




Processing of XML documents were never as easy as now. Xpath preprocessing is available as a native functionality without any third party scripts or modules. Write your xpath query and use it against your XML document to extract desired value.
Watch the video now.
Contents
I. Introduction (0:02)
II. Setup (1:11)
III. About preprocessing (2:41)
IV. XPath preprocessing (3:51)
1. Full XML Output: Count of Books (7:01)
2. Full XML Output: Count of Books With Language En (10:20)
3. Full XML Output: Count of Oldest Books (12:48)
4. Full XML Output: MAX Price of all books (14:16)
V. Conclusion (16:40)
Introduction
The topic for today is a bit more interesting than usual because today I want to talk about dependent items and master items, the benefits of those and what you can get while using them, and also about preprocessing.
You know that Zabbix supports multiple types and ways of preprocessing, such as XPath, JSONPath, regular expressions, and also JavaScript from the recently released version 4.2.
Today I’ll talk just about XPath.
Setup
Let’s talk about the setup I have here today. Just like usual, I have Zabbix 4.2.1 on my virtual machine CentOS 7 running from our official Docker containers — if you don’t know about it, just check our previous video or blog post.
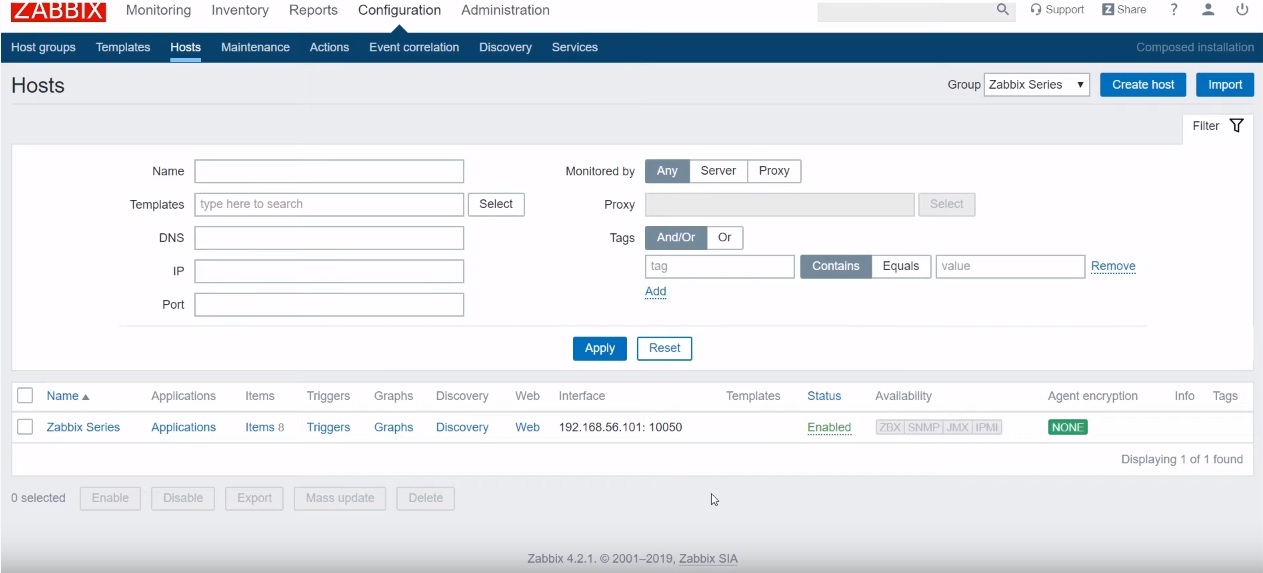
Zabbix 4.2.1
I’ve created a host called Zabbix Series and it is pointed to my virtual machine. Basically, I have just 8 items here — one master item and a couple of dependent items.
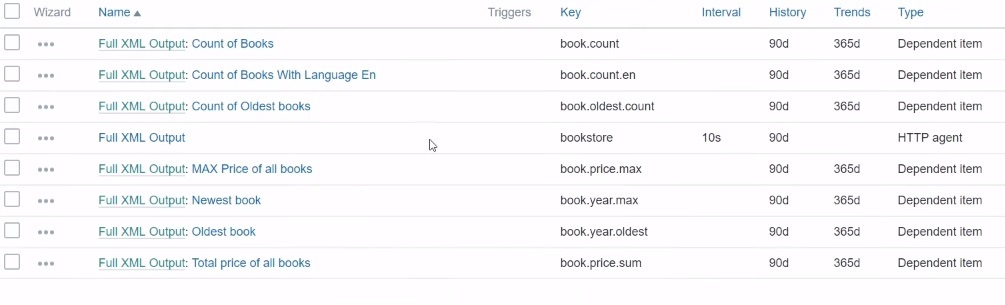
Items in the Zabbix Series host
This master item with ‘bookstore’ as the Key is an HTTP agent item.
![]()
Master item
I tried to find a service that could respond to me with an interesting XML. But I was running out of time so I just got an example XML from the Internet stored in a text file. I placed it in the directory of the Zabbix front end files so that I could use the HTTP agent item type to receive the values of this item as actual historical data and then do the preprocessing based on XPath with my dependent items.
About preprocessing
So, let me give you some background on how the preprocessing actually works. I’ve made a drawing explaining what it is.
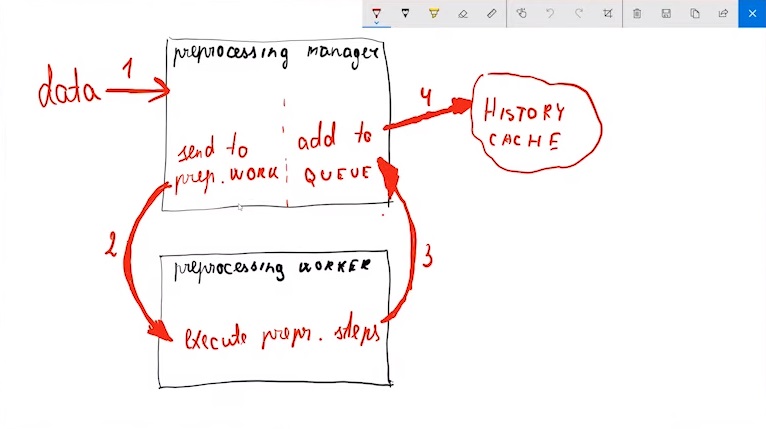
Explaining preprocessing
We have some kind of data coming in. This is raw data, not processed by any of our rules — just all the stuff that we are gathering. Then on the Zabbix side, there are basically two types of processes responsible for this task — preprocessing manager and preprocessing workers.
The preprocessing manager is the most important process determining what to do with this data. It gets the data and sends it to the preprocessing worker.
The preprocessing worker executes all the steps we have configured in the front end (today it will be XPath). Then it writes the data back to the preprocessing queue and then the preprocessed data is written to the history cache.
So, if we receive a large amount of data here, in the output we will get the desired value that we were looking for after the preprocessing by dropping all unrelated stuff.
XPath preprocessing
Let’s take a look at what we have in the front end, and start with the Full XML Output item. I will go to Monitoring > Latest data > Full XML Output > History. I have specified that I want to keep history but it is not the thing that you will actually want to do and I will explain why later.

