




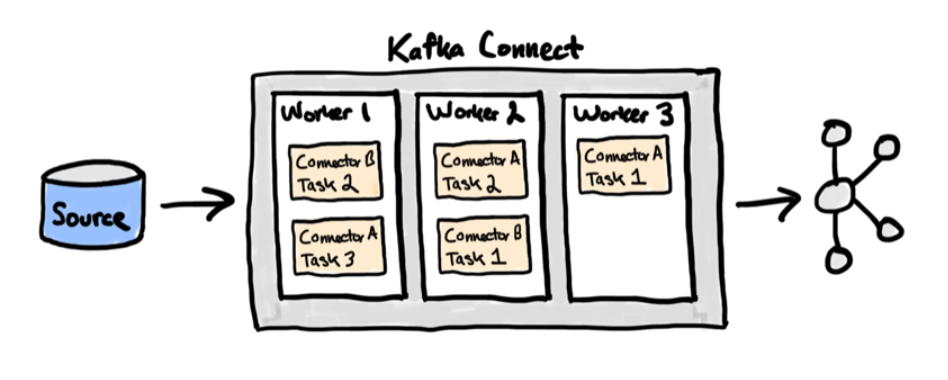
In this post, we will talk about the low-level discovery of Kafka connectors and tasks. When a Kafka task fails, a trigger is fired, which starts a remote command to restart the failed Kafka task. Of course, with the necessary logging around it.
You can find the template and scripts on the Zabbix share. But first, let’s talk a little bit about Kafka producers and consumers. Let’s say you have got a couple of connectors set up, pulling data from Postgres with Debezium and streaming it into Elasticsearch. The Postgres source is a bit flaky and goes offline periodically. If you view the status of the Postgres source, the producer, you noticed the task is failed. Kafka does not restart the failed task out of the box. We don’t wait for the customer to complain, but we let Zabbix actively monitor the tasks. A failed connector task is easy to restart using the Rest API. But manually restarting and watching a task is annoying. We used to do that at our business. Now Zabbix comes into play and restarts the failed Kafka task automatically. And we do sleep well.
About Kafka
Apache Kafka is a community distributed event streaming platform capable of handling trillions of events a day. Initially conceived as a messaging queue, Kafka is based on an abstraction of a distributed commit log. Since being created and open-sourced by LinkedIn in 2011, Kafka has quickly evolved from messaging queue to a full-fledged event streaming platform.
First, let’s do a curl and check the failed connector task.
curl -s "http://localhost:8083/connectors"|
jq '."connector_sink-test"| .status.tasks'
[{
"id": 0,
"state": "RUNNING",
"worker_id": "connect1.test.com:8083"
},
{
"id": 1,
"state": "FAILED",
"worker_id": "connect2.test.com:8083"
}]
So this is where the fun starts – we have a connector task with id “1” which has failed. At the end of the blog, Zabbix restarts the connector, but first, let’s look at an example. This curl post should restart the connector task: connect2.test.com id:1
curl -X POST http://localhost:8083/connectors/connect2.test.com/tasks/1/restart
Low-level discovery
The zabbix_kafka_connector template does work out of the box. To implemented the use cases provided in this blog you will need the scripts bundled together with the template. Kafka connectors can have multiple tasks. First, we determine the connectors and later the state of the connectors and tasks. Let’s run the following script – api_connectors.sh. I suggest you execute the script via a cronjob every 5 minutes, depending on your priority to run the curl jobs.
api_connectors.sh
curl http://localhost:8083/connectors?expand=status | jq > check_connectors curl http://localhost:8083/connectors | jq .[] > get_connectors
It creates two files, check_connectors, and get_connectors. Needless to say, we use curl with authentication in the production environment.
