
These are just some of the questions we intend to answer using this article and the next ones to come.
Generating new metrics
First, let’s create a new template. Clone “nginx by HTTP” and change its name to “Nginx by HTTP modified.”
Next, modify the “Nginx: Requests total” item, adding a new pre-processing step “Simple change.” It will look like the image below:
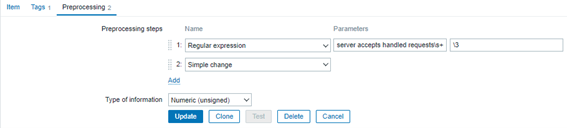
It’s a dependent item from the master item “Nginx: Get stub status page” and the last one is based on an HTTP agent to retrieve the main metric. So if the number of the total connections is always increasing, the current value will decrease from the last collected value. After a simple subtraction, we’ll have the number of new connections per minute.
The formula for the “Simple change” pre-processing step can be represented using the following images:

I also suggest that you change the name of the item to: “Nginx: Requests at last minute.”
You can add some Tags[i] too. These tags can be used in the future to filter the views, among other things.
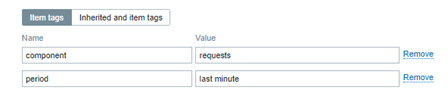
The same metrics variations
With the modified nginx template, we can retrieve how many new connections our web application receives per minute and then create new metrics. Using the Zabbix timeshift[i] [ii]function, we can create metrics, such as the number of connections:
- In the last hour
- Today so far and yesterday
- This week and the previous week
- This month and the previous month
- This year and the previous year
This exercise can be very interesting. Let’s create some calculated items with the following formulas:
sum(//nginx.requests.total,1h:now/h) # Somatório de novas conexões na hora anterior
sum(//nginx.requests.total,1h:now/h+1h) # Somatório de novas conexões da hora atual
In Zabbix official documentation we have lots of examples of how to create calculated items using the “time shift” parameter. Please, see this link.
Improving our dashboard
Using the new metrics, we can improve our dashboard and enhance the data visualization:
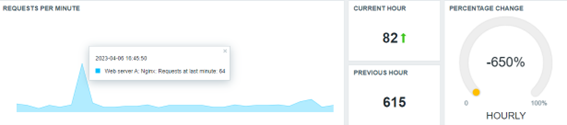
The same framework could be used to show the daily, weekly, monthly, and yearly data, depending on your business rule, of course. Please be patient because some items will have a delay in the collecting operation (monthly, yearly, etc).
Basic statistical metrics using Zabbix
As we know, it is perfectly possible to generate some statistical values with Zabbix by using calculated items. However, there are questions that can guide us to other thoughts, and some answers will come in the form of metrics, again.
- Which response time was the best today?
- What was the worst response time?
- What was the average?
We can start with these basic statistics:
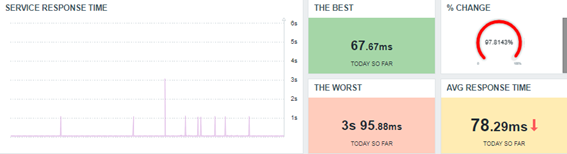
All data in the dashboard above was retrieved using simple Zabbix functions.
The best response time today so far.
min(//net.tcp.service.perf[http,”{HOST.CONN}”,”{$NGINX.STUB_STATUS.PORT}”],1d:now/d+1d)
The worst response time today so far.
max(//net.tcp.service.perf[http,”{HOST.CONN}”,”{$NGINX.STUB_STATUS.PORT}”],1d:now/d+1d)
The average response time today so far.
avg(//net.tcp.service.perf[http,”{HOST.CONN}”,”{$NGINX.STUB_STATUS.PORT}”],1d:now/d+1d)
It’s okay – nothing new so far. But let’s check some thoughts.
Why are we looking for the best, worst, and average using min, max, and avg functions, instead of trendmin, trendmax or trendavg functions? The trend-based functions retrieve data from trends tables, while history-based functions calculate in “real time.” If you want to use history-based functions to calculate something in a short period, that’s fine. But if you want to use it to calculate some values over a long period such as a month or year, it can be complicated and can take a lot of resources.
We need to remember something important – to use trend-based functions, we must consider only data retrieved until the last full hour, because we have to consider the trend-cache sync process.
Look at the dashboard below, this time using trend-based functions for the statistics.