History
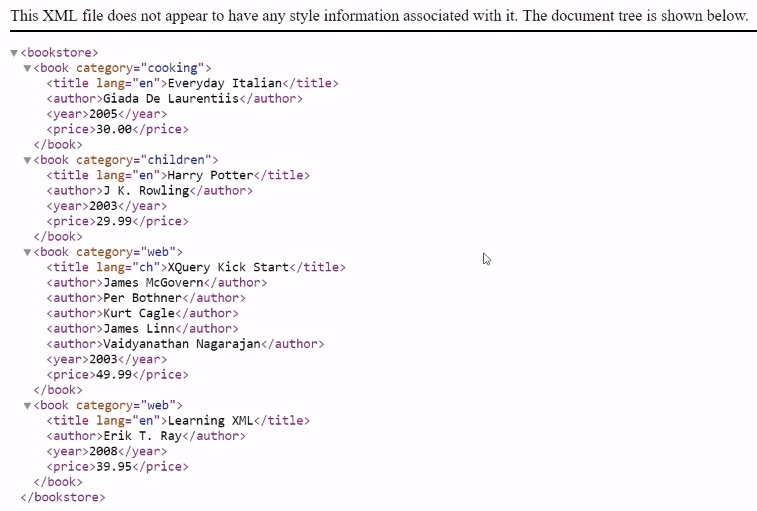
If we have a look at the example XML file above, there are a couple of categories like ‘cooking’, ‘children’, ‘web’ and information about each book like ‘title’, ‘author’, ‘year’ and ‘price’ of the book.
We, however, don’t need all this information, but only specific values, e. g., a specific price, or a year, or the name of the books. We will get to it later.
So, about history. I left the default history storage period just to be able to show you in the Monitoring > Latest data what it looks like. But actually, it is the same as you can see in the CLI. I would recommend changing the History storage period to ‘0’.
If the History storage period is set to ‘0’, all of this XML content will not be saved to the database. So what will happen? The master item receives the full XML line and then each of the dependent items performs the preprocessing on this received value and extracts the data that I’ve specified in the preprocessing steps.
After that, all this full XML document or just text will be thrown away. So, we won’t be wasting our database space. It will also positively affect the performance of Zabbix and that is definitely the best practice if you are using items to receive a big amount of the data and then just use preprocessing to extract meaningful data. Once this is done, there is no reason to keep this in the database.
Let’s continue with Xpath. Xpath was introduced in Zabbix 3.4, and it does support not only minor selections from XML to select some attributes but also all the query language so you can perform different calculations based on the XML data. For example, you can calculate the sum of prices, or get parameters of the book with the lowest price, etc.
Full XML Output: Count of Books
Let’s go one by one. Our first item will be Full XML Output: Count of Books. You see that the Type is ‘Dependent item’. I specify that the Master item is my Full XML Output item, the one which performs HTTP.
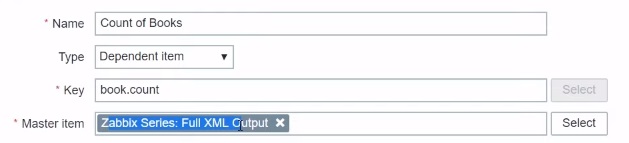
Specifying the Type of the item
Nothing is additionally configured here. The History storage period is as usual.
![]()
History storage period parameter
There is no Update interval specified because it is based on the master item. So each time this master item receives new data, my dependent items will also be populated.
The Key can be anything you want as long as you follow the syntax of Zabbix.
The most important thing is the Preprocessing tab.
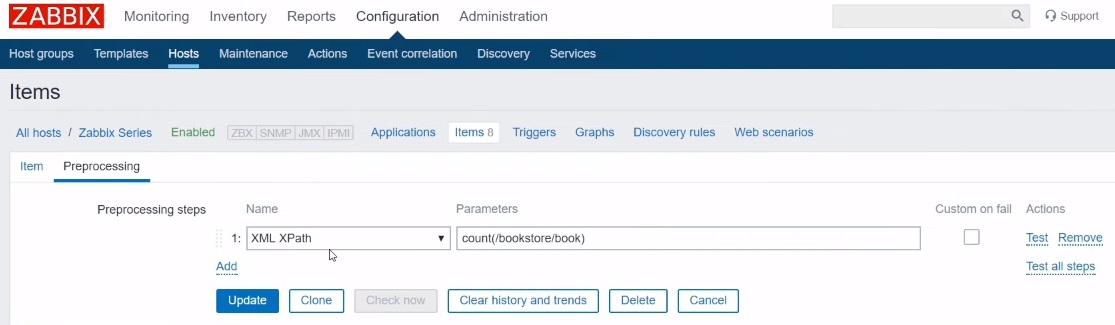
Preprocessing tab
We have only one rule — choose ‘XML XPath’ with the parameters where we actually need to specify the XPath query in the correct syntax to get an output that we want to see.
How to know all this? You can search for information about XPath on the Internet. Remember that Zabbix supports XPath 1.0 version, not the 2.0, so there will be a slight difference and limitation in terms of the query language that you can use. For example, here you can get basic examples of what XPath should look like to receive a certain result.
Let’s look at the parameters.