The next shell script get_connector_data.sh uses check_connectors and get_connectors files as input. It defines the connector {#CONNECTOR} and the connector tasks {#CONNECTOR_ID} with the corresponding ID used by low-level discovery. Down the line it might be more efficient to rewrite it as a python script. Json query is our useful friend here. The script is used by a user parameter later on.
get_connector_data.sh
#!/bin/sh
CONNECTOR=$(cat get_connectors)
CONNECTOR_IDS=$(cat get_connectors | tr -d ")
FIRST="1"
#create zabbix lld discovery connectors
echo "{"
echo " "data":["
for i in $CONNECTOR
do
if [ "$FIRST" -eq 0 ]
then
printf ",n"
fi
FIRST="0"
printf " {"{#CONNECTOR}": $i}"
done
#create zabbix lld discovery task connectors
for i in $CONNECTOR_IDS
do
IDS=$(cat check_connectors | jq --arg i ${i} -r '."'${i}'"| .status.tasks[].id')
for z in $IDS
do
if [ "$FIRST" -eq 0 ]
then
printf ",n"
fi
FIRST="0"
printf " {"{#CONNECTOR_ID}": "${i}-${z}"}"
done
done
#
printf "n ] n}"
Part of the script output will look like this, depending, of course, how many connectors there are and tasks in your Kafka environment.
{
"data":[
{"{#CONNECTOR}": "source_invoices-prod"},
{"{#CONNECTOR}": "employee_sink-prod"},
{"{#CONNECTOR_ID}": "ource_invoices-prod-0"},
{"{#CONNECTOR_ID}": "source_invoices-prod-1"},
{"{#CONNECTOR_ID}": "employee_sink-prod-0"},
{"{#CONNECTOR_ID}": "employee_sink-prod-1"},
{"{#CONNECTOR_ID}": "employee_sink-prod-2"},
{"{#CONNECTOR_ID}": "employee_sink-prod-3"}
]
}
Template.
We will define a template with the LLD rule in it and later attach the template to a host. Create a template Configuration > Templates > Create template. Give it a name according to your choice: Template_kafka_connector or some other name, depending on your template naming policies.
Discovery rule
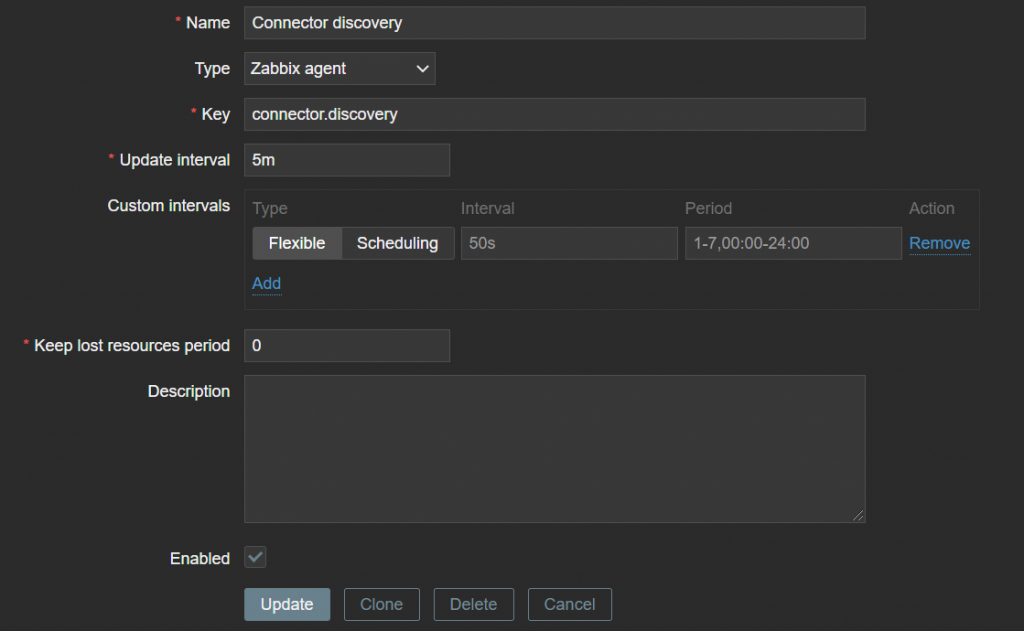
Next, we create a discovery rule. Keep lost resources period is an arbitrary value here – once again, depending on your policies regarding LLD entities.
