




PostgresSQL is one of the supported database engines that Zabbix uses to store all configuration data and history. The popularity of Postgres makes it a very sought-after Database engine for Zabbix. TimescaleDB is a great extension to Postgres that empowers Zabbix with native partitioning functionality and data compression, which saves a lot of disk space for our users.
This post and the video are here to help you get Zabbix deployed on Postgres with TimescaleDB.
Contents
I. Why Zabbix? (1:17)
II. Architecture (4:06)
III. Getting started with PostgreSQL (9:00)
IV. TimescaleDB (14:44)
V. Conclusion (21:52)
VI. Questions & Answers (22:42)
Why Zabbix?
The first question is why Zabbix? Or, in other words, what is Zabbix? There are many monitoring solutions out there, but there are quite a few great and important benefits to Zabbix that make it stand out.
- Without diving too deep into details, Zabbix is a true open-source monitoring solution.
- Zabbix is absolutely enterprise-ready (scalable, with remote monitoring and a granular permission system, which was improved in the recent Zabbix 5.2 release). So you don’t have to worry whether Zabbix is able to monitor 1,000, 50,000, 500,000, or 1,000,000 hosts, as Zabbix can grow with your enterprise.
- You don’t have to think of Zabbix as large-scale software only meant for extremely big companies and workloads – absolutely not. If you have a small home project or a small office with a few desktops, sensors, network devices, printers, or whatever else, you can easily monitor them with Zabbix. And you don’t have to spend a lot of resources on hardware on top of that – Zabbix can run even on a simple Raspberry Pi device!
- Another important factor is that Zabbix is 100% free software. There are no paid add-ons or per-host payments, and you don’t have to pay for any metrics or any hosts that you wish to monitor. At any time, you can go to zabbix.com, click the Download button, get the product, and start using it with all the latest functionality, including all the native PostgreSQL monitoring templates.
- Zabbix offers a continuously growing list of out-of-the-box templates.
- One of the benefits of Zabbix is flexibility, which is appreciated by those who wish to gather data from complex and custom solutions. If there is something that cannot be monitored out of the box, you can easily extend Zabbix functionality and start collecting new data.
- On top of that, Zabbix can easily adapt to your needs. We know that not everybody wants to actually spend extra time creating custom templates, writing plugins or models, etc. So the Zabbix team is constantly working on releasing new official out-of-the-box templates for databases, network devices, services, applications, and many other solutions.
Architecture
The basic Zabbix architecture lets you collect and monitor any metrics — hosts, servers, databases, applications, cloud services, AWS Azure, IoT infrastructure, or whatever else.
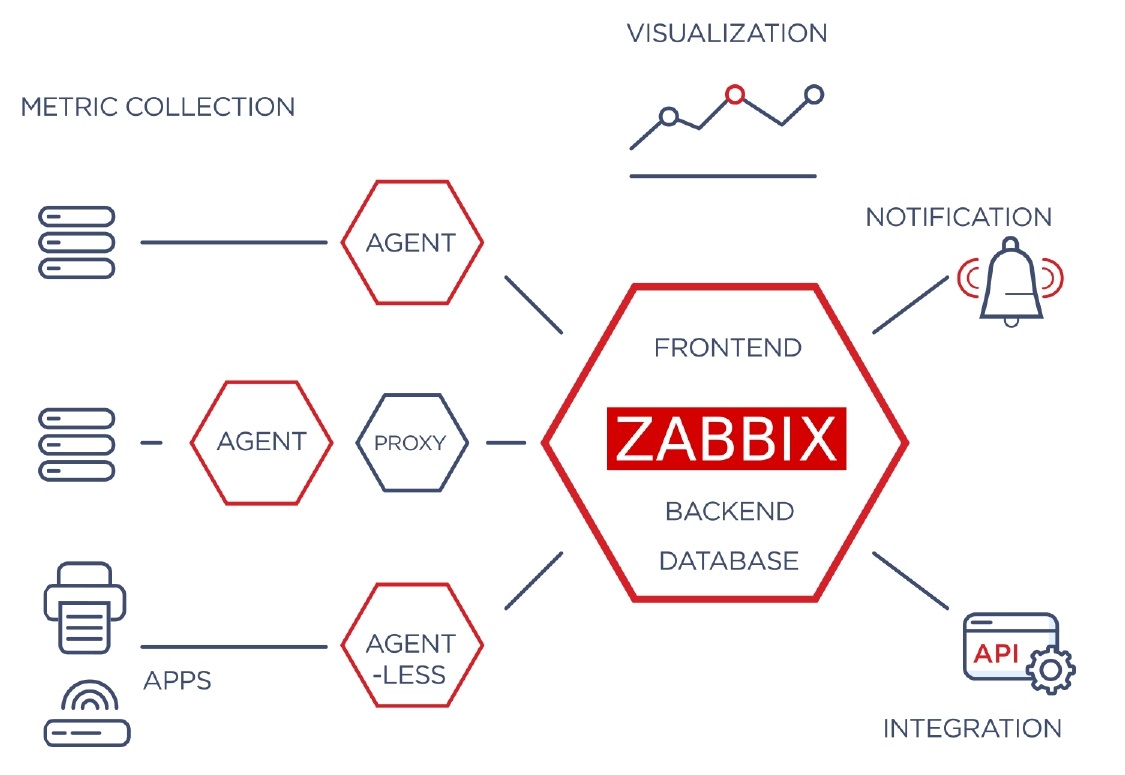
With Zabbix we can do much more than just collect the required metrics. Zabbix architecture involves the core server, which we call the Zabbix system. It’s responsible for the data visualization as we don’t just collect the data and react to it based on our triggers. Zabbix also sends notifications and lets users create their own custom dashboards and flexible graphs that can be used for visualization. A native REST API interface significantly helps create customizations and integrations with any third-party software.
