




Build a scalable and highly available Zabbix monitoring system by scaling it on database level with MySQL InnoDB cluster. It guarantees data consistency and automated conflict resolution, automated failover, and self-healing.
Watch the video now.
Contents
1. Introduction (4:16:52)
2. High availability with MySQL InnoDB cluster
2.1. Yesterday: asynchronous replication (4:19:53)
2. Today: MySQL InnoDB Cluster (4:21:42)
3. MySQL Group Replication (4:26:09)
3.1. Architecture (4:25:13)
3.2. Single-primary mode (4:26:37)
3.3. Multi-primary mode (4:27:14)
3.4. Major building blocks (4:27:46)
3.5. Life cycle of a transaction (4:28:42)
3.6. Performance comparison (4:29:23)
4. Zabbix HA deployment with MySQL InnoDB cluster (4:30:16)
Introduction
In this post I will talk about scaling Zabbix with InnoDB cluster. I will explain what InnoDB cluster is and how it can serve Zabbix in achieving scalability.
100% of organizations want their critical systems to be highly available. And what can be more critical than monitoring? Monitoring systems allow us to see what is wrong and what could be better, so they potentially can save us a lot of money.
Let’s start with the question — does Zabbix need to be highly available? Yes, indeed, because if your monitoring system goes down, you are left blind — you no longer know what is going on in your infrastructure. And there is no scarier feeling than being blind and totally in the dark.
There are two ways of achieving high availability — on the application server level and on the database level.
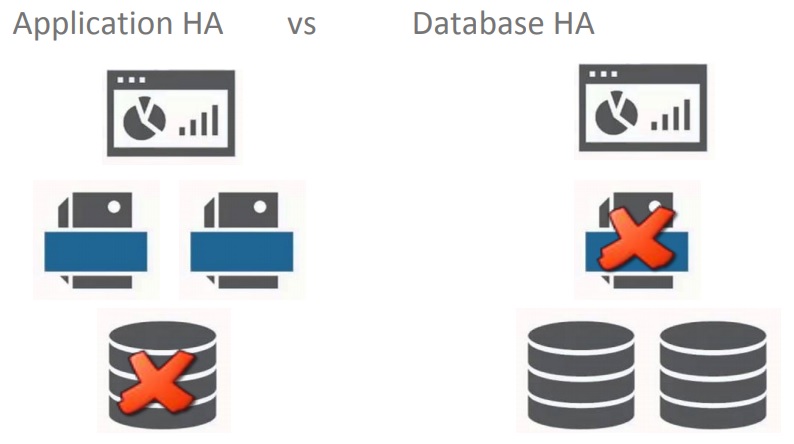
Application and database levels
I will cover high availability at the database level because I’m an expert in databases, MySQL in particular. MySQL is the #1 open-source database utilized by many successful companies, such as Airbnb, Dell, Facebook, and, of course, Zabbix.
High Availability with MySQL InnoDB cluster
Yesterday: asynchronous replication
In the beginning, there was asynchronous replication. It requires a master server and one or more slaves which are mostly used to scale out the reads. I will not talk much about this technology because it is well-known and wide-spread. 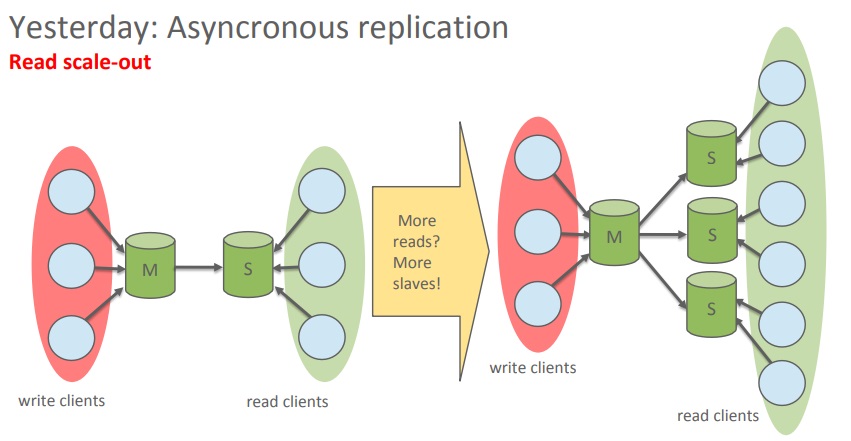
Asynchronous replication
However, asynchronous replication has some limitations. It does not perform failover and does not resolve conflicts automatically. So asynchronous replication has a habit of breaking quite often.