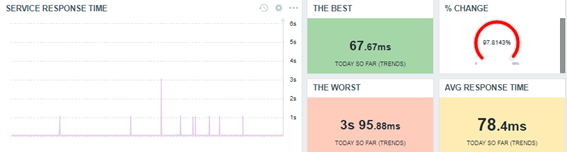
Look at the current results – basically, they are the same. There aren’t so many differences, and using it is an intelligent way to retrieve the desired values.
Insights
If a response time is too short, such as 0.06766 (the best of the day) and another value such as 3.1017 is too big and represents the worst response time, can you imagine how many values exist between them?
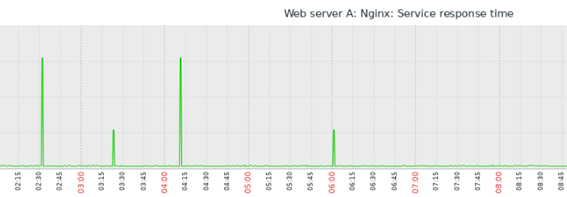
How to calculate the average? The obvious answer is the sum of all collected values within a period, divided by the number of values.
So far, so good. The avg or trendavg functions can retrieve this average based on the desired period. However, if you look at the graph above, you will see some “peaks” in certain periods. These “peaks” are called “outliers.” The outliers are influencers of the average.
The outliers are important, but the average sometimes may not represent the reality. Think about a response time of the web application having stayed between 0.0600 and 0.0777 at the previous hour. For some reason, during a specific minute within the same monitored period, the response time was 3.0123. In this case, the average will increase. But what if we discard the outlier? Obviously, the average will be as expected. In this case, the outlier was a deviation – a “glitch in the matrix.” So, we need to be able to calculate the average or other estimated location for our values without the outlier.
Remember – if we are looking for anomalies based on the web application response time, we need to consider the outliers. If not, outliers can be removed on the calculation for now.
If outliers can influence the common average, how can we calculate something without the outliers?
An introduction to median
Regarding the data timeline, we can affirm that the database is respecting the collected timestamp. Look at the collected data below:
| 2023-04-06 16:24:50 1680809090 0.06977 |
| 2023-04-06 16:23:50 1680809030 0.06981 |
| 2023-04-06 16:22:50 1680808970 0.07046 |
| 2023-04-06 16:21:50 1680808910 0.0694 |
| 2023-04-06 16:20:50 1680808850 0.06837 |
| 2023-04-06 16:19:50 1680808790 0.06941 |
| 2023-04-06 16:18:53 1680808733 3.1101 |
| 2023-04-06 16:17:51 1680808671 0.06942 |
| 2023-04-06 16:16:50 1680808610 0.07015 |
| 2023-04-06 16:15:50 1680808550 0.06971 |
| 2023-04-06 16:14:50 1680808490 0.07029 |
For the average, the timestamp or collected order will not be important. However, if we ignore the timestamp and order the values from smallest to largest, we’ll get something like this:
| 0.06837 | 0.0694 | 0.06941 | 0.06942 | 0.06971 | 0.06977 | 0.06981 | 0.07015 | 0.07029 | 0.07046 | 3.1101 |
Table 1.0 – 11 collected values, ordered from smallest to largest
In this case, the values are ordered from the smallest one to the largest one, ignoring their timestamp.
The timeline has an odd number of values and the value in bold is the central (median) value. And what if it was an even number of values? How could we calculate the median? There is a formula for it.
| 0.0694 | 0.06941 | 0.06942 | 0.06971 | 0.06977 | 0.06981 | 0.07015 | 0.07029 | 0.07046 | 3.1101 |
Table 2.0 – 10 collected values, ordered from smallest to largest
Now, we have two groups of values. There is not a central position.
This time, we can use the median formula (in general): Calculate the average for the last value for the “Group A” and the first value for the “Group B.” Look at the timeline below and the values in green and orange.
Percentile in Zabbix
Despite considering the concept of the median, we can also use the percentile calculation.
In most cases, the median has a synonymous “fiftieth percentile.”
Here is a useful exercise:
1. Create a Zabbix trapper item and send to it the following values using zabbix-sender:
0.06837, 0.0694, 0.06941, 0.06942, 0.06971, 0.06977, 0.06981, 0.07015, 0.07029, 0.07046, 3.1101
# for x in `cat numbers.txt`; do zabbix_sender -z 159.223.145.187 -s “Web server A” -k percentile.test -o “$x”; done
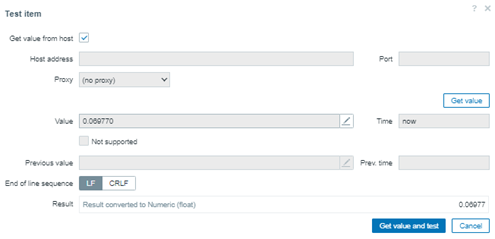
At the end, we’ll have 11 values in the Zabbix database, and we’ll calculate the fiftieth percentile.
