




Learn how Deutsche Telekom Technik GmbH integrated Zabbix server instances into the existing IBM Netcool ticket system to reuse the entire existing infrastructure and attached business processes and work with alerts created by Zabbix.
Watch the video now.
Contents
- Introduction (00:00)
- Challenges (01:43)
- Integration of Zabbix and IBM Netcool (07:00)
- Implementation (13:06)
Introduction
I would like to share with you the details of the project I worked on together with Deutsche Telekom Technik GmbH. Deutsche Telekom operates multiple Zabbix servers, and one of the key questions was how to integrate them into the existing notification infrastructure. I think anyone who has dealt with integration into bigger environments and larger companies has faced the same issue. It also was the main challenge of Deutsche Telekom’s project, but we succeeded and I will explain how we did it.
Challenges
Let’s start with some simple things. A Zabbix server monitors various systems and if a problem is detected Zabbix will perform incident processing.

Incident management with Zabbix
Zabbix incident processing can be in multiple ways: notification, incident reporting (e.g. ticket system integration), script execution, and escalation.
 Incident processing options
Incident processing options
Bigger environments can have not just one, but multiple monitoring systems which do exactly the same — they detect problems and process incidents. There also can be special monitoring systems for specific applications, for instance, if a vendor insists on installing specific monitoring and controlling software. Still, at the end of the day, the work is always performed nearly in the same way: problem detection is followed by incident processing.

Incident management with different systems
There are many overlapping functions if multiple monitoring systems send notifications or perform actions simultaneously.

Incident processing
Another possible scenario is when some of the systems only send notifications, and some only execute scripts on remote access.

Deutsche Telekom has different vendors, applications, network components, and server systems. Of course, the company does not have a single monitoring system, and the question we had to answer was how to manage incidents across different monitoring systems.
Some ideas will be explained below, and one of them was to make Zabbix ask one monitoring system to take care of the existing monitoring systems.

The next option entails full migration to Zabbix with Zabbix becoming the so-called ‘umbrella monitoring system’. To do it, all the alerts from the monitoring system should be moved to Zabbix step by step. This strategy might suit some companies, but Deutsche Telekom did not want Zabbix to be the central point.

The last option is very common. There is the central incident processing system along with Zabbix and other monitoring systems, and all of them do a part of the central incident processing on which rules and decisions of the escalation process are based.

The next challenge was to manage more than one Zabbix server instance.

Zabbix instances
This is one set of servers in one environment section. The problem is that each Zabbix server instance must have a unique hostname, and there might be the same hostnames across multiple Zabbix servers.
We needed to make sure that we could deal with multiple instances at the same time. Thus the central incident processing approach was chosen. It allowed us to build two Zabbix instances as two different systems easily.

Integration of Zabbix and IBM Netcool
How can integration with a central incident processing system be performed? For this project, the answer was to use SNMP traps.
For me as a software developer, the first option was API programming, which is always used for integration. But Deutsche Telekom preferred using SNMP traps because the existing system already worked with them. At the end of this project, I could say it was the right choice to use SNMP traps, and I will explain why.
Why SNMP traps instead of custom API programming?
SNMP traps are specifically designed to monitor network components. They are defined by official RFCs, provide authentication and encryption, and supported by many vendors.

SNMP vs. SNMP traps
Note. What is the difference between SNMP and SNMP traps? SNMP lets you ask a device to provide information (SNMP queries or SNMP pollers). SNMP traps are event-driven. The device sends a message when something happens.
After the decision is taken to use a central system and SNMP traps, the challenge now is to implement design during the integration of Zabbix with IBM Netcool.

We can use the entire existing infrastructure from Deutsche Telekom for alerting, escalation, notification, and automatic processing. All that is used is scalable and not limited by any single Zabbix instance. The well-defined interface on the IBM Netcool part is another benefit.
Our design considerations required passing the following to IBM Netcool:
- unique Zabbix instance names;
- hostnames;
- trigger identifiers and trigger severity;
- Zabbix eventid on entering ‘problem’ state;
- Zabbix eventid on entering ‘ok’ state to clear.
It is also important to control which event should be passed to IBM Netcool. Not any event on Zabbix should be automatically forwarded. Then, we need to implement heartbeat communication to let the IBM Netcool environment monitor the middleware. In other words, it helps avoid situations when the middleware is broken or doesn’t work any longer but no notifications are sent to the network operating center of Deutsche Telekom. The entire communication is based on SNMP v3 traps including encryption and authentication.