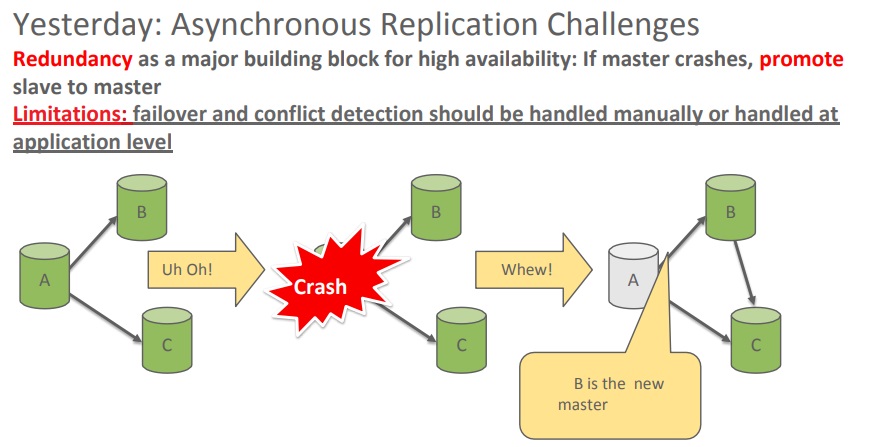
Asynchronous replication challenges
If the master goes down, unless the connection is rerouted, the database system will not react on its own. This is also true for multi-master configuration when there are conflicting routes on the database. Unless an application or a person makes a decision, the database system does nothing apart from ending up in a split-brain scenario.
This is exactly why InnoDB cluster was introduced in MySQL 5.7.
Today: MySQL InnoDB cluster
InnoDB cluster is a clusterization system that addresses these challenges. It is composed of three main parts — Group Replication (GR), MySQL Shell, and MySQL Router.
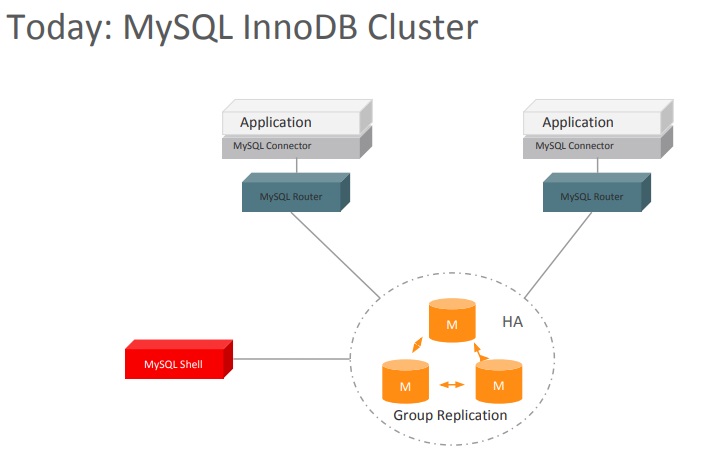
InnoDB cluster components
Let’s look at these components one by one.
MySQL Router is lightweight middleware that is used to route connections between the application and back-end MySQL Servers. It provides native support for MySQL InnoDB clusters as it:
- understands GR topology;
- utilizes metadata stored on each member;
- bootstraps itself and sets up client routing for the GR cluster;
- allows for intelligent client routing into the GR cluster;
- supports multi-master and single-primary modes.