If we go a bit deeper into what Zabbix is, the core Zabbix software consists of three components:
- Zabbix Frontend that we normally open in our web browser and which is used as a centralized visualization and configuration platform.
Since Zabbix is enterprise-ready and scalable, you can monitor remote branches. It doesn’t matter if you have an office in the US, somewhere in Europe, or in Japan: you can see all the data and all of the graphs in one single centralized frontend. The same applies to configuration: if you’re sitting in Riga, Latvia, and you want to add some new metrics to be monitored in Japan, you can just open your frontend, add a new host, add an item, and start monitoring.
- The next component — Zabbix Server — is the brain of the entire system, which is responsible for gathering data from the hosts and proxies, and analyzing it based on the triggers – our problem thresholds, that we have previously created in our frontend. It also tries to find problems, which may arise in our environment or in our data centers right now or, for instance, use the native predictive functions and warn us 10 days in advance.
- The final component — Zabbix Database — is the component that we will be focusing on today. At the end of the day, it’s basically the heart of Zabbix, since normally Zabbix Server and Zabbix Frontend cannot function without a properly configured database, which should be healthy in terms of performance. This is where Postgres comes into play.
Database
What do we have in the database? What is it used for?
- The database is the storage of entity configurations. Whatever we configure in our frontend, be it items, hosts, proxies, triggers, actions, or whatever else, everything is stored in this single database.
- We collect the data from our hosts and store this history data based on our settings for the period we need. This means that in situations where Zabbix is used to store a lot of data we might have a very large database. Depending on the size of the monitored environment, in more extreme cases we might be talking about a couple of terabytes of data.
- The Zabbix Server communicates with the database about the stored data, writing new history data, getting configuration data to populate our configuration cache, etc.
- On the other side, we have the Zabbix Frontend, where we might have 10, 15, 20, or 50 users working online at the same time, watching the dashboards, looking at the graphs, and adding configuration parameters.
In conclusion – The database has to be very stable and healthy in terms of performance to ensure optimal performance of all of the Zabbix components.
Supported databases
Zabbix supports several databases, including:
- PostgreSQL ( 9.2.24 or later ),
- MySQL ( 5.5.62 – 8.0.x ) and MySQL Forks,
- Oracle DB ( 11.2 or later ), and
- TimescaleDB, which is an extension for Postgres.
Getting started with PostgreSQL
If you want to use Zabbix, or you are already using Zabbix and just want to deploy another Zabbix instance for your development environment, and you decide to use Postgres as your backend database, it’s very straightforward. When it comes to deploying Zabbix the difference between Postgres and MySQL is very minor – most of the steps can be duplicated for both of these database backends.