The red boxes are values from Zabbix and the blue ones are the attributes that should be set on IBM Netcool. For example, there is tmIdentifier (1) and tmIdentifier (2) because the Zabbix instance name is used as a constant. Together with a trigger identifier, they build a unique tmIdentifier on the IBM Netcool side, and this information is passed by SNMP traps, which results in unique identification. Trigger tags are used, available in Zabbix, to pass on the unique information that should be on the IBM Netcool side. Macros can also be used, which makes the design very flexible.
Implementation
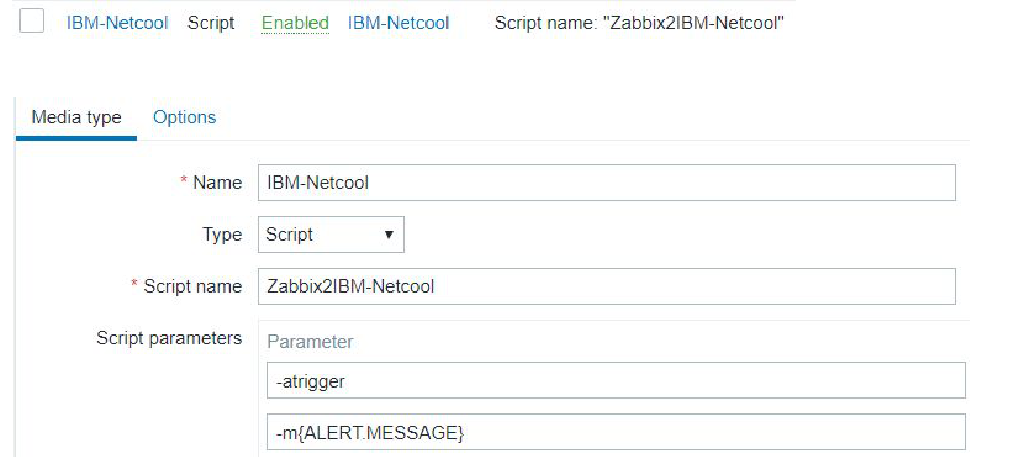
Netcool user media
The picture above shows very simple user media. It is a script running our middleware with such configuration parameters as −atrigger and −m{ALERT:MESSAGE}. A means an action attribute that can be implemented using heartbeat or initiated by a trigger. And the second parameter means a message is passed on to the alert system to forward information.
Below you can see the XML payload from the trigger action. There is a wrapper with an XML envelope that wraps all the parameters based on constants, macros, and attributes created during an event on Zabbix. All these parameters in the big envelope are passed over to the middleware and create the trap.

Trigger action
This is a very basic trigger definition. To enable a Zabbix trigger to be communicated on the IBM Netcool, all you need to do is to define a trigger tag for IBM Netcool and give it an ID — that’s it.

Trigger tag settings
The resulting SNMP trap from the middleware will look like this:

SNMP trap
The tmIdentifier reads zbxsrv-se-015_726, with zbx standing for the Zabbix server and se for internal information, Zabbix server name, and information about where the identifier has been built. You will also find configuration item ID, network component number, and other parameters.
Using this technique, issues can be opened and cleared by standard SNMP traps. If the problem is gone on Zabbix, the ‘clear event’ message can be sent, and the issue will be cleared on IBM Netcool.
See what it looks like on IBM Netcool below:

Final result on IBM Netcool
It’s simply a dashboard where you see alerts, heartbeat messages, and alarms. If you click one of the entries on IBM Netcool the pop-up window will show all the detailed information forwarded from Zabbix.

Pop-up window
See also: Presentation slides






Thanks for your article! Can you please show script Zabbix2IBM-Netcool?