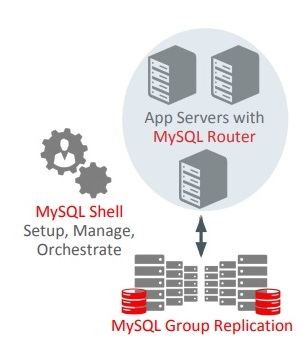
InnoDB cluster architecture
As you can see, MySQL Router stands between application servers and the GR setup. It makes the cluster transparent for the application. The application believes it is talking to a single MySQL server, when in fact there is a full-blown cluster under the hood.
It goes without saying that MySQL Router is not a single point of failure because it can be deployed in parallel. Each router is a passive component that is not aware of the other ones and functions independently.
MySQL Shell is used for configuring InnoDB Cluster. It is an advanced command-line client and code editor for the MySQL Server which supports development and administration for the MySQL Server and can be used to perform data queries and updates as well as administrative operations.
MySQL Shell features:
- interactive multi-language interface (JavaScript, Python, SQL);
- naturally scriptable (with development and administrative APIs);
- both interactive and batch operations;
- three-step automatic deployment of the cluster setup;
- full AdminAPI exposure for managing InnoDB Cluster (creating, configuring, modifying, validating, monitoring and scripting).
Last but not least, there is Group Replication. GR is a semi-synchronous replication topology with built-in automated distributed recovery, conflict handling, group membership, and distributed agreement, which, in fact, means automatic failover.
Group Replication eliminates the need for dealing with failover. Previously, either an application or an administrator had to take the lead and decide which slave to route the connection to if the master was failing. But GR allows for more free time for developers as they do not have to code annoying failover logic and it allows administrators to focus on what is really important. Also, it provides fault tolerance, automatic distributed coordination, and update setups.
MySQL Group Replication
Group Replication is an in-house product from MySQL developers. It is based on replicated database state machines and the Paxos algorithm. I am often asked what kind of implementation has been chosen. The answer is none, it has been reimplemented in-house.
Architecture
So, the architecture comprises MySQL Routers and the Replication Group.
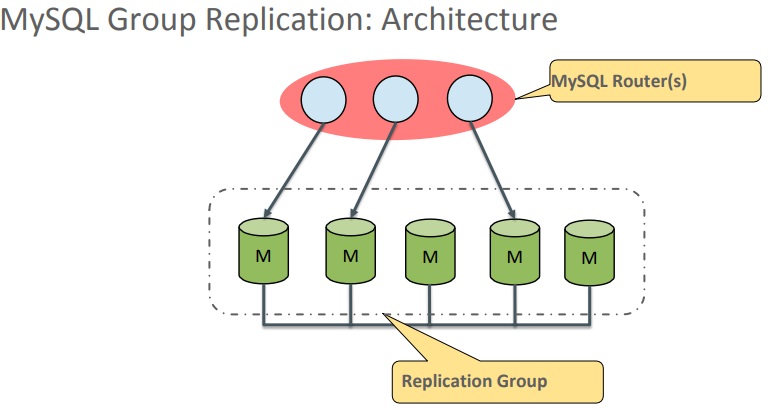
MySQL GR Architecture
MySQL Routers route connections into the group of master servers. The master servers can work in 2 modes:
- Single-primary mode (writes are allowed only on one server, the other servers are in enforced read-only mode);
- Multi-primary mode (reads and writes allowed on any server).
Single-primary mode
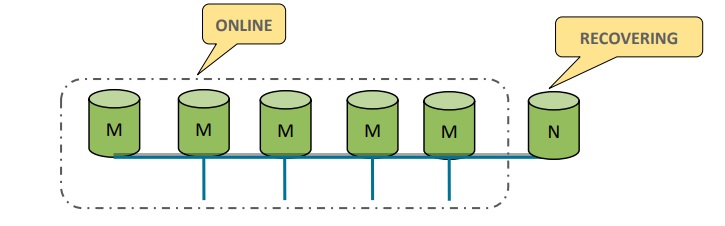
If a problem occurs in the single-primary mode, a failover takes place. In a matter of seconds, the application will slow down and then another server from the group will be chosen to act as the primary.
