




What are the different ways you can use Zabbix preprocessing and why you should consider implementing it in your environment? Let’s take a brief look at how Zabbix preprocessing has evolved and the technical nuances of transforming and storing your preprocessed data.
Watch the video now.
Contents
I. Introduction (1:00:56)
II. Evolution of preprocessing (1:01:43)
III. The many ways of preprocessing (1:04:34)
IV. Preprocessing under the hood (1:17:44)
Introduction
Why do we need preprocessing? Let’s say we’re retrieving a lot of data in freeform, which is not fit for calculations, aggregations, or optimal data storage.
For us to be able to aggregate this data and to optimize the data storage, it first must be preprocessed. And that’s what Zabbix provides, from preprocessing simple text to integration with Prometheus exporters in Zabbix 4.2 and CSV to JSON transformation in Zabbix 4.4, etc.
Evolution of preprocessing
Let’s take a look at where we began and where we are now.
Before Zabbix 3.4, the legacy preprocessing functionality was limited to:
- custom multipliers,
- numeral system transformations (boolean, hex, etc.), and
- delta calculations (simple changes/speed per second).
If you required more elaborate data transformations, you had to transform the data with other tools, for example – write your own scripts in Python, PHP, etc. to preprocess the data. But over time the Zabbix preprocessing functionality has evolved. What has changed?
The preprocessing tab as you all currently know it was added in Zabbix 3.4. It also introduced a variety of new approaches to transform the data before storing it in the database:
- regular expressions,
- simple trims,
- XPath and JSONPath support.
Over time Zabbix preprocessing evolved even further and extended the functionality in Zabbix 4.2. This version added even more new ways to preprocess the data:
- JavaScript and Prometheus exporter support,
- validation rules — to validate the data that you currently have,
- throttling — to discard unnecessary data,
- custom error handling — for additional human readability,
- preprocessing support by the Zabbix proxy — to offload the performance overhead from the Zabbix server to the Zabbix proxy, thus adding a lot more flexibility when it comes to scaling your zabbix instance up even further.
Zabbix 4.4, which is completely fresh at this point, improved on preprocessing functionality even more and introduced:
- XML data preprocessing via XPath,
- JSONPath aggregation and search,
- extended custom error handling,
- CSV to JSON preprocessing,
- WMI, JMX, and ODBC data collection to JSON arrays enabling preprocessing via JSONPath.
The many ways of preprocessing
Let’s have a look at the preprocessing methods, starting with the simpler ones.
Text preprocessing – a value is retrieved using a regular expression, and then it’s transformed from text, and stored as a number. If needed, we can, for example, trim a value and store it as a regular number.

Zabbix is also able to preprocess XML and JSON Structured data. XML XPath can be used for aggregations or calculations of XML data. The same can be done with JsonPath in Zabbix 4.4.

Structured data
Numeric data can be transformed with custom multipliers. It means data can be multiplied by an X amount, for example, to transform bytes to bits. For division, use decimal numbers with zero before the dot, as in the example.

Delta calculations can be used to count simple changes, such as the difference between the current and the previous values, and change per second.
Next, we are going to look into the preprocessing methods added in Zabbix 4.2, such as JavaScript support.
JavaScript is implemented in Zabbix using the Duktape engine. It enables many different approaches to preprocessing— the limit is your imagination and your scripting skills. With JavaScript you can perform:
- data transformation,
- data aggregation,
- data filtering,
- logical expressions, etc.
All this is available within Zabbix, so with the support of Javascript ours users don’t need to write custom scripts to preprocess their data externally – all of this can now be done within Zabbix.
For example, Raw diskstats output is not very usable by Zabbix without transforming the data to JSON.

Convert diskstats to JSON
The initial data is unreadable, and you need the script to make it work.

Initial data
Once the JSON script is specified, it will split the diskstats data and transform it into JSON, and then the data can be used in LLD to create items.

Preprocessed data ready for LLD
The items in the example below were created with the corresponding metrics via JavaScript.

