




Solution for replicating monitoring data between Zabbix servers in a multi-tenant environment motivated by the need to have different third-party integrations in different environments.
Watch the presentation video.
Contents
Introduction
sysfive.com is currently implementing a project that involves integrating multiple Zabbix servers in a multi-tenant environment, which is what I’m going to talk about.
sysfive.com is a small company with less than 20 staff. Not long ago, we took on a project for a huge logistics company with its own IT department. This IT department takes care of areas like developing and operating their own business software, and we are supporting them only with certain services.
sysfive.com provides:
- log monitoring (Elastic Stack);
- application monitoring (Zabbix);
- application server (third-level-support).
This is a very specific set of tasks, which results in some conflicts with our usual workflow. Typically, we would provide full platform operation, sometimes from bare metal or cloud down to application servers or applications themselves, monitoring by Zabbix included. sysfive.com has a centralized monitoring system for all customers, with one dashboard for the Ops team. Our monitoring is integrated with other tools (ticket system, etc.) that help us operate smoothly.
But for this project, we have a very specific selection of services. We will provide monitoring as a service for other teams. The customer also requires having their own Zabbix server in their environment, which enables them to operate without our help, if necessary. This, of course, is not how we usually work so we set out to find a solution to this problem.
Problem
This is an overview of our hard infrastructure, which is more or less the same for all our customers.
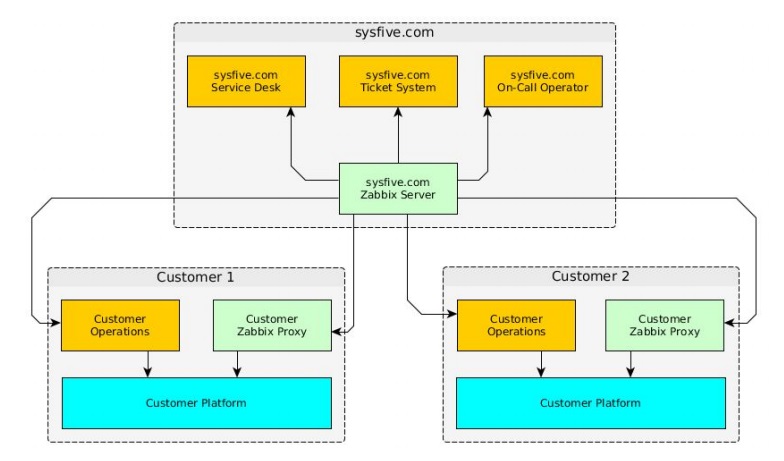 sysfive.com infrastructure (so far)
sysfive.com infrastructure (so far)
There is a Zabbix server integrated into the ticket system that sends notifications to the service desk and our on-call operators when we provide 24/7 support. In the customer’s environment, there are the customer’s systems (databases, application servers, etc.) and a Zabbix proxy that sends data to our Zabbix server. We get notifications from our Zabbix server when problems with application contents occur.
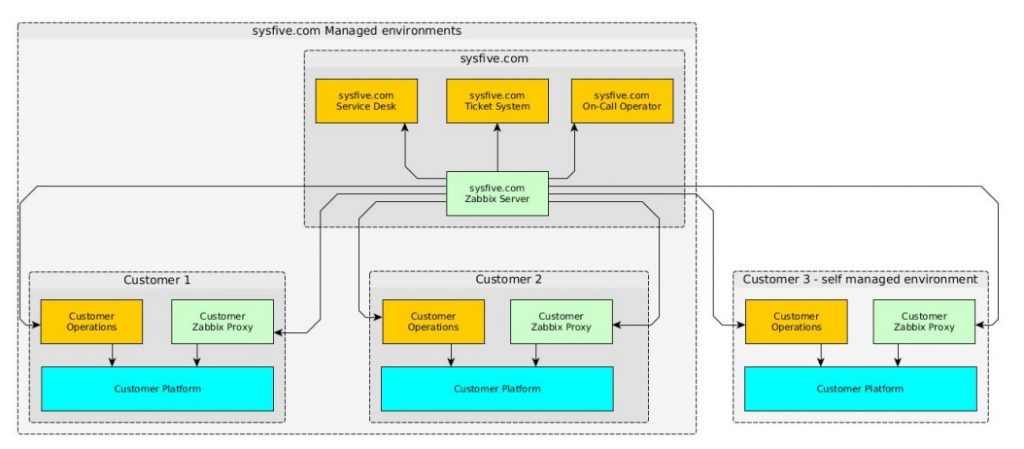
Expansion (rejected)
Obviously, we would like to expand in just the same way so that a new customer can operate the environment without us. But this variant was rejected because the customer wanted a Zabbix server in their self-managed environment.