2. You must create a Zabbix calculated item with the following formula:
percentile(//percentile.test,#11,50)
In this case, we can consider the last 11 values and return the value in the fiftieth position in the array. You can check the result in advance using the “Test” button in Zabbix.
Now, we’ll work with an even number of values, excluding the value 0.06837. Our values for the next test will be:
0.0694, 0.06941, 0.06942, 0.06971, 0.06977, 0.06981, 0.07015, 0.07029, 0.07046, 3.1101
Before sending the values with zabbix-sender again, please clear the history and trends for this calculated item and then adjust the formula:
percentile(//percentile.test,#10,50)
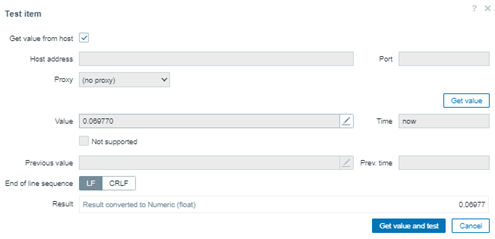
Checking the result, something curious happened – the fiftieth percentile was the same value.
There is a simple explanation for this.
Considering the last 10 values, in green we have “Group A” and in orange, we have “Group B.” The value retrieved using the fiftieth percentile formula occupies the same position in both the first and second tests.

We can test it again, but this time let’s change the formula to the fifty-first percentile. The next value will be the first value for the second group.
percentile(//percentile.test,#10,51)
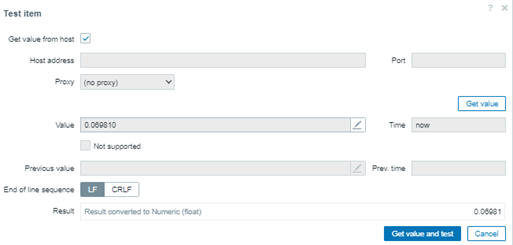
The result changed. Now we have something different to work, and then in the next steps we’ll retrieve the median.
The percentile can be considered the central value for an odd number of values, but when we have an even number of values, the result cannot be as expected.
Average or percentile?
Two different calculations. Two different results. Neither is wrong. Both values can be considered correct, but we need some context for this affirmation.
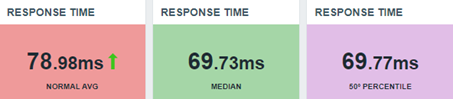
The average considers the outliers. The last one (percentile) does not.
Let’s update our dashboard:
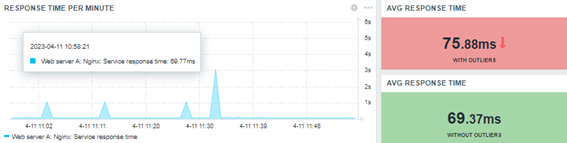
We don’t need to prove anything to anyone about the values, but we need to show the values and their context.
Median
It’s simple – if the median is the central value, we can retrieve the average for the fiftieth percentile and fifty-first percentile, in this case. Remember, our new connections are being collected every minute, so at the end of each hour we’ll have an even number of values.
This means that we can calculate the median in a simple way:
(last(//percentile.50.input.values)+last(//percentile.51.input.values))/2
This is the median formula in this case, using Zabbix. Let’s check the results in our dashboard.
Partial conclusion
In this article, we have explored some Zabbix functions to calculate basic statistics and bring up some insights about a symbolic web application and its response time.
There is no absolute truth about these metrics, but each one of them needs a context.
In exploratory data analysis, asking questions can guide us to interesting answers, but remember that we need to know where we are going or what we wish.
With a solid knowledge of Zabbix, we can perform a Data Scientist’s function.
You don’t need to use python or R for all tasks in data science. We’ll talk about it in the next articles in this series.
Remember – Zabbix is your friend! Let’s learn Zabbix and get wonderful results together!
_____________
[1] Infográfico Zabbix (unirede.net)
[1] [1] https://www.unirede.net/zabbix-templates-onde-conseguir/
[1] https://www.unirede.net/monitoramento-de-certificados-digitais-de-websites-com-zabbix-agent2/
[1] Tagging: Monitorando todos os serviços! – YouTube
[1] [1] Timeshift – YouTube