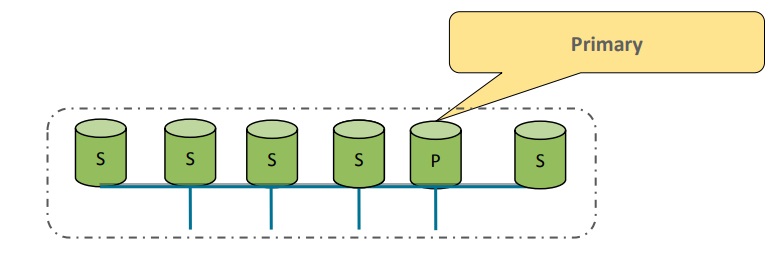
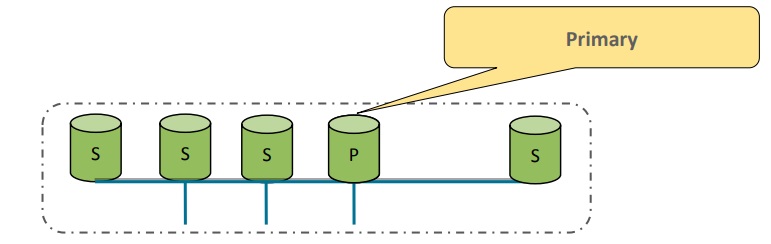
Failover in the single-primary mode
Before being accepted back into the group, the original server will receive the missing transactions in the form of binary logs from the rest of the group.
Automatic distributed recovery
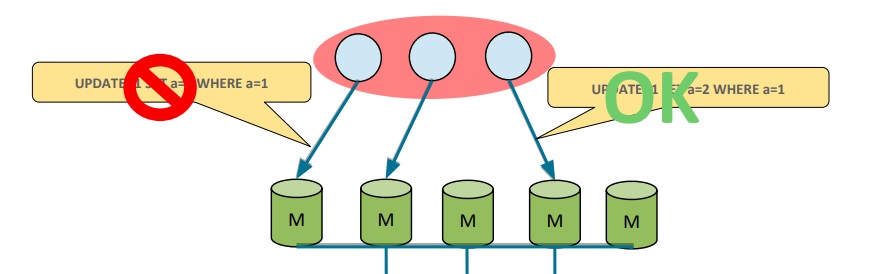
Multi-primary mode
In the multi-primary mode, any two transactions on different servers can write to the same tuple. Conflicts will be detected and dealt with. The rule is that the first committer wins. This is not based on time, but rather on the synchronized versions of writesets across the group.
Major building blocks
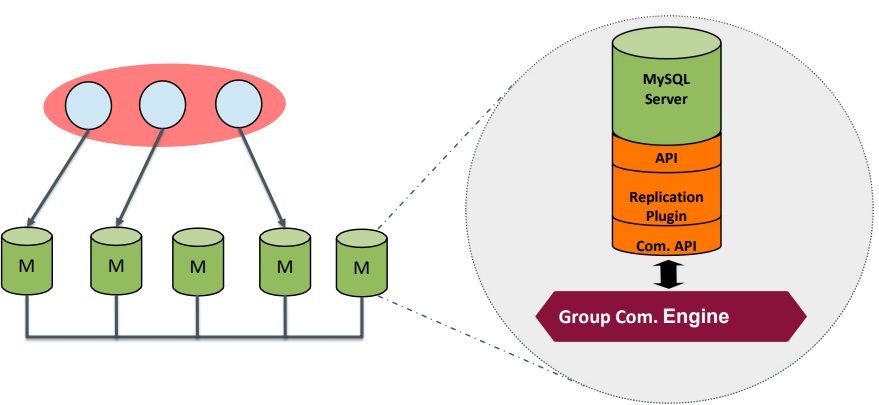
The GR building blocks consist of two API components and a replication plugin.
On the one hand, API components are used to communicate with the MySQL server runtime component so the MySQL server does not have to hook directly into the Group Replication. This helps to keep the plug independent and the code beautiful.
On the other hand, they are used to communicate with the other nodes via the so-called group communication engine which is composed of all the communication APIs — this is where the communication really happens.
The replication plugin is what handles the replication itself — it writes to binary logs and reads from relay logs.
Group Replication building blocks
Life cycle of a transaction
Below you can see the life cycle of a transaction.