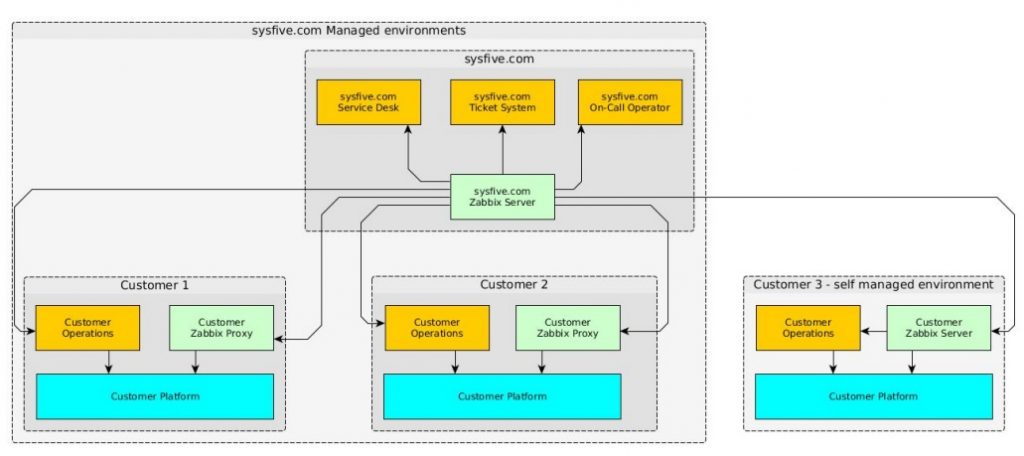
Expansion with replication
We had to find a way to receive all the data that we need to work, so we turned to replication. You can see our solution in the picture above. Basically, we decided to replace the proxy in the customer’s environment with another server.
Solution
Server-to-server replication
Our Zabbix server is the receiver, and the customer’s Zabbix server is the sender. We also have to take into account that only limited access rights are acceptable (read-only through the firewall).
All data and necessary configurations need to be replicated, but we are going to replicate only specific hosts for which we are responsible (Elasticsearch, Zabbix, supported application servers). Also, only item and trigger configurations are replicated because we already know the configuration on the receiving Zabbix server and we don’t need any templates from the customer’s Zabbix server, just the items.
It was decided to introduce a light-weight replicator that would run on our server and connect to the customer’s server. Python was used to write scripts.
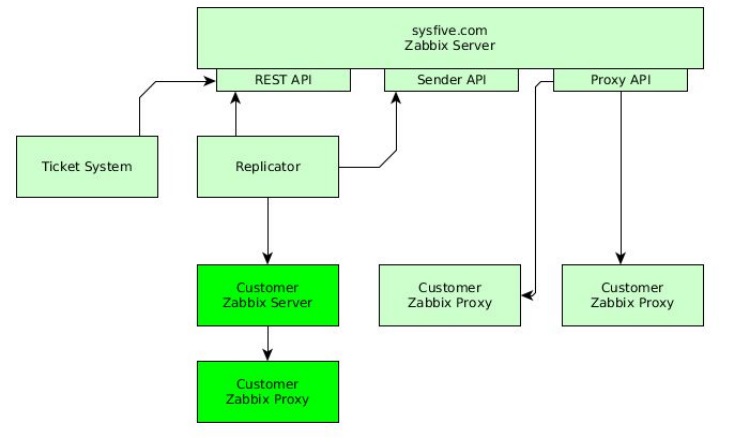
Solution
There are three API accesses to the Zabbix server:
- REST API;
- Sender API;
- Proxy API.
REST API is used by our ticket system to perform updates, to attach comments to tickets, to provide a view of any issues to customers with access, etc. Our replicator connects to our customer’s Zabbix server that, in turn, connects to the attached Zabbix Proxy. REST API is used to replicate item and trigger configurations, and Sender API is used for the data replication here.
Technical description
This solution is implemented with a Python script based on the PyZabbix module using a simple configuration file for connections and hosts. We can automatically replicate the hosts, configurations or data that we want.
Only one interface is used on the data source, which is Zabbix REST API with read-only rights. On the receiver, REST API is used for configuration and Sender API is used for data monitoring.