Preprocessing parameters
It is pretty straightforward. By reading the parameters we can understand what is happening — we are counting how many books we have in our bookstore.
Don’t forget that there is also a test functionality added in the recent release of Zabbix. So let’s say I’ve found out that I should use this parameter but I’m not sure, maybe I made a mistake. So I can click on the Test button.
Here we can already see the preprocessing step.
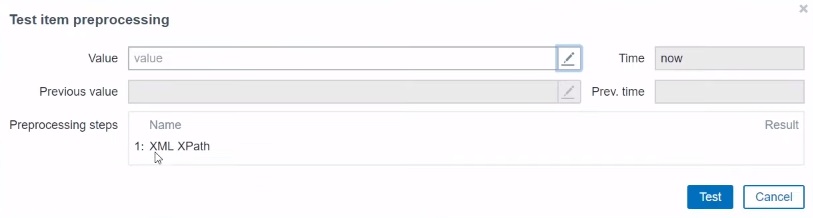
Test item preprocessing
In the Value box, copy‐paste your XML document. Click Apply and then Test. You can see the result of our XPath parameter.

XPath parameter test result
Of course, if I made a mistake in the parameters, I would also see that in the test.
Another way of testing, if you don’t want to use the Zabbix front end for some reason, is the CLI. The syntax is:
xmllint −−xpath 'query' filename.xml
In the quotes, we need to specify the XPath query that we want to use. In our case, it is ‘count(/bookstore/book)’. We also need to specify the file name, so we add bookstore.xml. And then we can have the output, which is 4.