LLD items
As for validation rules, they were introduced because custom validation logic was required. For example, if a temperature sensor fails, and we receive out-of-range temperature data, it should be discarded or an error message should be displayed.
With validation rules, we can check if:
- the value is in range,
- the value matches the defined regular expression,
- the value does not match the defined regular expression,
- We can check if there are errors in JSON/XML or we can look for errors by using regex.
In case the preprocessing fails, custom behavior can be defined:
- discard the value completely,
- set value to X,
- set error to X.
The value can be set to −1, which in all cases would mean that there is something wrong with the data or another value. A custom error message can also be displayed and made human-readable, for example, prompting the user to take a look at the sensors because the temperature is out of range.
For example, the value outside of the defined range from −100 to 100 will be discarded and not stored in the database.

Discarding the value outside of the defined range
A matched regular expression is used in the example below to check for ups and downs in the values. In case of different service status, the value will be set to ‘Unknown’, and a trigger will fire.

Matching a regular expression
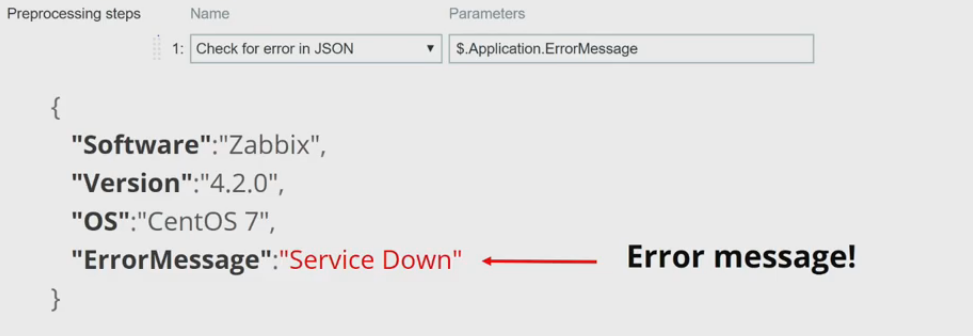
It is also possible to check for application-level error messages in JSONPath, XPath or regular expressions.
In my example, I have a check for the ErrorMessage field in JSON. If it contains data, the error message will be displayed, otherwise our data contains no errors.
Next up, Zabbix 4.2 also introduced throttling. It helps to improve performance and save database space, especially in high-frequency monitoring as it ensures minimal performance impact. This is very useful when we retrieve a lot of duplicate data at a very high frequency as in the case of industrial hardware.
In this example, data is gathered every two seconds — you just don’t want to store it as text without preprocessing. The repeating ups and downs can be ignored, and the value is just stored when it changes.
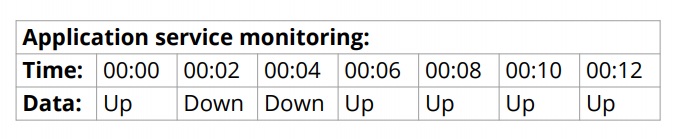
Or, a heartbeat can be defined. The data will be discarded by default and stored at the heartbeat frequency, for example, every 30 seconds.
I have some very basic examples — essentially, the same ups and downs but transformed into numbers. Data is gathered every two seconds, and before throttling was introduced, all 0 and 1 used to be stored.
Before throttling
With throttling in Zabbix 4.2, all repeated values are discarded to save a lot of space.

With throttling
Triggers will fire because data has been discarded for the past 30 minutes or so but the service has been up, unless a heartbeat is enabled. A heartbeat can help avoiding no data triggers misfiring, which can be caused by a throttling rule without a heartbeat.
 Throttling with a heartbeat
Throttling with a heartbeat
This works with everything: text files, log files, repeating text service status messages, etc. Throttling will discard all of that repeating data and just store it on heartbeats.
Starting with Zabbix 4.2, Prometheus exporters are supported. It’s yet another powerful function with an unimaginable amount of use cases:
- query Prometheus endpoint with HTTP checks;
- preprocessing to obtain metrics;
- LLD to discover components monitored by Prometheus, etc.
Prometheus exporters have a lot of custom integrations — either official or from community providers — that expose metrics of different systems:

What if I want to integrate my custom exporters with Zabbix? I can use Prometheus exporter data with a proper preprocessing rule and push that data into Zabbix.
To do that, use the Prometheus pattern preprocessing rule:
- Create a master HTTP item pointed towards the Prometheus agent — to gather all data via the HTTP item.
- Create dependent items with Prometheus pattern and retrieve the specific metric.
You can either receive a specific metric or a label value.
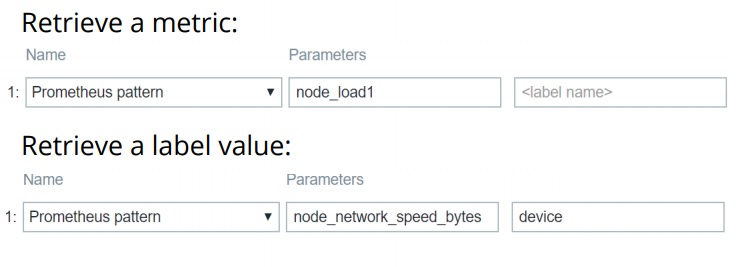
It can be even more elegant. We can use Prometheus to create a dependent item LLD with a preprocessing step to transform Prometheus to JSON and then use LLD.
In my example, I have a Prometheus to JSON preprocessing rule to grab all data on the time a specific CPU spent in a specific mode, for all modes for all of the CPUs.