Using this, we need to perform automated conversion and creation, i.e. all items from the customer’s server, which are different types, become trapper items on the replication target so we can put data there with Zabbix Sender API. We also add another replication monitor item per host and trigger to make sure replication works.
The script can run as a cron job. We made sure to prevent overrunning because it takes time to get all items and triggers from the source server and replicate them on the target server. It can automatically detect which host has to be replicated because local ‘replica cache’ is used on the receiver to ensure efficient and fast replication with minimized API calls.
The script is available on GitHub.
Limitations
This is a quick solution and is still in implementation so there are some limitations:
- It does not run as a continuous service.
- It currently does not support the replication of applications, templates, etc. (but it can be fixed easily).
- It does not automatically detect changing configurations, e.g. if an item is added, due to runtime considerations.
Demonstration
The production system is not yet implemented, so there is no real data available. For the test setup, our company’s Zabbix server, which will be the receiver in the real project, was used as a source. The Vagrant Zabbix server was used as a target, and a set of 12 hosts was replicated.
Here are some screenshots from the test setup to demonstrate the initial replication and the performance impact it has on the Zabbix servers.

Empty Target
This is how a fresh Zabbix server looks. There is nothing on it, just a default Zabbix server host which is always disabled.
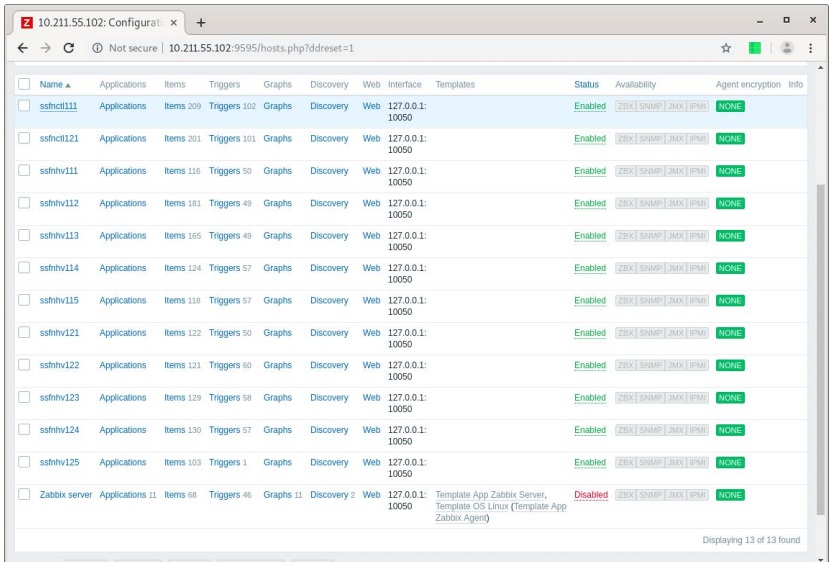
5min initial replication
Then the replication script was started. After it ran for several minutes, it returned information about a number of hosts which all received all items and triggers (except for the last one). The interface does not matter because all items have been converted into trapper items.
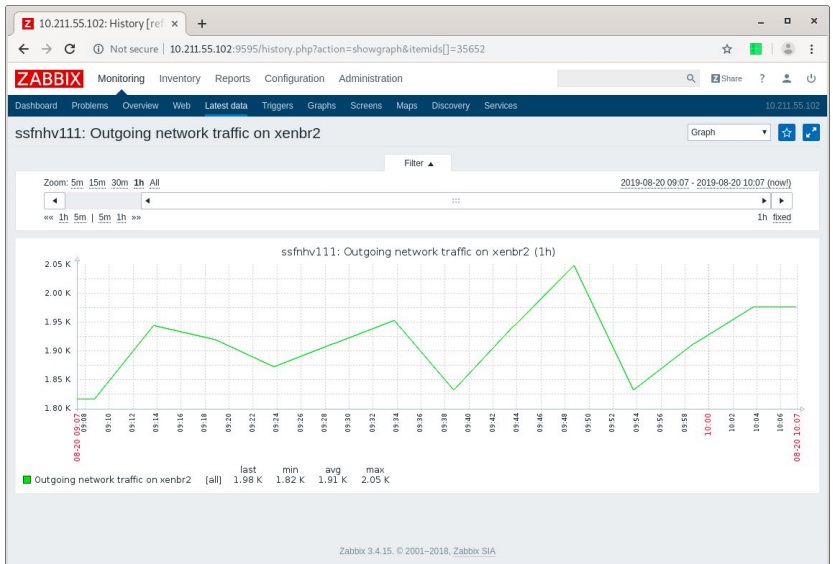
1h history per item
We replicated only the last hour of data in the beginning, because this way when we already have one hour of data for each item and the initial application, we don’t get overwhelmed with the triggers that would fire if data was missing. So we make sure we have data first and then replicate the triggers for the hosts.