In this case, we will discard the lost resource immediately – Keep Lost resources (0). This can be a bit more database friendly, in case when Kafka creates hundreds of connectors. The update interval is the same as the cronjob interval.
Configuration > Templates > your created template > discovery > create discovery rule
The key is used by the User Parameter further in the blog
Item prototype.
We will create two item prototypes, one for the connector and one for the task of the connector with the corresponding ID of the task. The ID is important because we want to restart the correct task later.
Name: State of {#CONNECTOR} connector
Key: state[{#CONNECTOR}]
Configuration > Templates > your created template > item prototypes > create item prototype

Trigger prototypes
Four trigger prototypes have been created. They are sets of two. The sets have different severities. The highest severity only fires after six hours and is intended for the operation center. Most times, Zabbix will restart the failed task within 5 or 10 minutes. It is then not necessary to burden the operation center with this. I will explain the most important trigger. This trigger will soon be used in an action to start the remote command. The URL macro {TRIGGER.URL} is used, which determines the ID of the task that should be restarted. There are probably other solutions, but this one works well and is stable.
Configuration > Templates > your created template > item prototypes > create trigger prototype
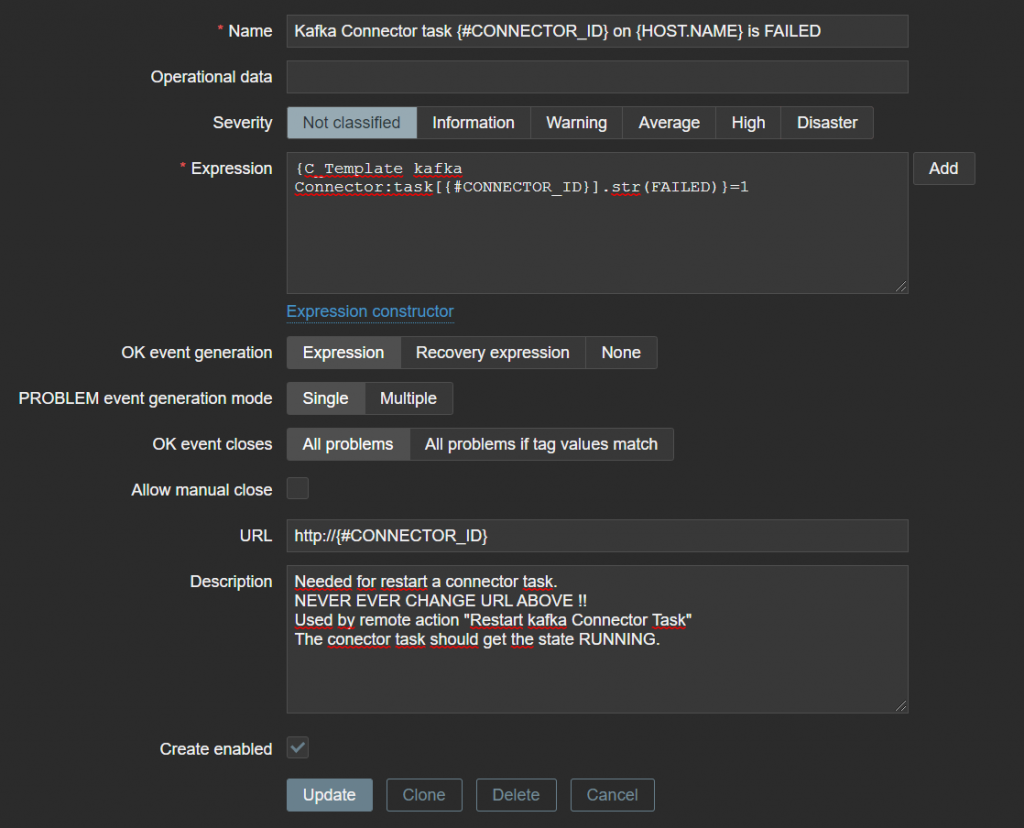
The other trigger examples are provided below.