Here is the JSON data retrieved.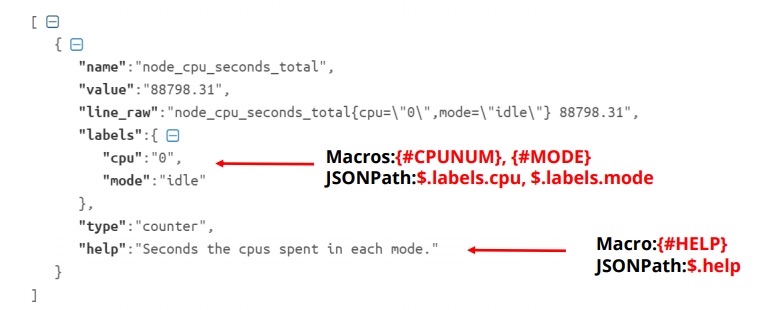
Retrieved JSON
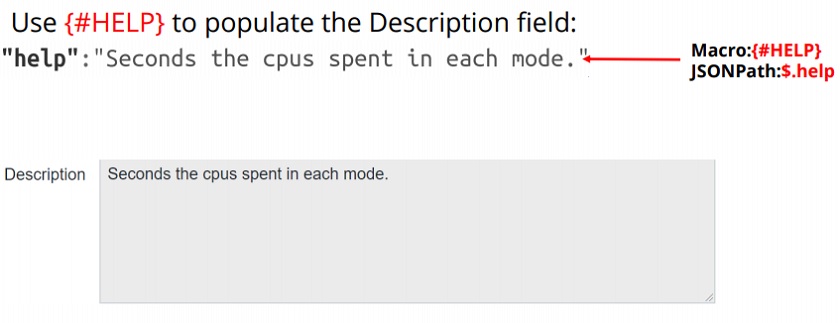
I created low-level discovery macros {#CPUNUM} and {#MODE} pointed towards specific JSONPath elements. I also use the help field to populate the description field.
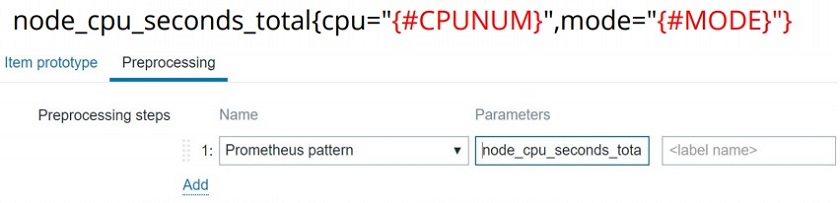
Once the LLD rule is set up, I can define my item prototype with the Prometheus pattern preprocessing step and plug the macros in for automatic discovery across all the CPUs and all the modes.
The Description field is also populated with {#HELP}.
As you can see, I have all of my CPUs for all of my modes discovered.
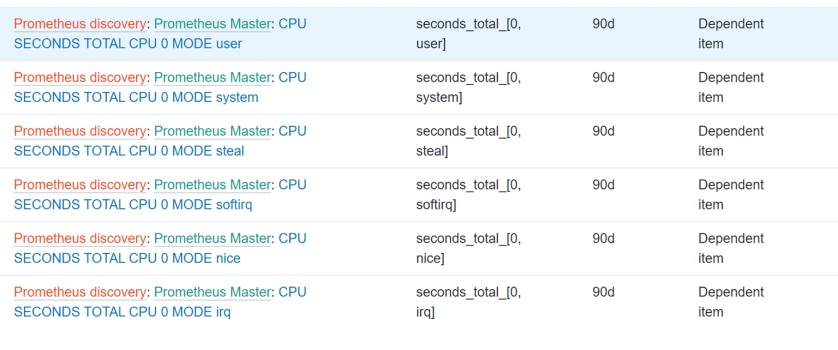
Prometheus LLD
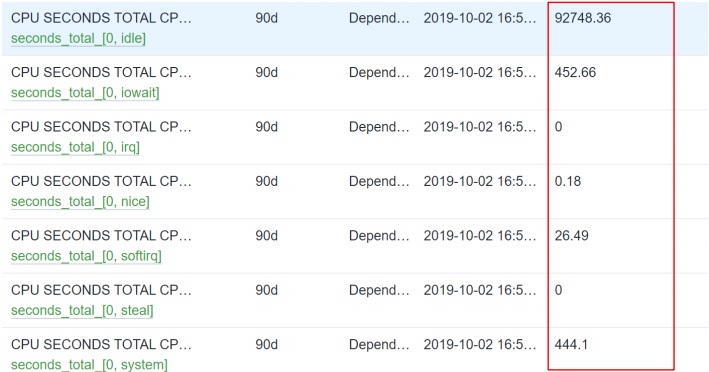
Here are the results from my default Prometheus agent. Remember that there are a lot of custom Prometheus exporters that can be integrated with databases, web servers, etc. If you are feeling really handy you can write your own Prometheus exporter to expose the data of your systems and then monitor them by Zabbix in a centralized manner.
Here are the values showing the time spent in a specific mode. You can see it is all working on a real virtual machine.
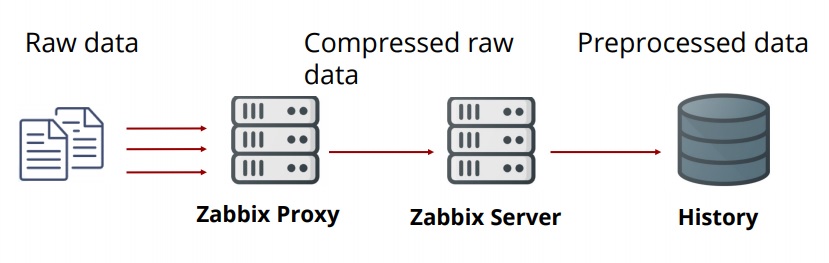
Before Zabbix 4.2, raw data was obtained from proxies. Proxies were getting raw data, compressing it, and sending it to the server where the data was preprocessed and then stored in the database.
Starting with Zabbix 4.2, proxies are doing the preprocessing.
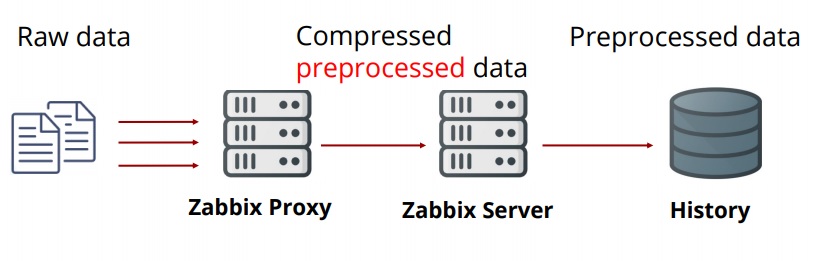 This update has a great performance benefit. You can scale up immensely with this overhead removed from the server and moved to the proxies.
This update has a great performance benefit. You can scale up immensely with this overhead removed from the server and moved to the proxies.
