




Often host level maintenance is too much. Picture a machine running multiple services: While one service has a scheduled downtime, others continue their work and you want to be alarmed about them. Zabbix has no maintenance on trigger level at present, but you can work around it quite easily.
Traditional approaches:
- Define time spans in trigger expressions. That, of course, becomes totally fragmented for many triggers. There’s also a length limit on trigger expressions, which can limit use, particularly when multiple time spans are used per trigger.
- Define custom action conditions, like on hostname, template or time. This can get messy quickly.
- Spread the services on multiple fake hosts, while they are actually on one host — not very elegant either.
A different approach:
We’re going to use trigger dependency and let triggers represent the maintenance periods. Those triggers can either reside on a single fake host, exclusively made up for our purpose, or on the host in question for maintenance. We’ll walk through the approach with the fake host.
Let’s create the fake host and call it “backup_and_maintenance”. Zabbix doesn’t let you create a trigger without specifying an item. We therefore add an item to the fake host. The details don’t really matter, as long as Zabbix doesn’t disable the item. We can make it a trapper item, call it “maintenance” and leave everything else at its defaults. Notice, the item does not have to receive any data in order to do its job.
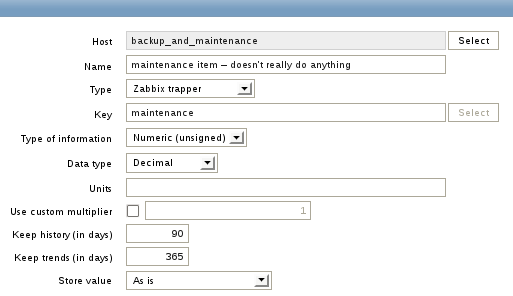
Let’s assume we have a machine that backs up a database between 2 and 3 AM. The DBMS subsequently is not running in this time span. Other services continue their work. We’ll create a trigger on backup_and_maintenance, reflecting this. This is where the newly created item comes in. The trigger function we’re using is time based. That means, the trigger will be evaluated every 30 seconds — regardless of new data arriving for this item. Don’t let the zeros in the brackets confuse you — they’re ignored.
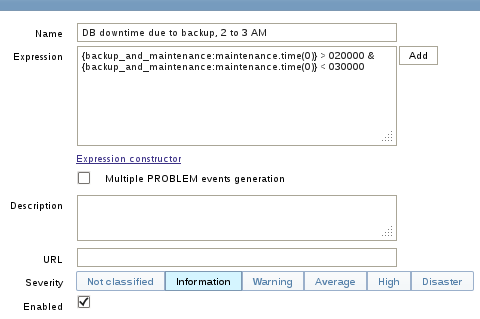
What is going to happen now? Our newly created trigger will evaluate to PROBLEM state every day between 2 and 3AM. I suggest to not run any action on this trigger — you won’t want to be notified. You can also hide this trigger away from the dashboard, using a dashboard filter, so it doesn’t bother you.
How does that help with maintenance now? We’ll create a dependency on this trigger now, in order to mask out undesired triggers.
The machine from our example might have a trigger like this:
{my_services_host:proc.num[postmaster].last(0)}=0
That’s the one we don’t want to give us an alarm between 2 and 3. Just let it depend on our trigger from backup_and_maintenance.
You just added a trigger level maintenance to your database monitoring. At 2AM, the trigger on backup_and_maintenance kicks in. The trigger from the database host will not evaluate to PROBLEM, because it depends on the trigger from backup_and_maintenance.
The strength of this approach becomes visible with scale. If you happen to have 20 machines of this kind, all going down at the same time, just add the same dependency there. Of course you can also create more and also more complex triggers on backup_and_maintenance and use as many as you like as dependencies for your triggers in question. In case you worried: Permissions on backup_and_maintenance don’t pose a problem. Dependency will always work properly.

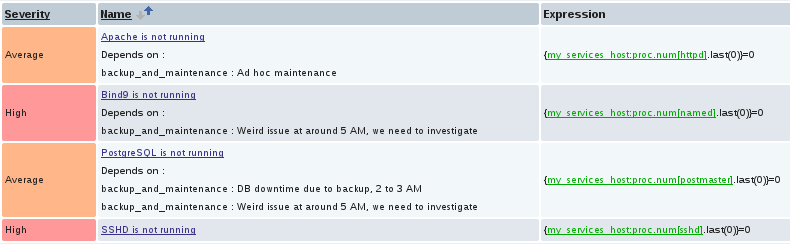
How does it compare with regular maintenance?
This kind of maintenance does not exactly behave like the regular maintenance in some regards:
- The hostname won’t turn orange in the frontend
- Data collection can’t be stopped
- You can’t see at the first glance which triggers or hosts really depend on any of the maintenance triggers
The following queries can be used to work around the last problem.
First find out the triggerid of the backup_and_maintenance trigger and put it into this SQL query:
SELECT h.host, i.description AS item, t.description AS trigger FROM trigger_depends AS d JOIN triggers AS t ON t.triggerid = d.triggerid_down JOIN functions AS f ON f.triggerid = d.triggerid_down JOIN items AS i ON i.itemid = f.itemid JOIN hosts AS h on h.hostid = i.hostid WHERE d.triggerid_up = <your_maintenance_trigger_id>;
Or query for all triggers on the backup_and_maintenance host:
SELECT h.host, i.description AS item, t.description AS trigger, t2.description AS "maintenance trigger" FROM trigger_depends AS d JOIN triggers AS t ON t.triggerid = d.triggerid_down JOIN functions AS f ON f.triggerid = d.triggerid_down JOIN items AS i ON i.itemid = f.itemid JOIN hosts AS h on h.hostid = i.hostid JOIN triggers AS t2 ON t2.triggerid = d.triggerid_up AND t2.triggerid in (SELECT t.triggerid FROM hosts AS h JOIN items AS i ON i.hostid = h.hostid JOIN functions AS f ON f.itemid = i.itemid JOIN triggers AS t ON f.triggerid = t.triggerid WHERE h.host = 'backup_and_maintenance');
Other things to do:
- Run ad-hoc maintenance: Create a trigger that always evaluates to PROBLEM and set up dependency as desired. Maintenance will take less than 30 seconds to become active. See above screenshot for one possibility to construct such a trigger!
- Construct a view in the frontend to give you the above information. This has become a lot easier in 2.0.






This is very clever! Nice touch!
Marcel
Hi,
An other solution is, if you want to disable trigger mails during a specific period, to exclude the trigger from the problems report and recreate an action specific for the trigger, specifying the period when we want to bring a mail.
Romain.