Name: Kafka Connector task {#CONNECTOR_ID} on {HOST.NAME} is not RUNNING
Expression: {C_Template kafka Connector:task[{#CONNECTOR_ID}].str(RUNNING,6h)}=0 and {C_Template kafka Connector:task[{#CONNECTOR_ID}].str(FAILED)}=1
Severity Warning
Name: Kafka Connector {#CONNECTOR} on {HOST.NAME} is FAILED
Expression: {C_Template kafka Connector:state[{#CONNECTOR}].str(FAILED)}=1
Severity: Not classified
Name: Kafka Connector {#CONNECTOR} on {HOST.NAME} is not RUNNING
Expression: {C_Template Kafka Connector:state[{#CONNECTOR}].str(RUNNING,6h)}=0 and {C_Template Kafka Connector:state[{#CONNECTOR}].str(FAILED)}=1
Severity: warning
Userparameter
Three User Parameters are required—one for the low-level discovery and two for the items.
UserParameter=connector.discovery,sh /etc/zabbix/get_connector_data.sh UserParameter=state[*],/etc/zabbix/check_connector.sh $1 UserParameter=task[*],/etc/zabbix/check_task_connector.sh $1
check_connector.sh script gets the state of the connector.
#!/bin/sh
CONNECTOR="$1"
cat /etc/zabbix/check_connectors | jq --arg CONNECTOR "${CONNECTOR} " -r '."'${CONNECTOR}'" | .status.connector.state'
check_task_connector.sh Does a check on the connector task. A disadvantage of this construction is that the connector can have a maximum of 10 tasks. At ID -10 or higher, the check fails. But that’s unusual in Kafka to deploy a connector with so many tasks.
#!/bin/sh
value=$1
CONNECTOR=$(echo ${value::-2})
IDS=$(echo ${value:(-1)})
cat /etc/zabbix/check_connectors | jq --arg CONNECTOR "${CONNECTOR}" --arg IDS '${IDS}' -r '."'${CONNECTOR}'" | .status.tasks[]| select(.id=='$IDS').state'
Zabbix-agent
When all scripts are in the right place, we make a small adjustment to the Zabbix agent config. The LogRemoteCommands option is not necessary, but it is useful for debugging. Restart the Zabbix agent afterward. Add the Kafka template to a host, and we can proceed.
EnableRemoteCommands=1 LogRemoteCommands=1
Action auto-healing
Let’s define some actions that can heal our connector tasks by automatically restarting a Kafka task with an action. Create a new action – you can choose any conditions that can be applied to your trigger.
Configuration > actions > event source – triggers > create action.

Create an operation. This can be a bit tricky. In my case, I restart the tasks every five minutes for the first half-hour. If unsuccessful, the Kafka admins will receive an email. After that, the tasks are restarted every hour for three days. In practice, this has never happened, but such a situation can occur over the weekend, for example. After three days, the operation stops and sends a final email. Usually, the task starts the first time – if not, then the second attempt is sufficient in 99% of the cases.

Restart script.
You will probably have to adapt the script to your own environment. We have built-in some extra logging. This is certainly useful during the initial setup.
#!/bin/sh
LOG=/var/log/zabbix/restarted-connector.log
value=$(echo $1 | awk -F "/" '{print $(NF)}')
echo $value
CONNECTOR=$(echo ${value::-2})
IDS=$(echo ${value:(-1)})
curl -v -X POST http://localhost:8083/connectors/"{$CONNECTOR}"/tasks/"{$IDS}"/restart 2>&1 | tee -a $LOG
echo "Connector $CONNECTOR ID $IDS has been restarted at $(date)" >> $LOG
The {TRIGGER.URL} macro is used here, not intended to be used this way out of the box by Zabbix, but it gets the job done for this use case. The awk ensures that the http: // is fetched.
If you have any other suggestions on how to improve the scripts or the templates – you are very much welcome to leave a comment with your idea!
Credits.
I am inspired by Robin Moffatt at Confluent and not in the last place my colleague Werner Dijkerman at fullstaq





Hi Ronald, Thanks for share.
What is the zabbix server version?
Hi Rodrigo,
We are running zabbix 4.4.10.
But the template runs under zabbix 5.
You might need to edit the XML to version 5.