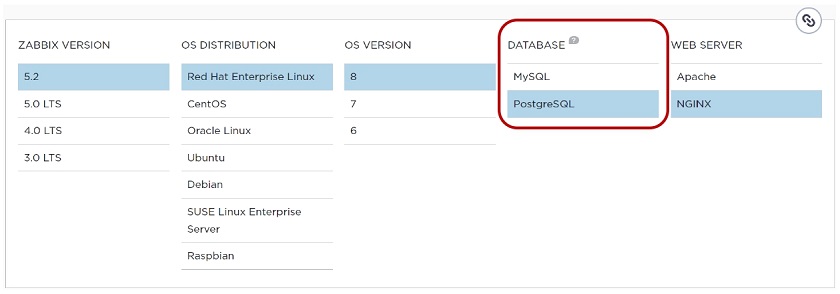
1. All we have to do is open the zabbix.com webpage, click the big green Download button and choose our platform: Zabbix version, OS distribution, OS version, database, and the web server, for instance, NGINX or Apache.
2. Then we need to follow full installation instructions to install and configure the Zabbix server for our platform.
Long story short, we have to install the packages for the core Zabbix components — Zabbix Server, Zabbix Frontend, Zabbix Agent, Zabbix Web, and adjust the configuration for Zabbix Web. The most important part here is the pgsql prefix, since we cannot download zabbix-server-mysql and use it with the PostgreSQL database.

Installing Zabbix server, frontend, and agent
Post-installation
- After we have downloaded Zabbix, we need to create a Database (just an empty database without any additions at this step), and a user for our Zabbix instance.
# sudo -u postgres createuser --pwprompt zabbix
# sudo -u postgres createdb -O zabbix zabbix
Here it comes down to two options. For beginners, you can create just one single user that we called ‘zabbix‘ here, and use it for the Frontend and for the Server. If you want to have an installation more aligned with best practices, then you should create one user for the Zabbix Server and then a separate user for the Zabbix Frontend.
- At this point, we have an empty database without any tables, but we need to import the default schema and the default data from our Zabbix instance.
# zcat /usr/share/doc/zabbix-server-pgsql*/create.sql.gz | sudo -u zabbix psql zabbix
When we install the Zabbix Server component — zabbix-server-pgsql — we can find the create.sql file in the usr/share/doc directory, which we can put inside our created Zabbix Database with a pipe command. This will import all the tables necessary for Zabbix, including the default data on the Admin User, Zabbix Server Host, and all of the templates.
- The last part will be the configuration of our Zabbix Server, which requires opening the Zabbix Server configuration file — zabbix_server.conf — and specifying the DB name, DB user, and DB password. Very simple.
DBPassword=password
Frontend configuration
If we have installed all the previously mentioned packages, we can just open a web browser and enter the IP address of the web frontend (virtual machine or physical machine), and we will be redirected to the first-time configuration wizard.
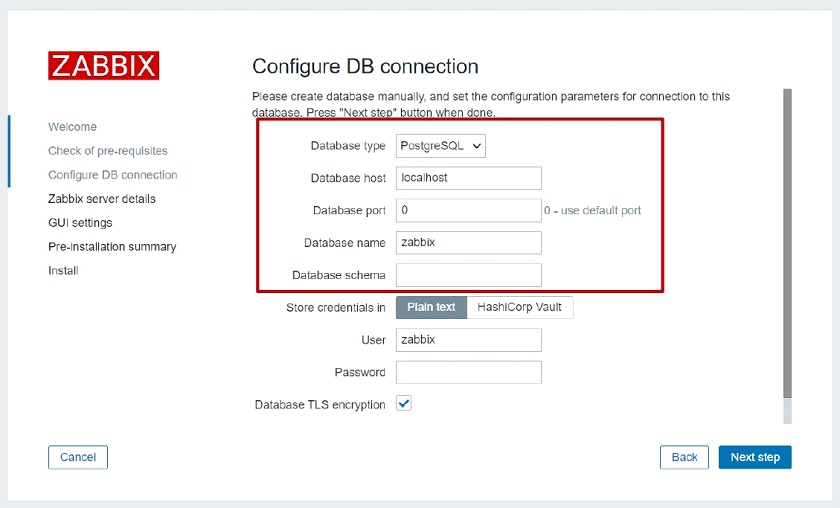
Simple configuration wizard
Here, the database type will be PostgreSQL since we downloaded the Zabbix web PostgreSQL package. Then, we just have to fill those simple parameters as a Database host. For instance, if our PostgreSQL database is stored on the same machine as the Zabbix Frontend, then it will be localhost. For a remote machine, we will have to fill in the IP address or DNS name. We also need to specify Database name, Password, and User name, and we’re good to go.