Preprocessing under the hood
Preprocessing workflow
Now let’s have a look at how Zabbix treats preprocessing when it comes to Zabbix internal processes.
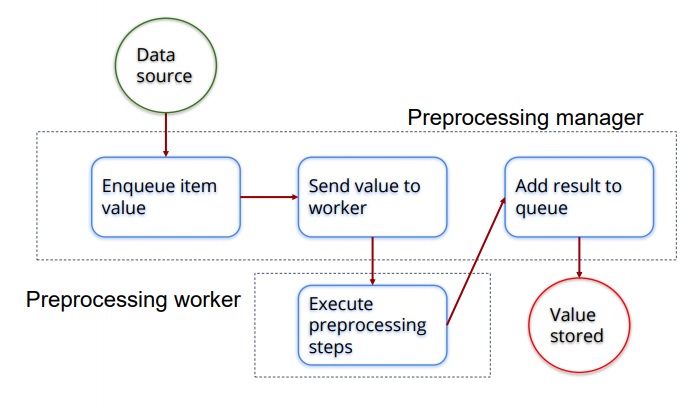
Zabbix preprocessing workflow
First, there is the preprocessing manager. It is the process introduced in Zabbix 3.4 which defines the preprocessing pattern.
- The preprocessing manager passes the values and stores them in the first-in-first-out queue.
- Once a value is stored in the queue, the manager checks if any preprocessing workers, which can be defined in the server config file, are free.
- All of the preprocessing tasks are assigned to a specific preprocessing worker so it does the preprocessing.
- Once the preprocessing worker has executed all the tasks, the value is passed back to the preprocessing manager and stored in the queue again.
- If there is no more preprocessing to be done, the data will be transformed to the specified data type (number, string, float, etc.) and stored in the database.
To define the value of preprocessing workers, use the StartPreprocessors parameter in the server configuration file. The number of workers is flexible and very much depends on how complex the preprocessing is, which is on the number of preprocessable items and preprocessing steps. Also, keep in mind that data gathering processes also directly influence the performance.
Preprocessing possibilities
To sum it up, here are the four pillars of preprocessing —why you should consider using it and what kind of benefits it can offer for your environment.
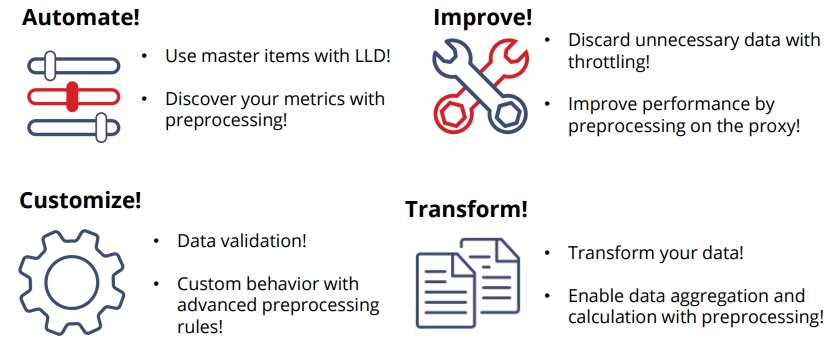
Thank you! I hope this was helpful and you’ll have fun preprocessing in Zabbix 4.2 and 4.4.
See also: Presentation slides






Amazing Post!