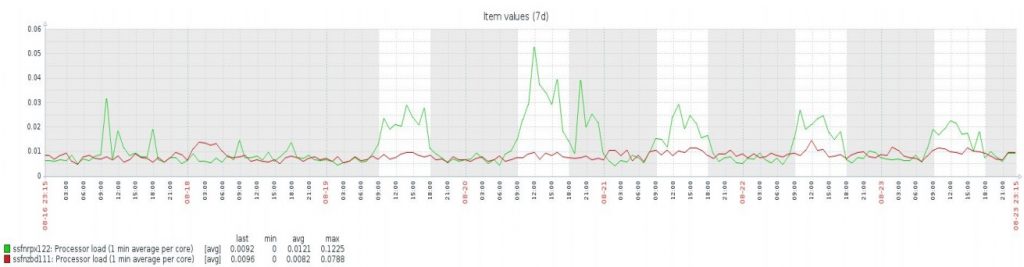
Source server baseline
This is the actual performance testing that was executed very late in the evening. You can see when people are working throughout one week. The green line shows CPU load from our Zabbix front-end server and the red line shows data from our database server. There is no real activity on the weekend, but during the weekdays Zabbix dashboard was probably open in the background in every browser.
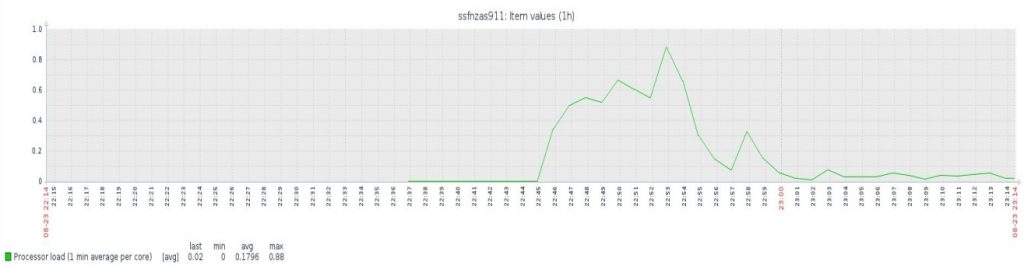
Target server load
This is how it looked on the target Vagrant virtual machine. When we start the virtual replication we have a high load at the beginning because it goes through all the hosts, the whole API, taking all items and triggers. The initial data replication takes some time but then it settles to an acceptable low load. This is really not much effort for that VM and the impact is low.
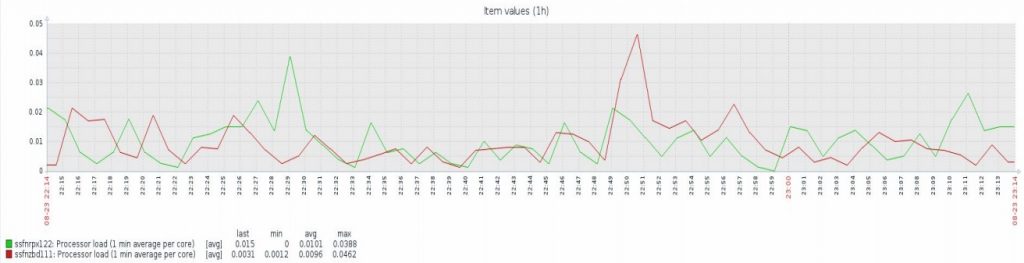
Source server load
It is similar on the source server. The database server load is mostly caused by the initial data replication, but it then goes back to the level it had before. It is a very small impact for this amount of hosts on the source server.
To sum it up, there is a very high load on the target and also a significant load on the source server during the initial replication. This is also the reason why we chose not to do the automated detection of configuration changes. But when this replication is ongoing, the load is quite low, at least for this number of hosts. Since this load scales per host, this solution might not be suitable for large-scale deployments, but for a project with two or three dozens of servers to replicate, the performance impact is comparable to the load impact of one or two users opening the Zabbix dashboard.
Conclusion
This solution has the following benefits:
- one central dashboard;
- full workflow integration;
- one central user/notification setup;
- shared data ownership;
- all notifications working.
See also: Presentation slides