Native PostgreSQL encryption
If we want to be super secure and we don’t want the communication between the Zabbix Frontend and the Database, or between the Zabbix Server and the Database to be unencrypted, we can also enable native encryption between the Zabbix core components and our Postgres database.
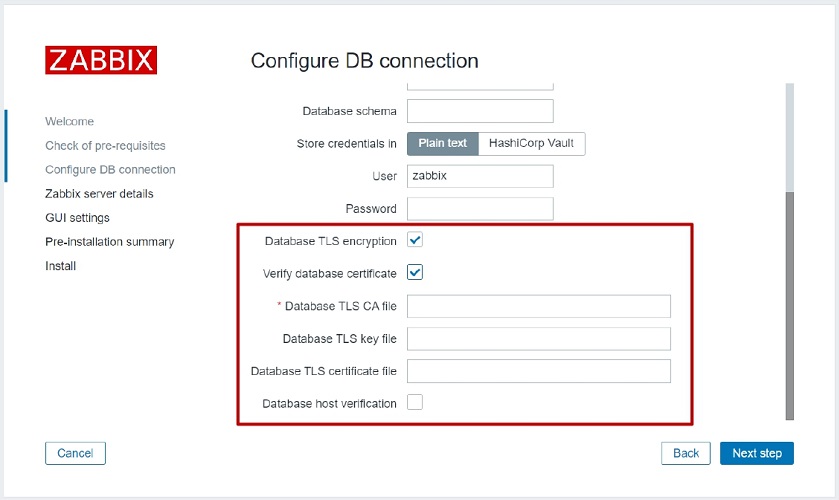
Simple configuration wizard
To enable native encryption, we have to specify the location of our CA file, TLS key file, certificate file, and choose whether we want to do host verification in the simple configuration wizard on the first-time login page. But that’s not all.
Prerequisites
- When we install the PostgreSQL database, it’s not yet ready to provide encryption out of the box. So we have to fill in a couple of parameters in the PostgreSQL configuration file — postgresql.conf:

The configuration might also differ depending on our security requirements. The lowest SSL version that is supported by our security policy might be TLS 1.3. We may have a wider list of ciphers for this encryption. In the end, it’s up to the user.
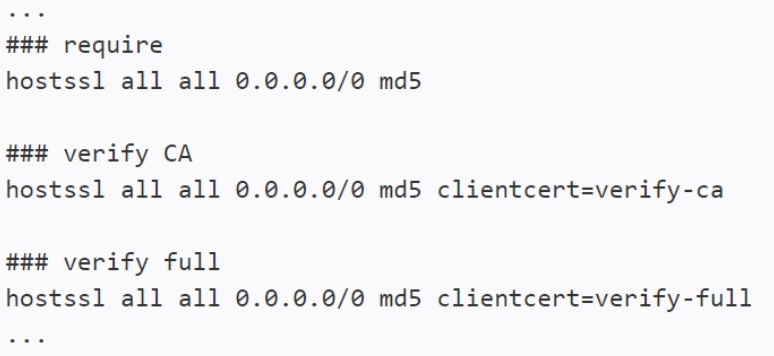
- Then we have to prepare the pg_hba.conf file where we must define that we will be using verify CA and verify full for the client certificate. That will enable the encrypted communication between Postgres and the Zabbix core components thanks to the native Postgres encryption configuration.
TimescaleDB
Now, what is the Timescale database? Timescale is still a relatively new thing.
- Timescale is not really a standalone database engine. It is an extension of the existing PostgreSQL database, which is absolutely free, so we don’t have to pay any money to use it.
- Timescale requires PostgreSQL 11 or 12. If you are planning to use Timescale on the latest version, PostgreSQL 13, you have to check if it is supported.
- The idea behind Timescale is working with time-series data. Right now, Zabbix has around 170 tables with five of them for history data and two for trends, where we can actually use the benefits of Timescale.
- The greatest benefit in terms of Zabbix is that TimescaleDB offers native partitioning in Zabbix and lets us compress the heaviest tables.