CLI testing results
Note. If you are using an HTTP agent to receive XML from your web services, for example, a SOAP request, after each request if that XML changes, the values will also be recalculated based on the preprocessing.
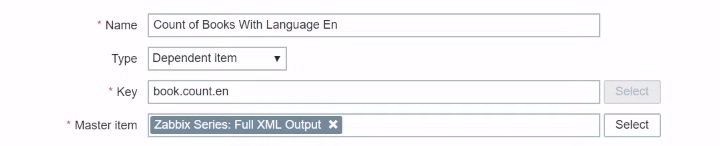
Full XML Output: Count of Books With Language En
The next item is a little bit advanced — Full XML Output: Count of Books With Language En.
![]()
Full XML Output: Count of Books With Language En
If we return to the XML file, we have here ‘bookstore’, ‘book category’, and then ‘title lang’. The books are either ‘en’ or ‘ch’. So, in total in our XML file, we have 4 books and only 3 of them are English.
Let’s say we want to calculate how many of them are in the specified language. All we need to do is to create a dependent item, fill in the Key representing what you are doing, specify the Master item which, again, will be the one which is gathering the full XML request.
Go to the Preprocessing tab and figure out the XPath query that you should use in Zabbix to receive your desired result. I am filtering for ‘only if the language is English’. After I test it out using the command above, I get 3 books, which is absolutely true because the fourth book is in Chinese.

Preprocessing parameters

Second item test
Note. Here are some XPath cheat sheets and manuals. There are also examples in the Zabbix documentation.
We can verify in the Monitoring > Latest data that we have 4 books in total and 3 books in the English language.

Full XML Output: Count of Oldest Books
Let’s try to count the oldest books by the year in the XML file. The first book is 2005, the second — 2003, the third— 2003, and the fourth — 2008. Let’s say we want to calculate, first of all, the oldest book in our bookstore and then we want to calculate how many books we have with this oldest year.
The parameters for XML XPath preprocessing look like this:

Preprocessing parameters
This is a bit non-self‐explaining syntax because we must use XPath 1.0. So we need to basically select each year and compare it with each other. If we were able to use XPath 2.0 we could just use the function min or max on some of the XML attributes.
We can test it. Copy the parameters, then type in the syntax just like we did before, paste the function and add ‘bookstore.xml’. The results say that we have 2 books with the oldest year.
Full XML Output: MAX Price of all books
The next item will be Full XML Output: MAX Price of all books.
![]()
Full XML Output: MAX Price of all books
Again, it might differ for each HTTP agent or any other type of item that gets the full output. Let’s say you want to get the maximum value. In this example, we are talking about books but it can be anything else. We might be doing monitoring on the application level, on the services or whatever else.
So, in the parameters for XML XPath preprocessing, I have ‘number’ — I am specifying that I want to receive a number. Otherwise, I would see the price in the price tags. So we have number, bookstore, book price and again the syntax for XPath 1.0 to receive the maximum price.

Preprocessing parameters
We can test this again, and the highest price from the XML is 49.99.
We could be talking about each of the rest items but actually, the logic doesn’t change. The only thing that changes is the preprocessing query of the XPath. The logic is pretty simple. We have the Full XML Output item, and the small dependent items, with each of them extracting something specific from the master item, and then it is thrown away because there is no reason to keep it inside the database.
Conclusion
Long story short, this is a very powerful tool. Before version 3.4, if you wanted to monitor XML outputs from the scripts, from the commands, all of the steps had to be done outside of the Zabbix with the scripts and then just fed to the Zabbix with the already gathered, analyzed, preprocessed, transformed values.
But with the new preprocessing functionality, we can throw away all of those custom solutions. Just get a value, analyze it with the Zabbix in the front end without any third‐party tools. Just specify XPath queries, do some more serious calculation, not only extract a specific value but select the highest price, etc. There is a lot of examples of what you can do with this and the tool itself is very powerful.
Remember that XPath is just one preprocessing type.
We also didn’t talk about Custom on fail, which is also a new functionality. If the regular expression, the XML Path or the item itself fails we can specify what we want to do — discard the value at all or set it to something pre‐configured or just set a custom error like ‘this doesn’t work’.
I think that is it from me today. Hope to see you soon again. Thank you for your time and goodbye.






Hello and thanks for information. Also would like to share the work of RUSBM STUDIO, whose services i took recently and they are doing tremendous job in architectural design. Go avail their services at resonable cost and see the results for yourself. Contact them via their website : https://www.rusbmstudio.com/
http://www.clearexam.ac.in/