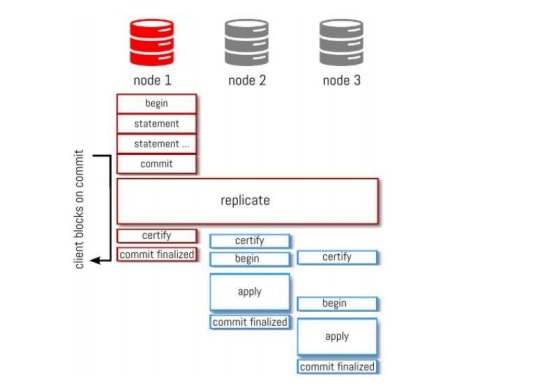
Full transaction life cycle
Node 1 gets a transaction with all middle stages (begin, statement, commit). The replication starts when another node certifies the transaction, meaning that it writes the transaction to the binary logs. All the members of the group are informed about this event. Then, node 1 finalizes the commit and sends the response back. This is done for ensuring data integrity.
Performance comparison
This performance test of MySQL 5.7 Group Replication was done in-house by our product management and development team.
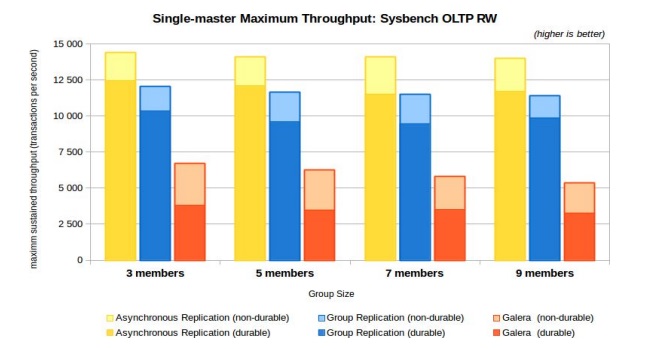
Performance test results
Note. Go here to read about how the test was carried out. It was performed both with and without durability settings.
According to the results, Group Replication is just a bit slower than asynchronous replication — for obvious reasons. But it is way faster than competing products.
Zabbix HA deployment with MySQL InnoDB cluster
There are some requirements for InnoDB cluster:
- InnoDB storage engine;
- primary key/unique non-null key on every table;
- global transaction identifiers turned on.
InnoDB cluster does not support:
- concurrent DDL statements;
- SERIALIZABLE transaction isolation mode;
- Cascaded Foreign Keys.
Note. These components are not supported by the Zabbix database, so they are not required.
As for the hardware and infrastructure, InnoDB Cluster requires:
- 3, 5, 7 or max. 9 machines per group;
- machine resources isolated as much as possible;
- limited virtualization layers;
- machines configured for dedicated database server role:
- recommended configuration — 32-64 vCPUs with fast CPU clock (2.5GHz+), SSDs (for data and replication logs);
- high-quality network connection between each machine:
- low latency, high throughput;
- routers and hubs limited as much as possible;
- isolated and dedicated network when possible.
InnoDB Cluster runs on commodity hardware and every server keeps an identical copy of the data.
Let’s look into what is needed for the deployment of MySQL InnoDB cluster (3 nodes, MySQL Router on each application server).
Deployment includes the following steps:
- Install Zabbix;
- Set up or clone the database instances;
- Create an InnoDB cluster (add primary keys where needed);
- Add a MySQL Router;
- Create a Zabbix database;
- Point the application to the router;
- Configure the database connection.
Note. For more information on MySQL InnoDB cluster, go to the documentation.
See also: Presentation slides





Zabbix 6.4.2 DOES use cascading foreign keys. It is no longer compatible with Innodb Cluster.
Almost with versions 7.0 Zbx + 8.4 MySQL, may some errors occurs when using Zabbix Server + MySQL Router R/W Split, found this forum thread about this.
Zabbix with MySQL InnoDB Cluster Read/Write Splittinghttps://www.zabbix.com/forum/zabbix-help/503952-zabbix-with-mysql-innodb-cluster-read-write-splitting?view=thread