Native partitioning
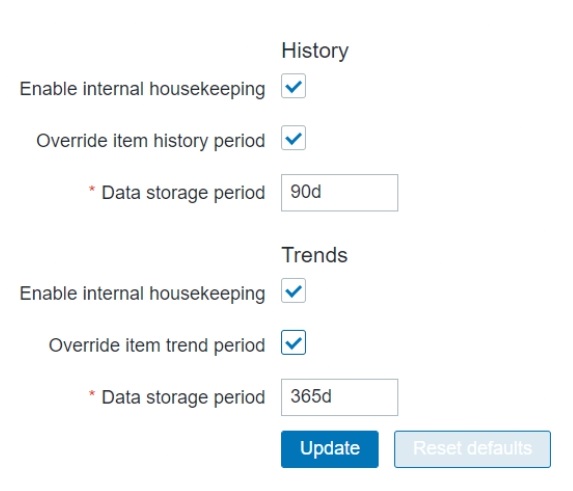
What is the greatest benefit of native partitioning? Normally, history tables are not partitioned. Zabbix ordinarily uses an internal single-threaded process — Housekeeper — which is responsible for deleting data older than what we specify in the Frontend. For instance, if we specify that we need to keep history for 90 days and trends for a year, the Housekeeper will delete data older than that.
The problem is that if we have an enterprise-scale instance of Zabbix, then we could have terabytes of data. Most of that will betaken by our history tables. Housekeeper just runs delete statements on history and trends data. Since those are really big, we’ll be just checking the clock value of the historical data, so this will take a lot of time. As you can see, the history tables are the busiest tables in the Zabbix Database, and we definitely don’t want to lock them with a Housekeeper process running for 20-30 minutes or even more than one hour just to delete all the data that we don’t want to store.
So, the greatest benefit of partitioning is that you partition history tables based on days and then you just drop a whole partition that you don’t want to keep anymore. This is a lot faster and has a much smaller performance impact than deleting the data via native housekeeping functionality.
TimescaleDB is not the only solution. But all other solutions are based on third-party scripts or some internal procedures. That’s additional administration overhead, and you need to make sure that the script will be executed and all the dependencies for the script will be working. With TimescaleDB, we can have this as a native functionality without any third-party scripts and any dependencies.
Native compression
- We have to remember the terabytes of stored data and the performance impact it can have. To have good performance, we need to have good storage. In enterprise monitoring, we will most likely have all the data stored in disk arrays. So we can just calculate how much money will be spent on disks to support a multi-terabyte database and, for instance, 50,000 new values per second coming from Zabbix.
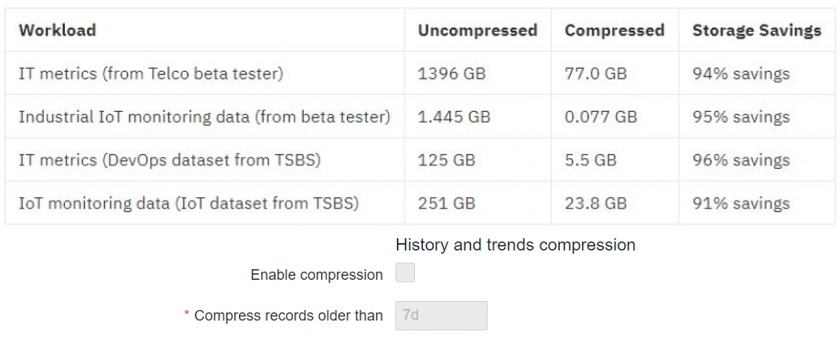
So the native compression in TimescaleDB lets us compress the heaviest tables inside Zabbix, such as history and trends. The most common question is how much disk space this will save us. In the use-case example below, the 1.396-TB Telco database was compressed to 77 GB of the data, which means up to 90 % of disk space saved.
- The limitation of compression is that you can’t modify compressed chunks. This means that we cannot edit, delete, or insert new data if it’s already compressed. But this is nothing to worry about. Normally, native Zabbix functionality will not try to edit history data, which is already collected and stored in a database. That’s why we can easily use compression, as it will not affect any native functionality at all.
- You can’t change the schema for compressed tables either. But from Zabbix’s perspective, this is just a formal thing as we normally wouldn’t suggest doing any schema modifications anyway.
- Compression can be administered from the Zabbix Frontend.
TimescaleDB installation
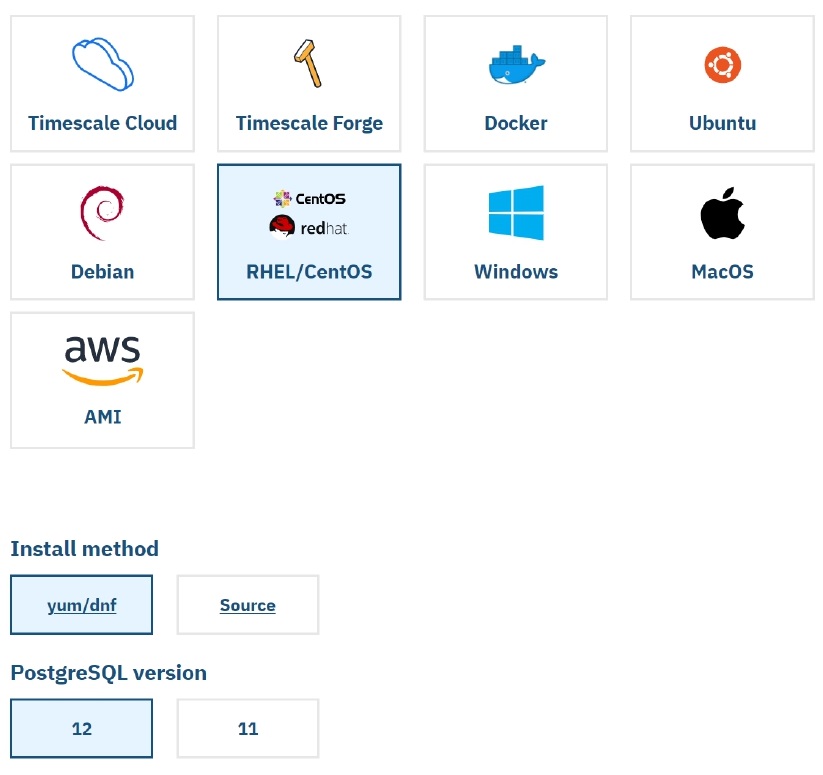
So how do we install TimescaleDB? It’s very easy, and all we have to do is open docs.timescale.com, choose where and how we want to install it (in our case, on Red Hat), choose the OS distribution, installation method, and PostgreSQL version. A couple of commands on top of that, and we’re good to go.
TimescaleDB configuration
To configure TimescaleDB, first we need to:
- Enable the TimescaleDB extension for the Zabbix Database as specified in the Zabbix documentation about the TimescaleDB configuration by executing:
echo "CREATE EXTENSION IF NOT EXISTS timescaledb CASCADE;" | sudo -u postgres psql zabbix
- Run the timescaledb.sql script located in database/postgresql by executing:
cat timescaledb.sql | sudo -u zabbix psql zabbix
The only thing you need to keep in mind is that if you already have a Postgres database and you’re planning to use TimescaleDB, or you have Oracle or MySQL and you plan to migrate to Postgres and use it with Timescale, you might already have a database hundreds of gigabytes or even terabytes in size.
So, the initial process of applying TimescaleDB to your database will definitely take some time. We recommend users to actually stop the Zabbix Server, the Frontend, schedule a maintenance period, and then let it run, reconfigure all the tables, do the compression, and only then start it and receive the metric backlog from all the proxies and the monitored hosts back to the database.
Conclusion
These are the basic steps to use PostgreSQL with TimescaleDB. If you are just starting out with Zabbix and thinking about what database to choose, PostgreSQL and TimescaleDB will be one of the best choices available to you. Our best-practice opinion is that you need to choose the database you are experienced with, since you will have to work with it. But TimescaleDB’s compression and native partitioning really give a huge advantage against all other supported database backends.
Questions & Answers
Question. Schema changes for compressed tables are not allowed, so how do we proceed with an upgrade in that case?
Answer: I think that it might cause some problems. The good thing is the last schema change on the history and the trends table, if I remember correctly, was in version 3.2. So that’s something to keep in mind. However, since TimescaleDB is fully supported by Zabbix, I guess that if we know that the next major release will have affect the history or trends tables, then there will definitely be a solution.
In addition, you can decompress the tables, upgrade, and compress them again, though this is not the best approach in terms of time-saving.
Question. Is Timescale the only option for people who want to go with some sort of compression?
Answer: Currently, yes, if we’re talking about native compression, which is also supported in Zabbix. With Timescale, the configuration, enabling, and disabling compression, and other procedures must be actually performed on the table. So there must be a procedure, which is executed to compress it. Currently, with the TimescaleDB, this is done with the good old Housekeeper process, which is a native process integrated with Zabbix itself. So, there’s nothing besides Timescale DB that would work so great with Zabbix at the moment.
Question. How do we install our database into a non-default schema?
Answer. If you have a different schema in Postgres, there is a specific parameter in the server configuration file for it. I think it was also in the frontend wizard where you just specify which schema you want to use.
Question. Which user on the machine will be used to access configuration files for permissions?
Answer. It is a general question about permissions and configuration files. However, in the case of Zabbix, we can use Zabbix User. It’s possible to change it, but that might not be the best practice in terms of Postgres. I guess, after a default installation of Postgres, there will be a user ‘Postgres’ that will have an access to the configuration file. Zabbix works only with the Zabbix configuration file, while Postgres — only with the Postgres configuration file, so we don’t need to have them cross-related to one another.
Question. Do we provide or do we have plans to provide a script or a tool to migrate Zabbix 4.0 or 5.0 with MySQL to Timescale?
Answer: Initially, you need to migrate to Postgres and then apply Timescale on top of that. We don’t have any official scripts or utilities to do the migration. If you’re really interested, it’s actually not as complicated as it may seem at first sight, and you can do it by watching my video, for instance.
There is a native Postgres utility to import the data which has been exported from MySQL with MariaDB. In this case, you need to make sure that you only import the data, and apply the constraints only after the data is imported.
The most important thing is that you should have proper data integrity from the beginning. If you have some constraint breaches in your MySQL instance, then you will encounter issues trying to import it and upload it to the Postgres database. But it’s still not a disaster, it can be fixed though it might be a challenge at first.
If the data integrity is fine, then it’s a pretty straightforward process, though this depends on the size of the database. But if we exclude the history, then it takes like a couple of minutes if you know what to do.
Question. So, you mentioned those constraint breaches, maybe just some issues with integrity. Could you tell us when and why those could happen?
Answer. The most popular opinion about why those breaches could happen is doing something manually, for instance, editing the database schema. I mentioned that we don’t really like it when users do that. But I still do believe that there are some installations that have been working with Zabbix since 1.x, and they have upgraded to 5.2 across all of these years.
It’s really possible that in some older versions there was some bug that affected this database integrity and it was fixed later on. Or partitioning was not that easy. You couldn’t just turn it on, you actually had to drop some indexes, edit the tables, and do other stuff that we do not recommend.
Question. What if we have different history settings for different items?
Answer. That’s a limitation that does not apply only to TimescaleDB, but also to any currently used partitioning solution, at least with Zabbix. There is a functionality within the Zabbix Frontend where you can define that data for a certain item should be kept for two years, for instance, as it is extremely important, while data for some other item just collecting hostname should be kept only for one month.
If you choose the partitioning path, then this functionality disappears and you must check the Override item storage period box in the Housekeeper settings, and all of your items will be stored for the period that you specify in the Housekeeper settings page.
Question. What are the performance advantages of using PostgreSQL with Timescale over PostgreSQL with native partitioning or MySQL with custom partitioning approach.
Answer: In general, talking about performance benefits is about database engines without partitioning and compression. You would not say that one is specifically better than the other. It is always a question of the users’ knowledge and ability to tune and configure the database properly.
We still frequently see database servers that have 500 GB of memory and the default config file. If we check the server statistics, we’ll see that out of 500 GB only 1 GB is used simply because they did not edit the config file. That’s why we are sure that you should choose the database you are experienced with, since you will have to tune it and ensure that is the DB health and performance is up to par.
In terms of partitioning benefits, the greatest benefit of TimescaleDB comes from compression and partitioning. A couple of years back, we had a semi-official partitioning script, which was based on triggers in Postgres. That particular solution was not working very well with very big Zabbix installations just because of the trigger mechanism on the tables.
The existing one with TimescaleDB is based on Housekeeper, which executes the partitioning procedure once per day. In addition, there is the current MySQL solution with a third-party script. I think that their performance is the same, and I do not see any particular difference. However, Timescale offers compression, and there is definitely a difference working with 50 GB database versus 1 TB, no doubt about it.





Question: which versions of the timescaleDB extension are supported by which versions of zabbix? I can’t find a support matrix …..
In order to check the Zabbix and PostgreSQL/TimescaleDB compatibility, you can always refer to the “Requirements” section in the official documentation. Here is such a section for Zabbix 6.0: https://www.zabbix.com/documentation/current/en/manual/installation/requirements#database-management-system
PostgreSQL 13.0 – 14.X and TimescaleDB 2.0.1-2.3 are fully tested and supported. In case the version of the TimescaleDB you plan to use is not listed – it does not mean it would not work, it only means that it was not fully tested with Zabbix.